Linuxдʱ��������(copy-on-write)
���̼���������ģ���ʵ��ȫ���Կ���A��B�������̸�����һ�ݵ�����liba.so��libb.so����Ӧ�Ķ�̬��Ĵ���κ����ݶζ��Ǹ������̸�����һ�ݵġ� COW���������� ��Linux�����У�fork���������һ����������ȫ��ͬ���ӽ��̣����ӽ����ڴ˺���execϵͳ���ã�����Ч�ʿ��ǣ�linux��������“дʱ����“������Ҳ����ֻ�н��̿ռ�ĸ��ε�����Ҫ�����仯ʱ���ŻὫ�����̵����ݸ���һ�ݸ��ӽ��̡� ��ô�ӽ��̵������ռ�û�д��룬��ôȥȡָ��ִ��execϵͳ�����أ� ��fork֮��exec֮ǰ���������õ�����ͬ�������ռ䣨�ڴ��������ӽ��̵Ĵ���Ρ����ݶΡ���ջ����ָ���̵������ռ䣬Ҳ����˵�����ߵ�����ռ䲻ͬ�������Ӧ�������ռ���ͬһ���������ӽ������и�����Ӧ�ε���Ϊ����ʱ����Ϊ�ӽ�����Ӧ�Ķη��������ռ䣬���������Ϊexec���ں˻���ӽ��̵����ݶΡ���ջ�η�����Ӧ�������ռ䣨���������и��ԵĽ��̿ռ䣬����Ӱ�죩��������μ������������̵������ռ䣨���ߵĴ�����ȫ��ͬ�������������Ϊexec����������ִ�еĴ��벻ͬ���ӽ��̵Ĵ����Ҳ����䵥���������ռ䡣 �����Ͽ������и�ϸ��������ǣ�fork֮���ں˻�ͨ�����ӽ��̷��ڶ��е�ǰ�棬�����ӽ�����ִ�У����⸸����ִ�е���дʱ���ƣ������ӽ���ִ��execϵͳ���ã���������ĸ��ƶ����Ч�ʵ��½���
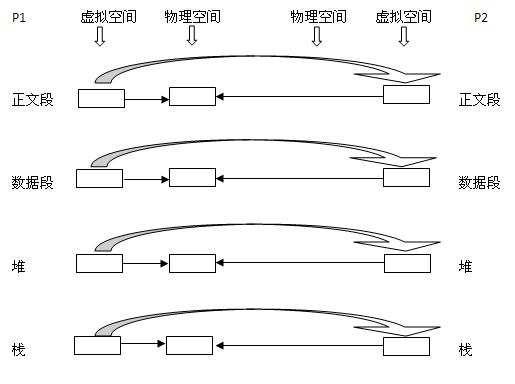
COW������ ������һ��������P1������һ�����壬��ô���������Ҳ������ġ��������������ַ�ռ䣨����Ӧ�����ݽṹ��ʾ�����У����ĶΣ����ݶΣ��ѣ�ջ���ĸ����֣���Ӧ�ģ��ں�ҪΪ���ĸ����ַ�����Ե������顣�������Ķο飬���ݶο飬�ѿ飬ջ�顣������η��䣬�����ں�ȥ�����£��ڴ˲������� 1. ����P1��fork()����Ϊ���̴���һ���ӽ���P2�� �ںˣ� ��1������P1�����ĶΣ����ݶΣ��ѣ�ջ���ĸ����֣�ע������������ͬ�� ��2��Ϊ���ĸ����ַ��������飬P2�ģ����ĶΣ���PI�����Ķε������飬��ʵ���Dz�ΪP2�������Ķο飬��P2�����Ķ�ָ��P1�����Ķο飬���ݶΣ���P2�Լ������ݶο飨Ϊ������Ӧ�Ŀ飩���ѣ���P2�Լ��Ķѿ飬ջ����P2�Լ���ջ�顣����ͼ��ʾ��ͬ���Ҵ�ķ����ͷ��ʾ�������ݡ�
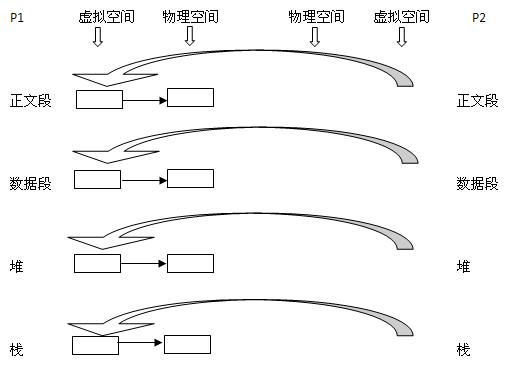
2. дʱ���Ƽ������ں�ֻΪ�����ɵ��ӽ��̴�������ռ�ṹ�������������ڸ����̵����⾿���ṹ�����Dz�Ϊ��Щ�η��������ڴ棬���ǹ��������̵������ռ䣬�����ӽ������и�����Ӧ�ε���Ϊ����ʱ����Ϊ�ӽ�����Ӧ�Ķη��������ռ䡣
3. vfork()������������ӻ𱬣��ں����ӽ��̵������ַ�ռ�ṹҲ�������ˣ�ֱ�ӹ����˸����̵�����ռ䣬��Ȼ�ˣ�����������˳ˮ���۵Ĺ����˸����̵������ռ�
ͨ�����ϵķ��������Ŵ�ҶԽ����и��������ʶ��������ôһ������ֳ��Լ����ģ�������һ�����壬��ô��������������壬ϵͳ����Ϊʵ����������Ӧ��ʵ�壬 ���ʵ��������ʵ�塣��������ϵͳ�ж�����Ӧ�����ݽṹ��ʾ������ʵ����������������������塣����Ԯ��LKD ��ͳ��fork()ϵͳ����ֱ�Ӱ����е���Դ���Ƹ��´����Ľ��̡�����ʵ�ֹ��ڼ���Ч�ʵ��£���Ϊ������������Ҳ���������������������ǣ�����½��̴�������ִ��һ���µ�ӳ����ô���еĿ�������ǰ��������Linux��fork()ʹ��дʱ������copy-on-write��ҳʵ�֡�дʱ������һ�ֿ����Ƴ���������������ݵļ������ں˴�ʱ���������������̵�ַ�ռ䣬�����ø����̺��ӽ��̹���ͬһ��������ֻ������Ҫд���ʱ�����ݲŻᱻ���ƣ��Ӷ�ʹ��������ӵ�и��ԵĿ�����Ҳ����˵����Դ�ĸ���ֻ������Ҫд���ʱ��Ž��У��ڴ�֮ǰ��ֻ����ֻ����ʽ���������ּ���ʹ��ַ�ռ��ϵ�ҳ�Ŀ������Ƴٵ�ʵ�ʷ���д���ʱ����ҳ�������ᱻд��������—������˵��fork()����������exec()—���Ǿ����踴���ˡ�fork()��ʵ�ʿ������Ǹ��Ƹ����̵�ҳ���Լ����ӽ��̴���Ωһ�Ľ�������������һ������£����̴�������������һ����ִ�е��ļ��������Ż����Ա��⿽�����������Ͳ��ᱻʹ�õ����ݣ���ַ�ռ��ﳣ��������ʮ�����ݣ�������Unixǿ�����̿���ִ�е���������������Ż��Ǻ���Ҫ�ġ����ﲹ��һ�㣺Linux COW��execû�б�Ȼ��ϵ
PS��ʵ����COW������������Linux��������Ӧ�ã���������C++��String���е�IDE������Ҳ֧��COW�����������磺 string str1 = "hello world";string str2 = str1; ֮��ִ�д���: str1[1]='q';str2[1]='w'; �ڿ�ʼ����������str1��str2������ݵĵ�ַ��һ���ģ����������ݺ�str1�ĵ�ַ�����˱仯����str2�ĵ�ַ����ԭ����,�����C++�е�COW������Ӧ�ã�����VS2005�ƺ��Ѿ���֧��COW�� ��һ���֣�linux��̬���ӿ�ȫ�ֱ�������
