|
软件平台:Ubuntu 14.04
容器有效地将由单个操作系统管理的资源划分到孤立的组中,以更好的在孤立的组之间有冲突的资源使用需求。与其他的虚拟化比较,这样既不需要指令级模拟,也不需要即时编译。容器可以在寒心CPU本地运行指令,而不需要任何专门的解释机制。此外半虚拟化和系统调用替换的复杂性。
LXC的实现是基于内核中的namespace和cgroup实现的。
namespace:
和C++中的namespace概念相似。在Linux操作系统中,系统资源如:进程、用户账户、文件系统、网络都是属于某个namespace。每个namespace下的资源对于其他的namespace资源是透明的,不可见的。因为在操作系统层上就会出现相同的pid的进程,多个相同uid的不同账号。
内核中的实现:
namespace是针对每一个进程而言的,所以在task_struct结构的定义中有一个指向nsproxy的指针
|
2 |
struct nsproxy *nsproxy; |
该结构体的定义如下:
|
02 |
* A structure to contain pointers to all per-process |
|
03 |
* namespaces - fs (mount), uts, network, sysvipc, etc. |
|
05 |
* The pid namespace is an exception -- it's accessed using |
|
06 |
* task_active_pid_ns. The pid namespace here is the |
|
07 |
* namespace that children will use. |
|
09 |
* 'count' is the number of tasks holding a reference. |
|
10 |
* The count for each namespace, then, will be the number |
|
11 |
* of nsproxies pointing to it, not the number of tasks. |
|
13 |
* The nsproxy is shared by tasks which share all namespaces. |
|
14 |
* As soon as a single namespace is cloned or unshared, the |
|
19 |
struct uts_namespace *uts_ns; |
|
20 |
struct ipc_namespace *ipc_ns; |
|
21 |
struct mnt_namespace *mnt_ns; |
|
22 |
struct pid_namespace *pid_ns_for_children; |
其中第一个属性count表示的是该命名空间被进程引用的次数。后面的几个分别是不同类型的命名空间。以pid_namespace为例。
其结构如下所示:
|
01 |
struct pid_namespace { |
|
02 |
struct kref kref;//引用计数 |
|
03 |
struct pidmap pidmap[PIDMAP_ENTRIES];//用于标记空闲的id号 |
|
05 |
int last_pid;//上一次分配的id号 |
|
06 |
unsigned int nr_hashed; |
|
07 |
struct task_struct *child_reaper;//相当于全局的init进程,用于对僵尸进程进行回收 |
|
08 |
struct kmem_cache *pid_cachep; |
|
09 |
unsigned int level;//namespace的层级 |
|
10 |
struct pid_namespace *parent;//上一级namespace指针 |
|
12 |
struct vfsmount *proc_mnt; |
|
13 |
struct dentry *proc_self; |
|
15 |
#ifdef CONFIG_BSD_PROCESS_ACCT |
|
16 |
struct bsd_acct_struct *bacct; |
|
18 |
struct user_namespace *user_ns; |
|
19 |
struct work_struct proc_work; |
|
22 |
int reboot; /* group exit code if this pidns was rebooted */ |
|
23 |
unsigned int proc_inum; |
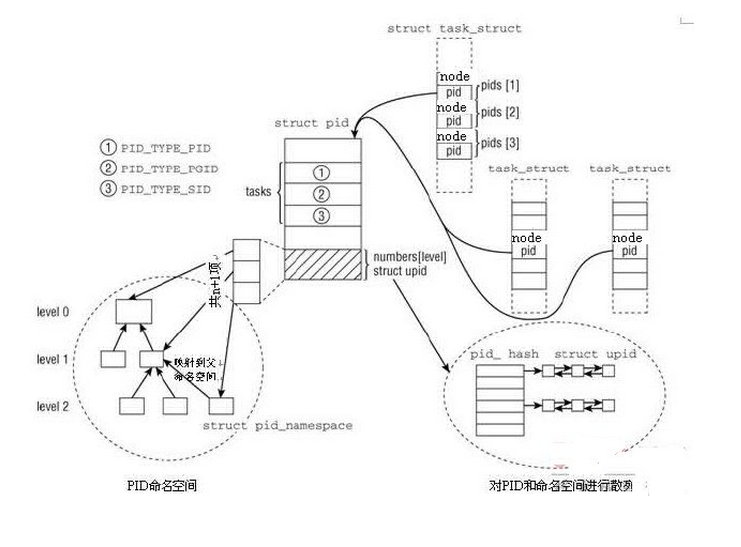
内核中的pid结构表示:
|
4 |
unsigned int level;//pid对应的级数 |
|
5 |
/* lists of tasks that use this pid */ |
|
6 |
struct hlist_head tasks[PIDTYPE_MAX];//一个pid可能对应多个task_struct |
|
8 |
struct upid numbers[1];//该结构是namespace中的具体的pid,从1到level各级别的namesapce,这里相当于一个指针,只不过不需要再分配空间 |
上面的结构体就是内核中进程的标示符,可以用于标识内核中的tasks、process groups和sessions。这个结构体和具体的task通过hash来关联,通过具体的task对应的pid的值可以获得绑定的pid结构体。
属于具体的namespace的pid结构upid:
|
2 |
/* Try to keep pid_chain in the same cacheline as nr for find_vpid */ |
|
4 |
struct pid_namespace *ns; |
|
5 |
struct hlist_node pid_chain; |
该结构体是用来获得结构体pid的具体的id,它只对特定的namespace可见。会通过函数find_pid_ns(int nr,pid_namespace *ns)函数来获得具体的PID结构。
整体结构如下图:
Cgroup:
