|
1.inode 1).inode简介 inode 是 UNIX/Linux 操作系统中的一种数据结构,其本质是结构体,它包含了与文件系统中各个文件相关的一些重要信息,例如文件及目录的基本信息,包含时间、档名、使用者及群组等。在 UNIX/Linux中创建文件系统时,同时将会创建大量的 inode 。通常,文件系统磁盘空间中大约百分之一空间分配给了 inode 表。在Linux系统中,内核为每一个新创建的文件分配一个Inode(索引结点),每个文件都有一个惟一的inode号,我们可以将inode简单理解成一个指针,它永远指向本文件的具体存储位置。文件属性保存在索引结点里,在访问文件时,索引结点被复制到内存在,从而实现文件的快速访问。系统是通过索引节点(而不是文件名)来定位每一个文件。 2).inode内容 Block 是记录文件内容数据的区域,至于 inode 则是记录"该文件的相关属性,以及文件内容放置在哪一个 Block 之内"的信息,换句说, inode 除了记录文件的属性外,同时还必须要具有指向( pointer )的功能,亦即指向文件内容放置的区块之中,好让操作系统可以正确的去取得文件的内容,底下几个是 inode 记录的信息(当然不止这些):
inode结构体很大这里仅给出几个重要成员 struct inode { //........ unsigned long i_ino; //节点号 atomic_t i_count; //引用计数 //........ uid_t i_uid; //使用者id gid_t i_gid; //使用者id组 //........ struct timespec i_atime; //最后访问时间 struct timespec i_mtime; //最后修改(modify)时间 struct timespec i_ctime; //最后改变(change)时间 unsigned long i_blocks; //文件的块数 unsigned short i_bytes; //使用的字节数 unsigned long i_state; //状态标志 struct list_head i_devices; //块设备链表 unsigned char i_sock; //是否套接字 atomic_t i_writecount; //写者计数 //........ }; 4).关于inode与dataarea inode table是data area的索引表,data Area中存放真正的数据。 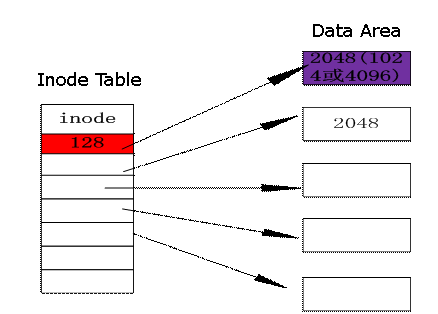
a. linux FS 可以简单分成 inode table与data area两部份。inode table上有许多的inode, 每个inode分别记录一个档案的属性与这个档案分布在哪些datablock上 b. inode table中红色区域即inode size,是128Byte,在liunx系统上通过命令我们可以看到,系统就是这么定义的,Inode size是指分配给一个inode来记录文档属性的磁盘块的大小。 c. data ares中紫色的区域block size,就是我们一般概念上的磁盘块。这块区域是我们用来存放数据的地方。 d. 还有一个逻辑上的概念:FS中每分配2048 byte给data area, 就分配一个inode。但一个inode就并不一定就用掉2048 byte, 也不是说files allocation的最小单位是2048 byte, 它仅仅是代表filesystem中inode table/data area分配空间的比例是128/2048,也就是1/16。 e. inode参数是可以通过mkfs.ext3命令改变 http://jixiuf.github.com/Linux/ext2.html#sec-2-1 注意: i-node 是标记文件中数据快存储位置的指针,一个I-NODE中能标记的数据快的个数是固定的,当文件很小时,一个文件对应一个I-node ,当文件比较大时一个文件对应多个I-NODE,一个inode对应一个文件,但文件可以有多个inode。是1:n的关系。 2.dentry 1)dentry简介 dentry是Linux文件系统中某个索引节点(inode)的链接,每个dentry代表路径中的一个特定部分。这个索引节点可以是文件,也可以是目录。inode(可理解为ext2 inode)对应于物理磁盘上的具体对象,dentry是一个内存实体,没有对应的磁盘数据结构,VFS根据字符串形式的路径名现场创建他,在dentry中,d_inode成员指向对应的inode。也就是说,一个inode可以在运行的时候链接多个dentry,而d_count记录了这个链接的数量。另外dentry对象有三种状态:被使用,未被使用和负状态。 2).dentry的结构体 struct dentry { atomic_t d_count; //目录项对象使用计数器,可以有未使用态,使用态和负状态 unsigned int d_flags; //目录项标志 struct inode *d_inode; //与文件名关联的索引节点 struct dentry *d_parent; //父目录的目录项对象 struct list_head d_hash; //散列表表项的指针 struct list_head d_lru; //未使用链表的指针 struct list_head d_child; //父目录中目录项对象的链表的指针 struct list_head d_subdirs; //对目录而言,表示子目录目录项对象的链表 struct list_head d_alias; //相关索引节点(别名)的链表 int d_mounted; //对于安装点而言,表示被安装文件系统根项 struct qstr d_name; //文件名 unsigned long d_time; /* used by d_revalidate */ struct dentry_operations *d_op; //目录项方法 struct super_block *d_sb; //文件的超级块对象 vunsigned long d_vfs_flags; void *d_fsdata; //与文件系统相关的数据 unsigned char d_iname [DNAME_INLINE_LEN]; //存放短文件名 };
下面给出进一步的解释
一个有效的dentry结构必定有一个inode结构,这是因为一个目录项要么代表着一个文件,要么代表着一个目录,而目录实际上也是文件。所以,只要dentry结构是有效的,则其指针d_inode必定指向一个inode结构。可是,反过来则不然,一个inode却可能对应着不止一个dentry结构;也就是说,一个文件可以有不止一个文件名或路径名。这是因为一个已经建立的文件可以被连接(link)到其他文件名。所以在inode结构中有一个队列i_dentry,凡是代表着同一个文件的所有目录项都通过其dentry结构中的d_alias域挂入相应inode结构中的i_dentry队列。
在内核中有一个哈希表dentry_hashtable ,是一个list_head的指针数组。一旦在内存中建立起一个目录节点的dentry 结构,该dentry结构就通过其d_hash域链入哈希表中的某个队列中。
内核中还有一个队列dentry_unused,凡是已经没有用户(count域为0)使用的dentry结构就通过其d_lru域挂入这个队列。 Dentry结构中除了d_alias 、d_hash、d_lru三个队列外,还有d_vfsmnt、d_child及d_subdir三个队列。其中d_vfsmnt仅在该dentry为一个安装点时才使用。另外,当该目录节点有父目录时,则其dentry结构就通过d_child挂入其父节点的d_subdirs队列中,同时又通过指针d_parent指向其父目录的dentry结构,而它自己各个子目录的dentry结构则挂在其d_subdirs域指向的队列中。 从上面的叙述可以看出,一个文件系统中所有目录项结构或组织为一个哈希表,或组织为一颗树,或按照某种需要组织为一个链表,这将为文件访问和文件路径搜索奠定下良好的基础。 3.file 1)文件对象和file简介 文件对象表示进程已打开的文件,该对象file(不是物理文件)由相应的open()系统调用创建,有close()系统调用销毁,因为多个进程可以同时打开和操作一个文件,所以同一个文件也可能存在多个对应的文件对象。文件对象仅仅在进程观点上代表已打开文件,它反过来指向目录项对象(反过来指向索引节点),其实只有目录项对象才表示已打开的实际文件,虽然一个文件对应的文件对象不是是唯一的,但对应的索引节点和目录项对象无疑是唯一的,另外类似于目录项对象,文件对象实际上没有对应的磁盘数据。 一个文件对象是由一个文件结构体表示的,文件结构体代表一个打开的文件,系统中的每个打开的文件在内核空间都有一个关联的 struct file。它由内核在打开文件时创建,并传递给在文件上进行操作的任何函数。在文件的所有实例都关闭后,内核释放这个数据结构。 