from: http://blog.csdn.net/iterzebra/article/details/6255270
ע�⣺�����еĴ����Ķ� ������Ա������������ �����ߣ�����ӣ�ʯ�����˰��� �Ķ���ʼǡ��Ƽ���ҿ����Ȿ�顣 һ����̬���� ����ϵͳ���ѳ���������Ŀ���ļ�ȫ�����ص��ڴ棬���������ϵ���㣬��ϵͳ��ʼ�������ӡ������뾲̬�������ƣ������з��Ž�������ַ�ض�λ�� �������program1��program2��������lib.o����������program1��ʱ��lib.o�Ѿ������أ���ô������program2��ʱ��ϵͳ����Ҫ����lib.o����ֻ�ǽ�program2��lib.o�������ӡ� ������������ʡ�ڴ棬���������ڴ�����ҳ��Ļ��뻻��������CPU�������С� ��̬���ӵ�����һ���ص��dz�������ʱ���Զ�̬ѡ����ظ��ֳ���ģ�顣����ŵ㼴������������IJ����Plug-in���� ����һ����˾�ƶ��IJ�Ʒ�����ƶ��˽ӿڡ�������˾������Щ��ڱ�д����Ҫ��Ķ�̬���ӿ⣬������Զ�̬������Щ������ģ�飬��������ʱ��̬�����ӣ���չ����Ĺ��ܡ� ��̬����Ҳ�����˳�������ԣ����粻ͬ����ϵͳ�Ŀⶼ�ṩ��printf���ڸÿ�֮�ϵĴ��룬���Կ粻ͬ����ϵͳ�� ������̬���ӵ�ʵ�� ��̬����ʹ�õ�������������ǿ�����Ŀ���ļ��ģ�����ʵ���϶�̬���ӿ���Ŀ���ļ����в�� ��̬�����漰����ʱ���ӣ���Ҫ����ϵͳ֧�֣�һЩ�洢�����������ڴ桢�����̻߳��ƣ��ڶ�̬�����£�Ҳ���뾲̬���Ӳ�ͬ��Linux�£�ELF��̬�����ļ�����DSO����̬��������Windows�£�һ��ΪDLL�� Linux�³���C�������п�Ϊglibc���䶯̬���ӿ���ʽ�汾��/libĿ¼�µ�libc.so���������ʱ����̬�����������ж�̬���ӿ�װ�ص����̵�ַ�ռ䣬��������δ������Ű���Ӧ�Ķ�̬���ӿ⣬�����ض�λ������ ����ÿ�μ�����Ҫ��̬�����ӣ�������������ʧ����ȡ�ӳٰ�Lazy Binding�����Զ�������Ż���
����һ������ Program1.c:
#include "Lib.h"
#ifndef LIB_H lib.c:
#include <stdio.h>
ʹ�����±��� gcc -fPIC -shared -o Lib.so Lib.c ��������program1��program2�� gcc -o Program1 Program1.c ./Lib.so gcc -o Program2 Program2.c ./Lib.so
�ھ�̬����������program1��program2�Ĺ����У�������֪��foobar������������ʡ�����Ǿ�̬Ŀ��ģ���еĺ�������ô�������е�ַ�ض�λ������Ƕ�̬����ģ���еģ�����Ϊ��̬���ӷ��ţ���װ��ʱ�����ض�λ�� ��ô��̬���������֪���÷����Ƕ�̬���ӷ����أ������./Lib.so �ļ��а��������ķ�����Ϣ����̬�������Լ�װ��ʱ�Ķ�̬����������ͨ�����еķ�����Ϣ��֪��Щ��Ϣ�ġ�������̬��������foobar����������ű�ʶΪ��̬���ӷ��š� ����Program1��ʹ��cat /proc/����ID/maps �鿴�����ӳ�䣺
00400000-00401000 r-xp 00000000 ca:02 399066 /root/mylinuxc/Program1 libc-2.11.1.so��c�������п⡣ ld-2.11.1.so�������Ŀ���ļ���ʵ��Linux�µĶ�̬��������ϵͳִ��program1֮ǰ���Ὣ����Ȩ������̬������������������ж�̬���ӹ�����Ȼ��ѿ���Ȩ����program1��
ʹ��readelf -l�鿴Lib.so:
Elf file type is DYN (Shared object file)
��������ص�ַΪ0x0000000000000000,��ʵ��7fa557684000����ʱ��ֵ����Ϊ�������ļ���װ�ص�ַ������ʱ����ȷ���������ڶ�̬����������ʱ�ŵ���ȷ���ġ������ڶ�̬���ӿ��ļ�������Ч��0x0000000000000000�� ���ڵ�ϵͳ�����õ��Ƕ���ijЩ�����⣬ָ����װ�ص�ַ�ķ����������ϱߵ�Lib.so�������ƶ���װ�ص�ַΪ7fa557684000����������������ַ�ij�ͻ�����������Lib2.soҲ��ָ����7fa557684000�����ַ�ʽ��Ϊ��̬�����⣨Static shared object������̬��������˵�ַ��ͻ��������ΪԤ�����еĿռ�����ƣ������°汾�Ŀ�Ĵ�С��������Լ�� Ϊ�˽��������⣬���뱣֤�������ܹ�������װ��ʱȷ���ĵ�ַװ�ء� ����������⣬��Ȼ�뵽�������þ�̬�����еĵ�ַ�ض�λ��������Ȼ������Ӧ������װ�ض���������ʱ�����ض�λ����װ��ʱ�ض�λ�� ���磬foobar�ĵ�ַ��Ը����ļ���ʼ��ƫ��Ϊ0x100���ÿ��ļ���װ��ʱ�ij�ʼ��ַȷ��Ϊ0x10000000����foobar�ĵ�ַװ�غ����0x100000100��װ�������������ض�λ�������ض�λ���м�¼���ж�foobar��ַ���õĵط���ȫ�����¸�дΪ0x100000100�� ������̳�Ϊ װ��ʱ�ض�λ��Windows�³�Ϊ��ַ���ã�Rebasing���� ����Ϊ�˽����������������������ƾ�̬���ӵķ���������Ҫ�ڽ��̼���й�������Ķ�̬���ļ���ȴ�����á���Ϊ�÷��������ض�λ��ʱ�����Ĵ�����еĶ�foobar�����õ�ַΪ�µ�ֵ�������ֵ�ǽ�����صģ�һ��һ��������Ϊ�Լ��õ�ֵ���������̾���ʹ�øù��������ˡ� �����������ļ��еĿ������ݲ��֣���Ϊÿ�����̶���������һ�����������Կ��Բ��������취�� Linux��GCC�еIJ�ʹ��-fPIC������ʹ��-shared���Dz���װ��ʱ�ض�λ�Ĵ��롣
���е�-fPIC�������ܽ��װ��ʱ�ض�λ������ָ��������̼乲�������⣬��ʵ�ֵĻ���˼���ǰ�ָ������Ҫ�����ض�λ�ĵ��Dz��ַ�������������ݲ���һ��ʹ��ÿ�����̶���һ�����������ּ�������ַ�ش��뼼����
�ģ���ַ�ش��� ������ַ�ش�����ʵ�������ڻ����������鷳���������ǿ�����Щ��Ҫ��ַ�ض�λ���ѿ��Բ���Ҫ��ַ�ض�λ�ģ����ò���Ҫ��ַ�ض�λ�ķ���ʵ�֡���Щ����Ҫ�ض�λ�ģ��Ͳ���һ�ֽ����ַ�洢��һ�����ݽṹ�У��������ݽṹ���õ����ݶΣ������ͨ�������ݽṹ��ӷ��ʸõ�ַ�ķ������������ݶ�ÿ�����̶���һ�ݸ��������Ըô��루��̬���ӿ⣩�ǿ��Խ��̹����ġ� ģ���еĵ�ַ���÷�ʽ���������Ƿ��ģ��ֳɣ�ģ���ں�ģ�������ã����ղ�ͬ���÷�ʽ���Ի���Ϊָ�����ú����ݷ��ʡ�����������£� 1��ģ���ں������� 2��ģ�������ݷ��� 3��ģ���⺯������ 4��ģ�������ݷ���
������룺 static int a�� extern int b�� extern void ext(); void bar() { a=1; b=2; } void foo() { bar(); ext(); }
bar�ķ������룺  �������ڱ�������pic.c����ʱ��������ȷ��b��ext��ģ���ڲ�����ģ���ⲿ�ġ���Ϊextern��ζ���ڱ��Ŀ���ļ��������п��ܱ��Ŀ���ļ�������������Ŀ���ļ���ͬһ���������еģ�������һ��ģ��ġ������������в�ȷ���ĵ���ģ���ⲿ�����ͱ���������MSVC�������ṩ��__declspec(dllimport)��չ���ƶ�һ��������ģ���ڲ�����ģ���ⲿ�ġ� ��������1���������ǵ����ߺͱ����������λ�ù̶�����ȡ��Ե�ַ���ü��ɡ������ڼĴ�������Ե��á���ˣ���������ָ���ʵ����Ҫ�ض�λ�����������Ļ����룬ֻҪ�����ߺͱ������ߵ���Ե�ַ���䣬��������Ч�ġ� ��������2���������ѰַҲ�ɽ�������������ݵķ��ʣ���ȡ��Է���������ݵ�ָ��ĵ�ַ����Ѱַ�ķ�ʽ�����ڸ����ݺͷ�������ָ�����Ե�ַ���䣬���Բ���Ҫ�ض�λ�ˡ���Ȼ��Ŀǰһ�㶼�������һ��ָ��ĵ�ַ���������ݡ���ô��λ�ȡ��һ��ָ��ĵ�ַ�أ������Ļ������Կ�������ʵ������ȵ���__i686.get_pc_thunk.cx�������ú��������ص�ַ��ֵ�ŵ�ecx�Ĵ�������������ͨ��eip�Ĵ�����ֵ����Ϊeip����һ��ָ���ַ����Ȼ��ͨ��ecx��Ԥ��ָ����Ѱַ���е�ƫ���������ɻ�ȡ��ǰ���ݴ������ˡ�����ʵ��Ե�ǰָ��ѰַҲ��ͬ��������ֻ���е��鷳����Ե�ǰָ����Ҫ��֮ǰ��Ҳ���ǵ�ǰָ���eip���棩�� ������ص�0x10000000����ô��a�ĵ�ַ���ǣ�0x10000000+0x454��+0x118c+0x28����0x10000000+0x454������һ��ָ��ĵ�ַ��0x118c+0x28��a����ڸ�ָ���ƫ�ơ� ֮���� <__i686.get_pc_thunk.cx> �� mov (%esp) %ecx����Ϊ�ڵ���֮ǰ�����ú���������һ��ָ���ַѹջ������%esp�����ú�������һ����ַ�� [e01] ��������3����Ȼ��Ҫ�ض�λ��ELF���������ǽ�����ģ���ȫ�ֱ����ĵ�ַ�洢�����ݶ����ȫ��ƫ�Ʊ���Global Offset Table��GOT���С��������b�������ҵ�GOT����֪b��Ŀ���ַ��Ȼ����ȥ���ʡ���������װ��ģ���ʱ�Ὣ��GOT��������ȷ����䡣GOT�����ݶΣ���֤�˶���������Լ��ĸ�����GOT�Լ�����ҲҪ�ǵ�ַ�صģ�������Ϊ���ص�ַ��ͬ������Ҫ��GOT�ķ���Ҳ�����ض�λ�������Ͳ��ܶ���̹����ˡ� GOT�����ĵ�ַ����ͨ����ģ���ڲ����ݷ������Ƶķ����������ʱ��ȷ��GOT�뵱ǰָ���ƫ�ơ���ô��ָ��ָ���ʱ��ȡ��ָ��ĵ�ַPC���ټ���ƫ�������ɵõ�GOT��λ�á�Ȼ���ٸ��ݱ�����GOT�е�λ�ã���ȡ�����ĵ�ַ�� ����bar()����b��������ص�0x10000000����b�ĵ�ַ��GOT��λ��Ϊ��0x10000000+0x454+0x118c��+(-8)=0x100015d8(-8�IJ�����0xfffffff8)����0x10000000+0x454+0x118c����GOT���ĵ�ַ��-8��b�ĵ�ַ��GOT���е�ƫ������ ����0x10000000�ǵ�ǰ�μ��صĵ�ַ����0x454����callָ�����һ����Ҳ����addָ��ĵ�ַ����ʱ��ecx����ֵ��֮��ecx������0x118c���õ���GOT���ĵ�ַ����ʱ��ecx��GOT����ַ��+0xfffffff8��λ���Ǵ洢��b�ĵ�ַ�� ʹ��objdump -h �鿴GOT��λ�ã����Ҫ�鿴��̬���ؿ�Ķ�λ��Ŀ  b��ƫ����000015d8�����ֵ�������ģ��ģ�������GOT������˸�����ʹ�����ָ���ƫ�Ƶó��Ľ����ַ0x100015d8����ȥ��ַ0x10000000�õ��Ľ��15d8һ�¡� ��������4������������3�Ĵ�������������GOT�����������ext���������� call 494 <__i686.get_pc_thunk.cx> add $0x118c,%ecx mov 0xffffffffc(%ecx),%eax call *(%eax)
Ҳ�ǵõ�PC��Ȼ�����ƫ�Ƶõ�GOT�е�ƫ�ƣ����ʹ�ü�ӵ��á� ��ʵELF������һ�ָ�Ϊ���Ӻ;��ɵķ�������Ϊ�������ַ��������Ǵ����������⡣ �����������������ͣ����Ƕ�Ӧ�IJ�ȡ������ʹ�ô���ﵽ��ַ�أ� ָ����ת ���ݷ��� ģ���ڲ��� �����ת�͵��� ��Ե�ַ���� ģ���ⲿ�� �����ת�͵��ã�GOT�� ��ӷ��ʣ�GOT��
-fPIC��-fpic��������-fpic�����Ĵ���С��ִ���ٶȿ졣����-fpic��ijЩƽ̨�ϻ������ƣ���Ϊ��ַ�ش�����Ӳ��ƽ̨��صġ�����ȫ�ַ��ŵ����������볤�ȵȡ�-fPIC��û���������ơ� �壬�鿴�Ƿ���PIC�� readelf -d foo.so|grep TEXTREL ����������������������PIC�ģ�������ǡ�PIC�Ķ�̬���ӿⲻ�Ậ���κδ�����ض�λ����TEXTREL��������ض�λ����
����PIE ��ַ�ؼ���Ҳ�������ڿ�ִ���ļ��ϣ�����ΪPosition-Independent Executable��ʹ�ò���Ϊ-fPIE��-fpie�� �ߣ���ִ���ļ��ж��ⲿ���ݵķ��� ͨ���ϱߵ�����������֪�������ڶ�̬���ӿ⣬���ķ��ţ�����Ƕ�ģ���ڲ������ݷ��ʺͺ������ã���ʹ����Ե�ַ���ʵķ�ʽ�������Ͳ���Ҫ���е�ַ�ض�λ�ˣ���Ϊ�����к��л�ȡ��һ��ָ���ַ��ָ������������һ��ָ���ַ��ƫ������ͨ��ָ���ַ��ƫ�����������ݻ��߽��к������á����ڲ���Ҫ�ض�λ����˶�����̿��Թ����ö�̬���ӿ⡣����ģ���ⲿ�����ݷ��ʺͺ������ã��������GOT���ķ���������Ҫ���ʵ�ģ���ⲿ���ݺͺ�����ʹ��GOT������¼���ڽ��ж�̬���ص�ʱ��дGOT���з��ŵĶ�Ӧ��ַ������GOT�������ķ������������ģ���ڲ����ݷ��ʵķ�������ΪGOT������ص�ַ��ƫ�ƣ�ʵ�����Dz�����ָ������ƫ�ƣ������ڱ����ʱ��ȷ����ʹ�ö�GOT���ķ��ʾ��д������ԡ��������ڽ��̶����Լ���GOT�ĸ�����ʹ�ö�����̿����ڼ����ض�λ��ʱ�����Լ���GOT������Ӱ���Ľ��̡� ���ڿ�ִ���ļ�����external������ȫ�ֱ������������Ա�ģ�������Ŀ���ļ���������ģ�顣��ִ���ļ��У�����ģ���ڵķ������ú�ģ����ķ������ã�����������ʱȷ��������Ϊģ������Ŵ����� ���ڿ�ִ���ļ��з��ʹ��������ļ��е�ȫ�ֱ������ŵ����⣬���Ҳ����������PIC���ƣ�������´����������ɵĴ����У����������GOT���ĵ�ַƫ�Ƶ�Ѱַ��ʽ������ʸ�ȫ�ֱ�����ʱ����Ҫ���Ȼ�ȡPC��ֵ��Ȼ����ϸ�ƫ�ƻ�ȡ��GOT����λ�ã��ټ�����GOT����ƫ�ƻ�ȡ�ñ����ĵ�ַ��GOT���д洢��λ�ã�Ȼ���ȡ���ñ����ĵ�ַ����дGOT����ȫ�ֱ����ĵ�ַ���ڶ�̬���ӿⱻ����ʱ���ص�ʱ����д�ģ���֮����з��ʡ� ���ڿ�ִ���ļ���������Ĵ��룬��������ͬ������PIC���ƣ��������������һ��ָ��ĵ�ַ��ƫ����Ѱ��GOT��������Ѱ�����ݵ�ַ�ķ�ʽ��������Ȼ��������ͨ����һ���ķ�ʽ�������Ե�ַ���ʣ���ˣ���ִ���ļ��е�ȫ�ֱ������ŵĵ�ַ�������ڽ��б������ӵ�ʱ����Ծ�����������ʵ���ϣ����ڶ���������ģ���ȫ�ֱ����ĵ�ַ���������ģ����õ��Ƕ�̬���ӵķ�ʽ����ô�����ַ��Ȼ�Dz����ڱ������ӵ�ʱ���������ģ�����ֻ���ڼ���ʱ����֪��ģ����ص�ַ������ͨ��������ģ����ص�ַ��ƫ�ƻ�֪�����ĵ�ַ����ˣ���ִ���ļ����������»��ƣ�ʹ�ñ�������ʱ�����Բ�֪�������ĵ�ַ��Ҳ�����������У���bss���з���ñ������ض�λ���е�����ΪCOPY�� ����: external int global; int foo() { global=1; } int main(){ }
