|
你可能对于 Linux 的负载均值(load averages)已有了充分的了解。负载均值在 uptime 或者 top 命令中可以看到,它们可能会显示成这个样子:
load average: 0.09, 0.05, 0.01
很多人会这样理解负载均值:三个数分别代表不同时间段的系统平均负载(一分钟、五 分钟、以及十五分钟),它们的数字当然是越小越好。数字越高,说明服务器的负载越 大,这也可能是服务器出现某种问题的信号。 回答这些问题之前,首先需要了解下这些数值背后的些知识。我们先用最简单的例子说明, 一台只配备一块单核处理器的服务器。 行车过桥一只单核的处理器可以形象得比喻成一条单车道。设想下,你现在需要收取这条道路的过桥 费 — 忙于处理那些将要过桥的车辆。你首先当然需要了解些信息,例如车辆的载重、以及 还有多少车辆正在等待过桥。如果前面没有车辆在等待,那么你可以告诉后面的司机通过。 如果车辆众多,那么需要告知他们可能需要稍等一会。 因此,需要些特定的代号表示目前的车流情况,例如:
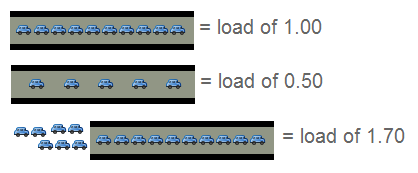
上面的情况和处理器的负载情况非常相似。一辆汽车的过桥时间就好比是处理器处理某线程 的实际时间。Unix 系统定义的进程运行时长为所有处理器内核的处理时间加上线程 在队列中等待的时间。 和收过桥费的管理员一样,你当然希望你的汽车(操作)不会被焦急的等待。所以,理想状态 下,都希望负载平均值小于 1.00 。当然不排除部分峰值会超过 1.00,但长此以往保持这 个状态,就说明会有问题,这时候你应该会很焦急。 「所以你说的理想负荷为 1.00 ?」嗯,这种情况其实并不完全正确。负荷 1.00 说明系统已经没有剩余的资源了。在实际情况中 ,有经验的系统管理员都会将这条线划在 0.70:
那么多个处理器呢?我的均值是 3.00,但是系统运行正常!哇喔,你有四个处理器的主机?那么它的负载均值在 3.00 是很正常的。 在多处理器系统中,负载均值是基于内核的数量决定的。以 100% 负载计算,1.00 表示单个处理器,而 2.00 则说明有两个双处理器,那么 4.00 就说明主机具有四个处理器。
回到我们上面有关车辆过桥的比喻。1.00 我说过是「一条单车道的道路」。那么在单车道 1.00 情况中,说明这桥梁已经被车塞满了。而在双处理器系统中,这意味着多出了一倍的 负载,也就是说还有 50% 的剩余系统资源 — 因为还有另外条车道可以通行。 所以,单处理器已经在负载的情况下,双处理器的负载满额的情况是 2.00,它还有一倍的资源可以利用。 多核与多处理器先脱离下主题,我们来讨论下多核心处理器与多处理器的区别。从性能的角度上理解,一台主 机拥有多核心的处理器与另台拥有同样数目的处理性能基本上可以认为是相差无几。当然实际 情况会复杂得多,不同数量的缓存、处理器的频率等因素都可能造成性能的差异。 但即便这些因素造成的实际性能稍有不同,其实系统还是以处理器的核心数量计算负载均值 。这使我们有了两个新的法则:
审视我们自己让我们再来看看 uptime 的输出 ~ $ uptime23:05 up 14 days, 6:08, 7 users, load averages: 0.65 0.42 0.36 这是个双核处理器,从结果也说明有很多的空闲资源。实际情况是即便它的峰值会到 1.7,我也从来没有考虑过它的负载问题。 那么,怎么会有三个数字的确让人困扰。我们知道,0.65、0.42、0.36 分别说明上一分钟、最后五分钟以及最后十五分钟的系统负载均值。那么这又带来了一个问题:
其实对于这些数字我们已经谈论了很多,我认为你应该着眼于五分钟或者十五分钟的平均数 值。坦白讲,如果前一分钟的负载情况是 1.00,那么仍可以说明认定服务器情况还是正常的。 但是如果十五分钟的数值仍然保持在 1.00,那么就值得注意了(根据我的经验,这时候你应 该增加的处理器数量了)。
在 Linux 下,可以使用 cat /proc/cpuinfo 获取你系统上的每个处理器的信息。如果你只想得到数字,那么就使用下面的命令: grep 'model name' /proc/cpuinfo | wc -l (责任编辑:IT) |