2)file的结构体 struct file { union { struct list_head fu_list; //文件对象链表指针linux/include/linux/list.h struct rcu_head fu_rcuhead; //RCU(Read-Copy Update)是Linux 2.6内核中新的锁机制 } f_u; struct path f_path; //包含dentry和mnt两个成员,用于确定文件路径 #define f_dentry f_path.dentry //f_path的成员之一,当前文件的dentry结构 #define f_vfsmnt f_path.mnt //表示当前文件所在文件系统的挂载根目录 const struct file_operations *f_op; //与该文件相关联的操作函数 atomic_t f_count; //文件的引用计数(有多少进程打开该文件) unsigned int f_flags; //对应于open时指定的flag mode_t f_mode; //读写模式:open的mod_t mode参数 off_t f_pos; //该文件在当前进程中的文件偏移量 struct fown_struct f_owner; //该结构的作用是通过信号进行I/O时间通知的数据。 unsigned int f_uid, f_gid; //文件所有者id,所有者组id struct file_ra_state f_ra; //在linux/include/linux/fs.h中定义,文件预读相关 unsigned long f_version; //记录文件的版本号,每次使用后都自动递增。 #ifdef CONFIG_SECURITY void *f_security; //用来描述安全措施或者是记录与安全有关的信息。 #endif /* needed for tty driver, and maybe others */ void *private_data; //可以用字段指向已分配的数据 #ifdef CONFIG_EPOLL /* Used by fs/eventpoll.c to link all the hooks to this file */ struct list_head f_ep_links; 文件的事件轮询等待者链表的头, spinlock_t f_ep_lock; f_ep_lock是保护f_ep_links链表的自旋锁。 #endif /* #ifdef CONFIG_EPOLL */ struct address_space *f_mapping; 文件地址空间的指针 }; 4.files_struct 1).用户打开文件表和files_struct简介 每个进程用一个files_struct结构来记录文件描述符的使用情况,这个files_struct结构称为用户打开文件表,它是进程的私有数据, 2)files_struct的结构体 struct files_struct { atomic_t count; /* 共享该表的进程数 */ rwlock_t file_lock; /* 保护该结构体的锁*/ int max_fds; /*当前文件对象的最大数*/ int max_fdset; /*当前文件描述符的最大数*/ int next_fd; /*已分配的文件描述符加1*/ struct file ** fd; /* 指向文件对象指针数组的指针 */ fd_set *close_on_exec; /*指向执行exec()时需要关闭的文件描述符*/ fd_set *open_fds; /*指向打开文件描述符的指针*/ fd_set close_on_exec_init; /* 执行exec()时关闭的初始文件*/ fd_set open_fds_init; /*文件描述符的初值集合*/ struct file * fd_array[32]; /* 文件对象指针的初始化数组*/ }; 下面给出一部分解释 fd域指向文件对象的指针数组。该数组的长度存放在max_fds域中。通常,fd域指向files_struct结构的fd_array域,该域包括32个文件对象指针。如果进程打开的文件数目多于32,内核就分配一个新的、更大的文件指针数组,并将其地址存放在fd域中;内核同时也更新max_fds域的值。 对于在fd数组中有入口地址的每个文件来说,数组的索引就是文件描述符(file descriptor)。