�������������ӳ�Ϊ��ִ���ļ���ʹ��objdump -R �鿴�ض�λ��������global����Ϊ“COPY”����������������һ������JUMP_SLOT�ȣ����ң����Ǵ����bss�εģ���������got���С� �������������ģ���Ȼ�ڼ��ص�ģ���У����ݶΣ�Ҳ�иñ����ĸ���������ì�ܡ�ʵ���ϣ�ELF�ڱ��빲�����ʱ������ȫ�ֱ�������ģ�������ã�ʹ��GOT�����ʣ���ʹ��ȷ֪���ñ������Լ�ģ��ģ�������ڸ�Ŀ���ļ��У����������������ʱ��̬���ص�ʱ���ֿ�ִ���ļ���Ҳ�иñ��������ͳһ��GOT�����ض�λ���Ϊ��ִ���ļ�bss���иñ��������ĵ�ַ������ڹ������жԸñ��������˳�ʼ������̬װ�������ø���ʼ����ֵ��������ִ���ļ�bss�иñ����ĸ���λ�á������ִ���ļ���û�иñ�������GOT�����ض�λ��ָ���Լ�ģ���ڵĸñ�������������ζ�Ŷ�ģ���ڵı������ʣ�Ҳ������GOT����Ҳ���ǻ��ڹ������е�ȫ�ֶ��������Ƿ����ڲ��ģ������������Ƿ����ڲ��ģ�������Ϊ�ⲿģ�����������ʹ��GOT�����з��ʡ� ���⣺ ��������lib.so�е�ȫ�ֱ��� G������A��B��ʹ����lib.so����ôA�ı�G��ʱ���Ƿ�Ӱ�����B�е�G�� �ش� ���ᡣ��ΪG��ʵ�Ǵ洢��bss�еģ�bss�������ݶΣ�ÿ�����̶����Լ��ĸ������������������������ȫ�ֱ���������ڲ�ȫ�ֱ���û��������Ϊ�������ݶΣ���bss�Σ����������Լ��ĸ����������ͨ��ȫ�ֱ������н��̼�ͨ�ţ����Բ���"�������ݶ�"������ʹ�ò�ͬ���̷���ͬһ��ȫ�ֱ�����������һ�����̣�������ñ�����������̹߳�����������߳�ӵ���Լ����ݶεĸ��������Բ���“�ֲ߳̾��洢”������
�ڶ����֣�DLL�������ݶ�
������һ�����ݶλ����ܴﵽ�������ݵ�Ŀ�ģ���Ҫ���߱������öε����ԣ������ַ�������ʵ�ָ�Ŀ�ģ���Ч������ͬ�ģ���һ�ַ�������.DEF�ļ��м���������䣺 SETCTIONS shareddata READ WRITE SHARED ��һ�ַ���������Ŀ��������ѡ��(Project Setting --��Link)�м���������䣺 /SECTION:shareddata,rws
��һ�㣺ʲô�ǹ������ݶΣ�ΪʲôҪ�ù������ݶΣ�������ʲô��;����
��Win16�����У�DLL��ȫ�����ݶ�ÿ���������Ľ�����˵������ͬ�ģ�����Win32�����У����ȴ�����˱仯��DLL�����еĴ������������κζ�����������������������̻߳�������С�������������DLLʱ������ϵͳ�Զ���DLL��ַӳ�䵽�ý��̵�˽�пռ䣬Ҳ���ǽ��̵������ַ�ռ䣬����Ҳ���Ƹ�DLL��ȫ�����ݵ�һ�ݿ������ý��̿ռ䡣Ҳ����˵ÿ��������ӵ�е���ͬ��DLL��ȫ�����ݣ����ǵ�������ͬ������ֵȴ����һ������ͬ�ģ������ǻ�������ġ�
��ˣ���Win32������Ҫ���ڶ�������й������ݣ��ͱ�����б�Ҫ�����á��ڷ���ͬһ��Dll�ĸ�����֮�乲���洢����ͨ���洢��ӳ���ļ�����ʵ�ֵġ�Ҳ������Щ��Ҫ���������ݷ��������������һ�����������ݶ�����Ѹöε���������Ϊ�������������Щ��������ֵ��������������û�и���ʼֵ�ı�������һ����δ����ʼ�������ݶ��С�
#pragma data_segԤ����ָ���������ù������ݶΡ����磺
#pragma data_seg("SharedDataName") HHOOK hHook=NULL; //�����ڶ����ͬʱ���г�ʼ��!!!!#pragma data_seg()
��#pragma data_seg("SharedDataName")��#pragma data_seg()֮������б����������ʸ�Dll�����н��̿����������ټ���һ��ָ��#pragma comment(linker,"/section:.SharedDataName,rws"),[ע�⣺���ݽڵ�����is case sensitive]��ô������ݽ��е����ݿ���������DLL��ʵ��֮�乲�������ж���Щ���ݵIJ��������ͬһ��ʵ���ģ���������ÿ�����̵ĵ�ַ�ռ��ж���һ�ݡ�
��������ʽ����ʽ����һ����̬����ĺ���ʱ��ϵͳ��Ҫ�������̬��ӳ�䵽������̵������ַ�ռ���(���¼��"��ַ�ռ�")����ʹ��DLL��Ϊ���̵�һ���֣���������̵�����ִ�У�ʹ��������̵Ķ�ջ��(������ֽ�code Injection���������㷺��Ӧ�����˲������ڿ����Ǻ�^_^)
�ڶ��㣺�ھ���ʹ�ù������ݶ�ʱ��Ҫע���һЩ���⣡
Win32 DLLs are mapped into the address space of the calling process.By default, each process using a DLL has its own instance of all the DLLs global and static variables. (ע��:��ʹ��ȫ�ֱ����;�̬����Ҳ�����ǹ�����!) If your DLL needs to share data with other instances of it loaded by other applications, you can use either of the following approaches:
· Create named data sections using thedata_seg pragma.
