|
近年来,有一种趋势是数据中心优先选择商用的硬件和软件而非采用专利的解决方案的商品。他们为什么不能这样做呢?这种做法具有非常低的成本并且可以以更有利的方式来灵活地构建生态系统。唯一的限制是管理员想象的空间有多大。然而,一个问题要问:“与专利的和更昂贵的解决方案相比较,这样的定制解决方案表现如何呢?” 开放源码项目已经发展成熟到了具有足够的竞争力,并提供相同的功能丰富的解决方案,包括卷管理,数据快照,重复数据删除等。虽然经常被忽视的,长期支持的概念是高可用性。 高可用性的想法很简单:消除任何单点故障。这保证了如果一个服务器节点或一个底层存储路径停止工作了(计划或非计划的),还依然可以提供数据请求服务。现在存储部署的解决方案都是多层结构的,并且是可以为高可用性进行配置的,这就是为什么本文严格关注HA-LVM。 HA-LVM
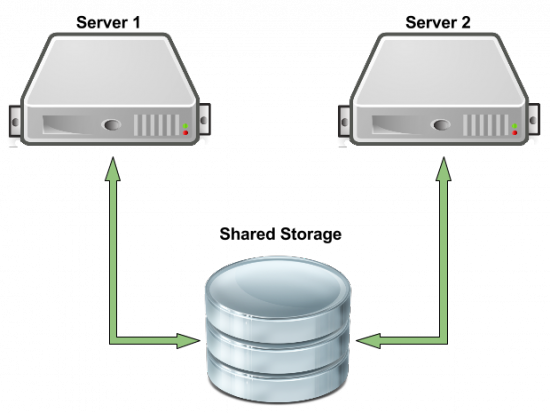
高可用性的逻辑卷管理器(HA-LVM)已经集成了LVM的套件。它提供共享卷一个故障转移的配置,也就是说如果集群中的一台服务器出现故障或进行维护,共享存储配置将故障转移到辅助服务器上,所有I / O请求将恢复,不间断的。HA-LVM配置是一个主/从配置。这意味着在任何一个时间只有一个服务器访问共享存储。在许多情况下,这是一种理想的方法,因为一些先进的LVM的功能,如快照和重复数据删除,在主/从环境下是不支持的(当多个服务器访问共享存储)。 CLVM(LVM集群的守护进程)是HA-LVM一个非常重要的组件。当启动HA-LVM后,CLVM守护进程会防止有多台机器同时对共享存储做修 改,否则对LVM的元数据和逻辑卷会造成破坏。尽管在采用主从配置时,这样的问题并不需要太多担心。要做到这一点,守护进程得依赖于分布锁管理器 (DLM). DLM的目的也是协助CLVM访问磁盘。 下面会举一个2台服务器的集群访问一个外部存储的例子(图一)。 这个外部存储可以是采用磁盘阵列形势的(RAID-enabled) 或者磁盘簇(JBOD)形式的磁盘驱动器,可以是通过光纤信道(Fibre Channel),串行连接(SAS),iSCSI或者其他的存储区域网络及其协议(SAN)接入到服务器的。这个配置是与协议无关的,只要求集群中的服务器能访问到同一共享数据块设备。
图一.举例两台服务器访问同一个共享存储的配置
CLVMMD RAID还不支持集群,所有也就不能兼容CLVM. CLVM 守护进程CLVM 守护进程会将LVM元数据的更新分发到整个集群中,前提是集群中的每个节点都必须运行守护进程。 磁盘簇
磁盘簇(就是一堆磁盘)是一种使用多个磁盘驱动器的架构,但是不支持具有冗余能力的配置。 配置集群
几乎所有的Linux发行套件都提供必要的工具包。但是,工具包的名字可能各有差异。你需要安装lvm2-clumster(在部分发行套件中,可能命名为clvm),Corosync集群引擎,红帽集群管理器(cman),资源组管理进程(rgmanager),还有所有其他运行在服务器上的独立的工具。尽管红帽集群管理器的描述中就包含了“红帽”的发行套件的名字,但是其他与红帽无关的大多数Linux的发行套件还在会把cman列在他们的资源库中。
当集群中所有的服务器都安装好合适的集群工具包后,必须修改集群配置文件来启动集群。创建文件/etc/cluster/cluster.conf,如下编辑内容就可以了:
强调一下clusternode的名字是主机名(按需修改),而且务必保证所有集群中的服务器上的cluster.conf文件是一致的。 启动红帽集群管理器(cman):
如果集群中的某个节目没有激活,它的状态显示为离线:
如果所有服务器都配置好了,cman服务也启动了,所有节点显示状态为在线:
现在你就有一个集群的工作环境了。下一步就是启动CLVM的高可用模式。当前场景中,你只有2台服务器共享的存储中的一个卷,这2台服务器都可以监视和访问/dev/sdb中的数据。
/etc/lvm/lvm.conf 也需要被修改。在全局参数 locking_type 的值默认为 1,必须改为 3:
找一台集群中的服务器,在指定的共享卷上面创建一个卷组,一个逻辑卷和一个文件系统:
上例中消耗卷组中的50GB的来创建逻辑卷,然后用其创建4个拓展的文件文件系统。vgcreate (创建卷组命令)的 -cy 选项 用于启动,并在集群中锁定卷组。lvchange (逻辑卷修改命令)的 -an 选项用来停用逻辑组。但是你必须依赖CLVM和资源管理器的进程,按上面创建的/etc/cluster/cluster.conf的配置中的故障转移的策略来激活他们。一旦逻辑卷被激活,你就可以从/dev/shared_vg/ha_lv访问共享的卷了。
在 cluster.conf 文件中添加故障转移的详细配置信息:
"rm"中的内容会作用到资源管理器上(rgmanager)。这部分的配置通知集群管理器,serv-0001优先独占访问共享卷。数据会挂载在/mnt 这个绝对目录下面。 如果serv-0001因为某些原因当机了,资源管理器就会做故障转移处理,使serv-0002独占访问共享卷,数据会挂载在serv-0002的/mnt的这个目录下。所有发送到serv-0001的处于等待的I/O请求会由serv-0002响应。 在所有服务器中,重启cman服务是配置修改生效:
同样,还需要再所有服务器中重启 rgmanager 和 clvmd 服务:
如果都没问题,那么你就配置好了一个主/从的集群配置。你可以通过查看服务器对共享卷的访问权限来校验配置是否生效。实验应该可以发现,serv-0001 可以挂在共享卷,但是 serv-0002 不可以。接着就是检验真理的时刻了——那就是测试故障转移。手动对 serv-0001 断电,你可以发现rgmanager 影子,并且 serv-0002 可以访问/挂在共享卷了。
注意:为了使所有的相关服务在开机的时候自动启动,用chkconfig命令在合适的运行等级(runlevels)中启动这些服务. 总结对应一个理想的配置,fencing相关的配置必须出现在/etc/cluster/cluster.conf文件中。fencing的目的是在有问题的节点对集群造成显而易见的问题之前就对其进行处理。比如,某台服务器发生Kernel panic,或者无法与集群中的其他服务器通信,再或者遇到其他各种灾难性的崩溃等情况下,可以配置IPMI来重启问题服务器:
HA-LVM的设计初衷是为数据中心提供廉价的容错处理机制。没有人希望服务器当机,话说回来,只有配置得当,当机也不是肯定的。从数据中心到家庭办公,几乎任何场景都可以实施这套方案。 资源链接
clvmd(8): Linux man page Appendix F. High Availability LVM (HA-LVM): https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/6/html/Cluster_Administration/ap-ha-halvm-CA.html
|
 正在加载...
正在加载...