Cgroup是control groups的缩写,是Linux内核提供的一种可以限制、记录、隔离进程组所使用的物理资源(CPU,内存,IO等等)的机制。Cgroup也是LXC位实现虚拟化所使用的资源管理的手段。可以说没有Cgroup就没有LXC,也就没有Docker。
Cgroup提供的功能:
-
限制进程组可以使用的资源数量。一单进程组使用的内存达到限额就会引发异常
-
控制进程组的优先级。可以使用cpu子系统为某个进程组分配特定的cpu share
-
记录进程组使用资源的数量
-
进程组隔离。eg.使用ns子系统可以使不同的进程组使用不同的namespace,已达到
-
进程组控制
Cgroup子系统:
-
blkio:设定输入输出限制
-
cpu:使用调度程序对CPU的Cgroup任务访问
-
cpuacct:自动生成Cgroup任务所使用的CPU报告
-
cpuset:为Cgroup中的任务分配独立的CPU(多核系统中)和内存节点
-
devices:允许或拒绝Cgroup中的任务访问设备
-
freezer:挂起或回复Cgroup中的任务
-
memory:Cgroup中任务使用内存的限制
-
net_cls:允许Linux流量控制程序识别从cgroup中生成的数据包
-
ns:命名空间子系统
Cgroup中的概念:
-
任务(Task):任务就是系统中的一个进程
-
控制族群(control group):一组按某种标准划分的进程,控制族群通常按照应用划分,即与某应用相关的一组进程,被划分位一个进程组(控制族群)。Cgroup中资源控制都是以控制族群为单位实现。一个进程可以加入某个控制族群,也可以从一个进程组迁移到另一个控制族群。
-
层级:控制族群可以组织成层级的形式–控制族群树。
-
子系统:资源控制器,比如CPU子系统就是控制CPU时间分配的一个控制器。子系统必须attach到一个层级上才能起作用,一个子系统附件到某个层级以后,这个层级上的所有控制族群都收到这个子系统的控制。
Cgroup使用控制CPU:
在Ubuntu中,cgroup默认挂载位置/sys/fs/cgroup目录。ls查看一下:
|
1 |
yan@yan-Z400:/sys/fs/cgroup$ ls |
|
2 |
blkio cpu cpuset freezer memory systemd |
|
3 |
cgmanager cpuacct devices hugetlb perf_event |
可以看到cgroup的不同子系统目录。
在CPU文件夹中新建一个geekcome目录,默认ubuntu已经将子系统全部挂载了:
进入cpu文件夹新建一个geekcome文件夹,然后查看:
|
1 |
yan@yan-Z400:/sys/fs/cgroup/cpu$ ls |
|
2 |
cgroup.clone_children cgroup.sane_behavior cpu.shares lxc tasks |
|
3 |
cgroup.event_control cpu.cfs_period_us cpu.stat notify_on_release |
|
4 |
cgroup.procs cpu.cfs_quota_us geekcome release_agent |
新建文件夹后在文件夹里会自动生成相应的文件:
|
02 |
├── cgroup.clone_children |
|
03 |
├── cgroup.event_control |
下面就跑一个死循环程序,导致CPU使用率到达100%。
|
1 |
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND |
|
2 |
5046 yan 20 0 25928 4848 2324 R 100.0 0.1 0:22.47 python |
现在执行如下的命令:
|
1 |
echo "50000" >/sys/fs/cgroup/cpu/geekcome/cpu.cfs_quota_us |
|
2 |
echo "5046" >/sys/fs/group/cpu/geekcome/tasks |
再top查看一下:
|
1 |
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND |
|
2 |
5046 yan 20 0 25928 4844 2324 R 49.8 0.1 0:49.27 python |
进程5046的cpu使用率从100%降低到50%。在Cgroup里,可以使用cpu.cfs_period_us和cpu.cfs.quota_ua来限制在单位时间里可以使用的cpu时间。这里cfs的含义是Completely Fair Scheduler(完全公平调度器)。cpu.cfs_period_us是时间周期,默认是100000(百毫秒)。cpu.cfs_quota_us是在这期间可以使用的cpu时间,默认-1(无限制)。
在上面的实例中,通过修改cpu.cfs_period_us文件,将百毫秒修改为一半,成功将CPU使用率降低到50%。cfs.quota_us文件主要对于多核的机器,当有n个核心时,一个控制组的进程最多能用到n倍的cpu时间。
Cgroup除了资源控制功能外,还有资源统计功能。云计算的按需计费可以通过它来实现。这里只实例CPU的控制,其他的子系统控制请自行实验。
LXC使用:
创建一个容器:
|
1 |
lxc-create -n name [-f config_file] [-t template] |
|
2 |
sudo lxc-create -n ubuntu01 -t ubuntu |
-n就是虚拟机的名字,-t是创建的模板,保存路径在/usr/lib/lxc/templates。模板就是一个脚本文件,执行一系列安装命令和配置(穿件容器的挂载文件系统,配置网络,安装必要软件,创建用户并设置密码等)。
显示已经创建的容器:
启动一个容器:
|
1 |
lxc-start -n name [-f config_file] [-s KEY=VAL] [command] |
启动一个容器,可以指定要执行的命令,如果没有指定,lxc-start会默认执行/sbin/init命令,启动这个容器。
关闭一个容器:
快速启动一个任务,任务执行完毕后删除容器:
|
1 |
lxc-execute -n name [-f config_file] [-s KEY=VAL ] [--] command |
它会按照配置文件执行lxc-create创建容器,如果没有指定的配置文件,则选择默认。该命令一般用于快速使用容器环境执行摸个任务,任务执行完毕后删除掉容器。
(责任编辑:IT) |