· Use memory mapped files. See the Win32 documentation aboutmemory mapped files.
Here is an example of using the data_seg pragma:
#pragma data_seg (".myseg")
int i = 0; char a[32] = "hello world"; #pragma data_seg()
data_seg can be used to create a new named section (.myseg in this example). The most typical usage is to call the data segment .shared for clarity. You then must specify the correct sharing attributes for this new named data section in your .def file or with the linker option/SECTION:.MYSEC,RWS. (�����������ȿ���ʹ��pragmaָ����ָ����Ҳ������VC��IDE��ָ����)
There are restrictions to consider before using a shared data segment:
· Any variables in a shared data segmentmust be statically initialized. In the above example, i is initialized to 0 and a is 32 characters initialized to hello world.
· All shared variables are placed in the compiled DLL in the specified data segment. Very large arrays can result in very large DLLs. This is true of all initialized global variables.
· Never store process-specific information in a shared data segment. Most Win32 data structures or values (such as HANDLEs) are really valid only within the context of a single process.
· Each process gets its own address space. It is very important that pointers are never stored in a variable contained in a shared data segment. A pointer might be perfectly valid in one application but not in another.
· It is possible that the DLL itself could get loaded at a different address in the virtual address spaces of each process. It is not safe to have pointers to functions in the DLL or to other shared variables.
��̬���ӿ��е�ȫ�ֱ������ڽ��̼乲����дʱ����
Posted inLinux/Unix,���10 ������
�����ͬѧ��BBS�������йض�̬���ӿ��е�ȫ�ֱ��������⡣���ij��̬������һ��ȫ�ֱ���������aʹ�õ������̬�⣬����bҲʹ���������̬�⣬��ô����a��b�е�ȫ�ֱ�����һ����Ҳ����˵�����̼�ʹ�ö�̬��ʱ������ȫ�ֱ����𣿴����ǣ���һ������������дʱ������������Ա�ĸо��ǣ���������ллWWF��˵����
testshare.c
�������������Ƭ�Ϻܼ�����testshare.h������������������testshare.c��ʵ�������������������Ҷ�����һ��ȫ�ֱ���������������testshare.c����ɶ�̬�⣺
�������testshare_main1.c��ʹ�ö�̬��libtestshare.so��
������������������ij���ִ�У�
ִ�г���
ִ�е�ʱ�������������ն����Ⱥ�ִ�ִ�г����ֳ������
��Ȼ����ִ�еij���û���ܵ���ִ�еij����Ӱ�졣�ɴ˿ɼ�����ͬ�Ľ��̲���������ͬ��̬���е�ȫ�ֱ�����
November 28, 2010
:-)��������˵��ʲô�أ� “��̬���ӿ��е�ȫ�ֱ������ڽ��̼乲����дʱ����”10������
��ã�������д��"VC++ DLL�������dz��"���ر����ջ� ֻ���и��ط����ϸ㲻���ף�������DLL����ȫ�ֱ���ʱ��ָ����.lib��·����#pragma comment(lib,"dllTest.lib")������ô.dll���ļ���·���أ��ҳ����Ű�.dll�ļ��Ƶ���ĵط�����������������ˣ�����.dll��������ôָ���� ϣ�������ڰ�æ�г�ո��ҽ��һ�£���ʤ�м��� һλ��̰����� �ش� Windows������˳������DLL�� ��1����ǰ���̵Ŀ�ִ��ģ�����ڵ�Ŀ¼�� ��2����ǰĿ¼�� ��3��Windows ϵͳĿ¼��ͨ��GetSystemDirectory �����ɻ�ô�Ŀ¼��·���� ��4��Windows Ŀ¼��ͨ��GetWindowsDirectory �����ɻ�ô�Ŀ¼��·���� ��5��PATH �����������г���Ŀ¼�� ��ˣ���ʽ����ʱ��DLL�ļ���·������Ҫָ��Ҳ����ָ����ϵͳָ������1��5�IJ���Ѱ��DLL�����Ƕ�Ӧ��.lib�ļ�ȴ��Ҫָ��·�������ʹ��Windows API����LoadLibrary��̬����DLL�������ָ��DLL��·���� ���,����һλC++��ѧ��,����PCONLINE���˽�ѧ֮��,���治dz��������һ���ܷ���DLL��ʹ�ö��߳�?MSDN����#using <mscorlib.dll>���ָ��֮��ʵ���˶��߳�,��������֧��DLL.. ������ʲô�취֧���������߳�DLL??