通常,数组的第一个元素(索引为0)是进程的标准输入文件,数组的第二个元素(索引为1)是进程的标准输出文件,数组的第三个元素(索引为2)是进程的标准错误文件。请注意,借助于dup()、dup2()和 fcntl ) 系统调用,两个文件描述符就可以指向同一个打开的文件,也就是说,数组的两个元素可能指向同一个文件对象。当用户使用shell结构(如2>&1)将标准错误文件重定向到标准输出文件上时,用户总能看到这一点。 open_fds域包含open_fds_init域的地址,open_fds_init域表示当前已打开文件的文件描述符的位图。max_fdset域存放位图中的位数。由于数据结构fd_set有1024位,通常不需要扩大位图的大小。不过,如果确实必须的话,内核仍能动态增加位图的大小,这非常类似文件对象的数组的情形。 当开始使用一个文件对象时调用内核提供的fget()函数。这个函数接收文件描述符fd作为参数,返回在current->files->fd[fd]中的地址,即对应文件对象的地址,如果没有任何文件与fd对应,则返回NULL。在第一种情况下,fget()使文件对象引用计数器f_count的值增1。 ----------------------------- 用户打开文件表files_structs是由进程描述符task_struct中的file域指向,所有与进程相关的信息如打开的文件及文件描述符都包含其中,又从前面可以看出,files_struct通过**file保持对文件对象file的访问,于此相似文件对象file的结构体内成员中包含目录项dentry,目录项dentry将文件名与inode相连,最终通过inode中的指针可以访问存储实际的数据的地方Data Area. so他们管理层次关系关系如下:进程->task_struct->files_struct->file->dentry->inode->Data Area 如下图 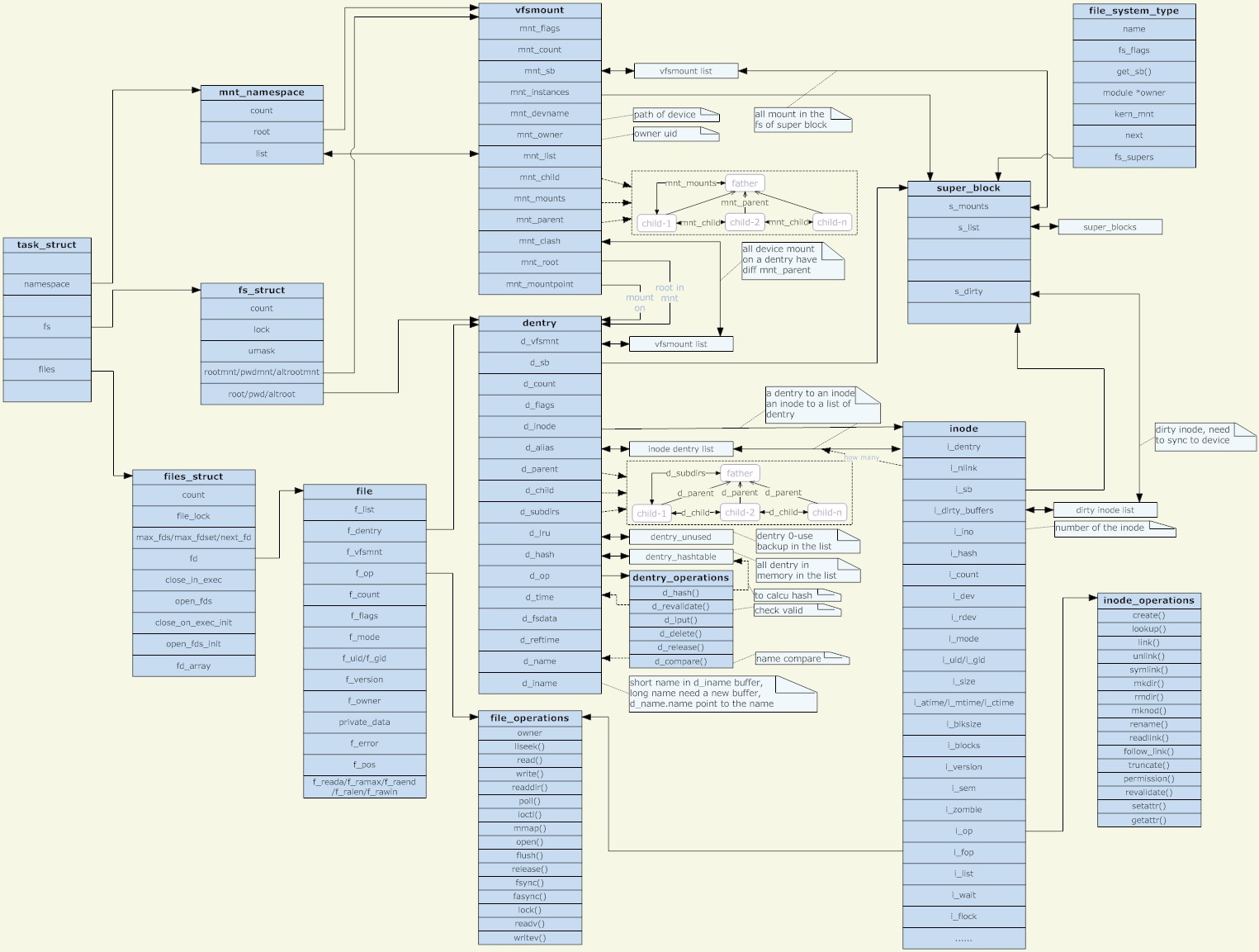
----------------------------- 5.硬链接与软链接 1)硬链接 由于linux下的文件是通过索引节点(inode)来识别文件,硬链接可以认为是一个指针,指向原文件inode的指针,系统并不为它重新分配inode和创建文件;即硬链接文件和原文件其实是同一个文件,只是名字不同。每添加一个硬链接,文件inode的链接数就加1;删除一个硬链接,inode的链接数减1,文件内容依然存在,直到inode的链接数为0,才删除inode对应的文件。 特点:硬链接只能引用同一文件系统中的文件。它引用的是文件在文件系统中的物理索引(也称为inode)。当移动或删除原始文件时,硬链接不会被破坏,因为它所引用的是文件的物理数据而不是文件在文件结构中的位置。硬链接的文件不需要用户有访问原始文件的权限,也不会显示原始文件的位置,这样有助于文件的安全。如果删除的文件有相应的硬链接,那么这个文件依然会保留,直到所有对它的引用都被删除。 可以用ln命令来建立硬链接。语法: ln [options] existingfile newfile ln [options] existingfile-list directory 用法:
2)软链接 软链接也叫符号链接,它是指向另一个文件的特殊文件,这种文件的数据部分仅包含它所要链接文件的路径名。软链接是为了克服硬链接的不足而引入的,软链接不直接使用inode号作为文件指针,而是使用文件路径名作为指针(软链接:文件名+ 数据部分–>目标文件的路径名)。软链接有自己的inode,并在磁盘上有一小片空间存放路径名。因此,软链接能够跨文件系统,也可以和目录链接!其二,软链接可以对一个不存在的文件名进行链接,但直到这个名字对应的文件被创建后,才能打开其链接。 软链接克服了硬链接的不足,没有任何文件系统的限制,任何用户可以创建指向目录的符号链接。因而现在更为广泛使用,它具有更大的灵活性,甚至可以跨越不同机器、不同网络对文件进行链接,如同Windows下的快捷方式。 可以用:ln -s 命令来建立软链接: ln -s existingfile newfile ln -s existingfile-list directory 3).两者的区别 软链接与硬链接的区别不仅仅是在概念上,在实现上也是不同的,整理如下:
当然软链接也有硬链接没有的缺点,因为链接文件包含有原文件的路径信息,所以当原文件从一个目录下移到其他目录中,再访问链接文件,系统就找不到了,而硬链接就没有这个缺陷,想怎么移就怎么移;还有它要系统分配额外的空间用于建立新的索引节点和保存原文件的路径。 (责任编辑:IT) |