|
假设由于某种原因,你需要嗅探HTTP站点的流量(如HTTP请求与响应)。举个例子,你可能在测试一个web服务器的实验性功能,或者你在为某个web应用或RESTful服务排错,又或者你正在为PAC(proxy auto config)排错或寻找某个站点下载的恶意软件。不论什么原因,在这些情况下,进行HTTP流量嗅探对于系统管理、开发者、甚至最终用户来说都是很有帮助的。 数据包嗅工具tcpdump被广泛用于实时数据包的导出,但是你需要设置过滤规则来捕获HTTP流量,甚至它的原始输出通常不能方便的停在HTTP协议层。实时web服务器日志解析器如ngxtop可以提供可读的实时web流量跟踪痕迹,但这仅适用于可完全访问live web服务器日志的情况。
要是有一个仅用于抓取HTTP流量的类似tcpdump的数据包嗅探工具就非常好了。事实上,httpry就是:HTTP包嗅探工具。httpry捕获HTTP数据包,并且将HTTP协议层的数据内容以可读形式列举出来。通过这篇指文章,让我们了解如何使用httpry工具嗅探HTTP流量。 在Linux上安装httpry基于Debian系统(Ubuntu 或 LinuxMint),基础仓库中没有httpry安装包(译者注:本人ubuntu14.04,仓库中已有包,可直接安装)。所以我们需要通过源码安装:
在Fedora,CentOS 或 RHEL系统,可以使用如下yum命令安装httpry。在CentOS/RHEL系统上,运行yum之前使其能够访问EPEL repo。
如果你仍想通过基于RPM系统的源码来安装httpry的话,你可以通过这几个步骤实现:
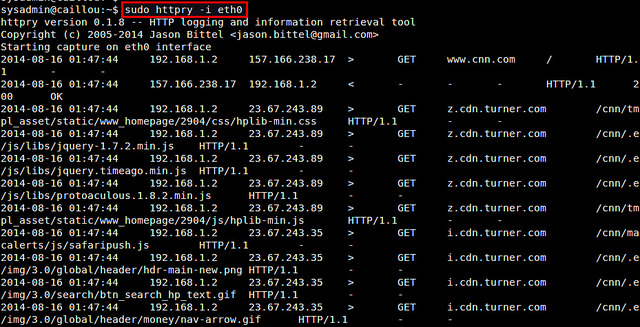
httpry的基本用法以下是httpry的基本用法
httpry就会监听指定的网络接口,并且实时的显示捕获到的HTTP请求/相应。
在大多数情况下,由于发送与接到的数据包过多导致刷屏很快,难以分析。这时候你肯定想将捕获到的数据包保存下来以便离线分析。可以使用'b'或'-o'选项保存数据包。'-b'选项将数据包以二进制文件的形式保存下来,这样可以使用httpry软件打开文件以浏览。另一方面,'-o'选项将数据以可读的字符文件形式保存下来。 以二进制形式保存文件:
浏览所保存的HTTP数据包文件:
注意,不需要根用户权限就可以使用'-r'选项读取数据文件。 将httpry数据以字符文件保存:
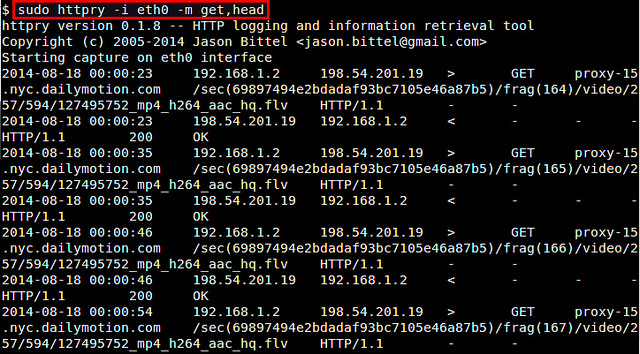
httpry 的高级应用如果你想监视指定的HTTP方法(如:GET,POST,PUT,HEAD,CONNECT等),使用'-m'选项:
如果你下载了httpry的源码,你会发现源码下有一些Perl脚本,这些脚本用于分析httpry输出。脚本位于目录httpry/scripts/plugins。如果你想写一个定制的httpry输出分析器,则这些脚可以作为很好的例子。其中一些有如下的功能:
在使用这些脚本之前,首先使用'-o'选项运行httpry。当获取到输出文件后,立即使用如下命令执行脚本:
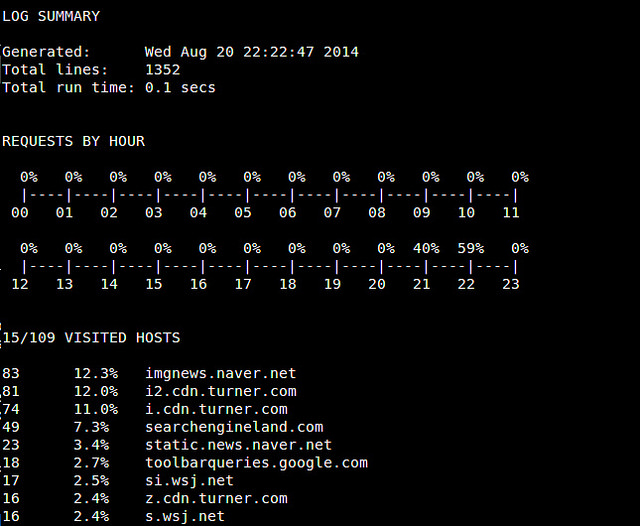
你可能在使用插件的时候遇到警告。比如,如果你没有安装带有DBI接口的MySQL数据库,那么使用db_dump插件时可能会失败。如果一个插件初始化失败的话,那么只是这个插件不能使用,所以你可以忽略那些警告。 当parse_log.pl完成后,你将在httpry/scripts 目录下看到数个分析结果。例如,log_summary.txt 与如下内容类似。
总的来说,当你要分析HTTP数据包的时候,httpry非常有用。它可能并不被大多Linux使用者所熟知,但会用总是有好处的。你觉得这个工具怎么样呢? via: http://xmodulo.com/2014/08/sniff-http-traffic-command-line-linux.html (责任编辑:IT) |