�ܷ��һ��Դ����? �ش� ��DLL�п��Դ������̣߳�WIN32���ڶ��̵߳�֧���Dz���ϵͳ�����ṩ��һ�����������������û���д������һ���������һ������̨�������Ƕ�����ʹ�ö��̣߳� #include <stdio.h> #include <windows.h> void ThreadFun(void) { while(1) { printf( "this is new thread/n" ); Sleep( 1000 ); } } int main() { DWORD threadID; CreateThread( NULL, 0, (LPTHREAD_START_ROUTINE)ThreadFun, NULL, 0, &threadID ); while(1) { printf( "this is main thread/n" ); Sleep( 1000 ); } } �۲�������еĽ��Ϊ�ڿ���̨�����Ͻ������this is main thread��this is new thread�� �������������һ�����߳�DLL�����ӡ� DLL�����ṩһ���ӿں���SendInit���ڴ˽ӿ������������߳�SendThreadFunc��������̵߳Ķ�Ӧ��������������ʹ��ԭʼ����socket���ͱ��ġ��ο�������ľ����鼮��Windows���ı�̡������Ƿ��֣�������DLL�����ص�ʱ�����̰�ʱ������һ���µ��̡߳� ����̵߳ȴ�һ��CEvent�¼��������̼߳�ͨ�ţ���Ӧ�ó������DLL�еĽӿں���SendMsg( InterDataPkt sendData )�����ͷŴ��¼�����������ص�Դ���룺 ��1�����ͱ����߳���ں��� /////////////////////////////////////////////////////////////////////////// //��������SendThreadFunc //�������ܣ����ͱ��Ĺ����߳���ں�����ʹ��UDPЭ�� //////////////////////////////////////////////////////////////////////////// DWORD WINAPI SendThreadFunc( LPVOID lpvThreadParm ) //��ʾ�������̺߳���Ӧʹ��WINAPI������WINAPI���궨��Ϊ__stdcall { /* ����socket */ sendSock = socket ( AF_INET, SOCK_DGRAM, 0 ); if ( sendSock == INVALID_SOCKET ) { AfxMessageBox ( "Socket����ʧ��" ); closesocket ( recvSock ); } /* ���Ŀ��ڵ�˿����ַ */ struct sockaddr_in desAddr; desAddr.sin_family=AF_INET; desAddr.sin_port=htons( DES_RECV_PORT ); //Ŀ��ڵ���ն˿� desAddr.sin_addr.s_addr = inet_addr( DES_IP ); /* �������� */ while(1) { WaitForSingleObject( hSendEvent, 0xffffffffL );//���ȴ��¼����� ResetEvent( hSendEvent ); sendto( sendSock, (char *)sendSockData.data, sendSockData.len, 0, (struct sockaddr*)&desAddr, sizeof(desAddr) ); } return -1; } ��2��MFC����DLL��InitInstance���� ///////////////////////////////////////////////////////////////////////////// // CMultiThreadDllApp initialization BOOL CMultiThreadDllApp::InitInstance() { if ( !AfxSocketInit() ) //��ʼ��socket { AfxMessageBox( IDP_SOCKETS_INIT_FAILED ); return FALSE; } return TRUE; } ��3�����������߳� //////////////////////////////////////////////////////////////////////////////// //��������SendInit //�������ܣ�DLL�ṩ��Ӧ�ó�����ýӿڣ��������������߳� ///////////////////////////////////////////////////////////////////////////// void SendInit(void) { hSendThread = CreateThread( NULL, 1000, SendThreadFunc, this, 1, &uSendThreadID ); } ��4��SendMsg���� //////////////////////////////////////////////////////////////////////////////// //��������SendMsg //�������ܣ�DLL�ṩ��Ӧ�ó�����ýӿڣ����ڷ��ͱ��� ///////////////////////////////////////////////////////////////////////////// extern "C" void WINAPI SendMsg( InterDataPkt sendData ) { sendSockData = sendData; SetEvent( hSendEvent ); //�ͷŷ����¼� } ���ϳ��������һ�������ӣ���ʵ�������Ӧ���У����Ǿ������������Ĵ�����ʽ�����DLL���û����Խ���ʹһ���Ľӿں���SendMsg���Ե�������Ӧ�ó��������˶��̵߳ļ���ϸ�ڡ���֮���ƣ�MFC�ṩ��CSocket���ڵײ��Լ������˶��̻߳��ƣ�����ʹ������ȥ�˶Զ��̵߳�ʹ�á� ����,��������DLL���£����ֵ�����������ֱ����_declspec(dllexport)��������.def�ļ��ж��壬�����ĵ���Ҳһ��������֪�����Ƿ�Ҳ������.def�ļ��е���������������ֻ��������ǰ����_declspec(dllexport)������ķ���������ָ�̣� �ش� һ�����Dz�����.def�ļ������࣬�����Ⲣ����ζ�������.def�ļ������ࡣ ʹ��Depends�鿴����2��"������"�������ɵ�DLL�����Ƿ����䵼������ͼ21���ڶ�"��"symbol����Щsymbol���Ǿ��������������ġ���ˣ�Ϊ����.def�ļ������࣬���DZ������Щ"��"symbolȫ��������ʵ���Dz����㰡�����Զ����࣬�������ֱ����_declspec(dllexport)������
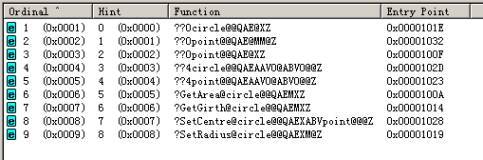
ͼ1 ������ʱ������symbol ����,��������DLL���£�֪����ô����DLL�ˣ��������һ������Ĺ��̣��һ��Dz�֪������Ӧ�ð�ʲô����DLL�����ܸ�һЩ�ⷽ��ľ����� �ش� DLLһ����������ģ���нϹ̶�����ͨ�õĿ��Ա����õ�ģ�飬������һ���dz��õ����ӣ����Ǻ��ܳ�����ԡ������´�ʦ�Ѵ�����Ƶ����Ƶ���㷨ģ��ר������������DLL����������Ե��û�����GUI������ã�ʵ����DLL��Ƶ�ģ���̡̳���ν"��䲻������"��������ԵĽ�����cool���õ��Ļ����Ǽ���DLL��������ο�����̸������ԡ�һ�顣 ����,����DLL���½��Ķ���Windows�ģ�����Linux����ϵͳ�Ͽ�������DLL������ܣ���Windows��ʲô��һ����лл�� �ش� ��Linux����ϵͳ�У�Ҳ���Բ��ö�̬���Ӽ�������������ƣ�����Windows��DLL�Ĵ����͵��÷�ʽ��Щ��ͬ�� Linux����ϵͳ�еĹ�����������Shared Object����Windows���DLL���Ӧ�������Ʋ�һ�����乲�������ļ���.so��Ϊ������Linux������������ص�һЩ�������£� (1)����������ԭ�ͣ� //����Ϊfilename�����������ز�������� void *dlopen (const char *filename, int flag); (2)ȡ������ַ������ԭ��: //��ýӿں�����ַ void *dlsym(void *handle, char *symbol); (3)�رչ���������ԭ��: //�ر�ָ������Ĺ������� int dlclose (void *handle); (4)��̬�������������ԭ��: //���������������ִ��ʧ��ʱ�����س�����Ϣ const char *dlerror(void); ���������Ƿ�������Windows API�D�DLoadLibrary��FreeLibrary��GetProcAddress��Ӱ�ӣ���һ��"��䲻������"�� ��ϵ�����µ�������ʱ��һ���䣬�����Լ��������߷���email��mailto��21cnbao@21cn.com������DLL�ı�����⡣�������еĴ�����©��Ҳ�ȳϻ�ӭ��ָ���� c++����������1������ʹ�þ�̬������һ����̬�����൱�ġ�ͨ��ʹ�� ar �����һЩĿ���ļ���.o�������һ�� ��Ϊһ�������Ŀ⣬Ȼ������ ranlib���Ը������һЩ������Ϣ�� 2������ʹ�ù����� ����ı��������ѡ�� -D_REENTRANT ʹ��Ԥ���������� _REENTRANT �����壬������ż���һЩ�����ԡ� -fPIC ѡ�����λ�ö����Ĵ��롣���ڿ��������е�ʱ���룬������ ѡ���DZ���ģ���Ϊ�ڱ����ʱ��װ���ڴ�ĵ�ַ����֪������� ��ʹ�����ѡ����ļ����ܲ�����ȷ���С� -shared ѡ����߱�����������������롣 -Wl,-soname -Wl ���߱�����������IJ������ݵ����������� -soname ָ���� ������� soname�� �� ���ѿ��ļ������� /etc/ld.so.conf ���оٳ����κ�Ŀ¼�У����� root �������� ldconfig������ �� ���� export LD_LIBRARY_PATH='pwd'�����ѵ�ǰ·���ӵ�������·����ȥ�� 1.7.9 ʹ�ø����������� 1. ldd ���� ldd ������ʾִ���ļ���Ҫ��Щ������, ������װ�ع������������ҵ�����Ҫ�Ĺ�����. 2. soname �������һ���dz���Ҫ�ģ�Ҳ�Ƿdz��ѵĸ����� soname——��д����Ŀ������short for shared object name��������һ��Ϊ�����⣨.so���ļ�����Ƕ�ڿ��������е����֡���ǰ���ᵽ�ģ�ÿһ��������һ����Ҫʹ�õĿ���嵥������嵥��������һϵ�п�� soname����ͬ ldd ��ʾ��������������װ���������ҵ�����嵥�� soname �Ĺؼ����������ṩ�˼����Եı�����Ҫ����ϵͳ�е�һ����ʱ�������¿�� soname ���ϵĿ�� soname һ�����þɿ��������ɵij���ʹ���µĿ���Ȼ���������С��������ʹ���� Linux �£�����ʹ�ù�����ij���Ͷ�λ������ʮ�����ס� �� Linux �У�Ӧ�ó���ͨ��ʹ�� soname����ָ����ϣ����İ汾��������Ҳ����ͨ���������߸ı� soname ����������Щ�汾������ݵģ���ʹ�ó���Ա�����˹�����汾��ͻ��������š� �鿴/usr/local/lib Ŀ¼������ MiniGUI �Ĺ������ļ�֮��Ĺ�ϵ 3. ������װ���� �������õ�ʱ��Linux ������װ������Ҳ����Ϊ��̬��������Ҳ�Զ������á����������DZ�֤��������Ҫ�������ʵ��汾�Ŀⶼ�������ڴ档������װ���������� ld.so ������ ld-linux.so����ȡ���� Linux libc �İ汾��������ʹ��һ���ⲿ��������������Լ��Ĺ�����Ȼ���������ڻ��������������ļ��е�������Ϣ�� �ļ� /etc/ld.so.conf �����˱�ϵͳ���·����������װ����������Ϊ����·����Ϊ�˸ı�������ã������� root �������� ldconfig ���ߡ��⽫���� /etc/ls.so.cache �ļ�������ļ���ʵ��װ�����ڲ�ʹ�õ��ļ�֮һ�� ����ʹ��������������ƹ�����װ�����IJ�������1-4+���� �� 1-4+ ������װ������������ ���� ���� LD_AOUT_LIBRARY_PATH ���˲�ʹ�� a.out �����Ƹ�ʽ�⣬�� LD_LIBRARY_PATH ��ͬ�� LD_AOUT_PRELOAD ���˲�ʹ�� a.out �����Ƹ�ʽ�⣬�� LD_PRELOAD ��ͬ�� LD_KEEPDIR ֻ������ a.out �⣻����������ָ����Ŀ¼�� LD_LIBRARY_PATH ������Ŀ¼���������·������������Ӧ������ð�� �ָ���Ŀ¼�б������ִ���ļ��� PATH ����������ͬ�ĸ�ʽ�� ������������û� ID ���߽��� ID �ij��ñ��������ԡ� LD_NOWARN ֻ������ a.out �⣻���ı�汾���ǣ�����������Ϣ�� LD_PRELOAD ����װ���û�����Ŀ⣬ʹ�������л��Ḳ�ǻ������¶�����⡣ ʹ�ÿո�ֿ������ڡ����������û� ID ���߽��� ID �ij��� ֻ�б���ǹ��Ŀ�ű�����װ�롣�� /etc/ld.so.perload ��ָ�� ��ȫ�ְ汾�ţ����ļ�������������ơ� 4. ʹ�� dlopen ����һ��ǿ��Ŀ⺯���� dlopen()���ú�������һ���¿⣬������װ���ڴ档�ú�����Ҫ�������ؿ��еķ��ţ���Щ�����ڱ����ʱ���Dz�֪���ġ����� Apache Web ����������������������й����м���ģ�飬��Ϊ���ṩ�˶����������һ�������ļ������˼���ģ��Ĺ��̡����ֻ���ʹ����ϵͳ�����ӻ���ɾ��һ��ģ��ʱ��������Ҫ���±����ˡ� �������Լ��ij�����ʹ�� dlopen()��dlopen() �� dlfcn.h �ж��壬���� dl ����ʵ�֡�����Ҫ����������һ���ļ�����һ����־���ļ�������������ѧϰ���Ŀ��е� soname����־ָ���Ƿ����̼����������ԡ��������Ϊ RTLD_NOW �Ļ��������̼��㣻������õ��� RTLD_LAZY��������Ҫ��ʱ��ż��㡣���⣬����ָ�� RTLD_GLOBAL����ʹ����Щ���Ժ�ż��صĿ���Ի�����еķ��š� ���ⱻװ����� dlopen() ���صľ����Ϊ�� dlsym() �ĵ�һ���������Ի�÷����ڿ��еĵ�ַ��ʹ�������ַ���Ϳ��Ի�ÿ����ض�������ָ�룬���ҵ���װ�ؿ��е���Ӧ������ (���α༭��IT) |