|
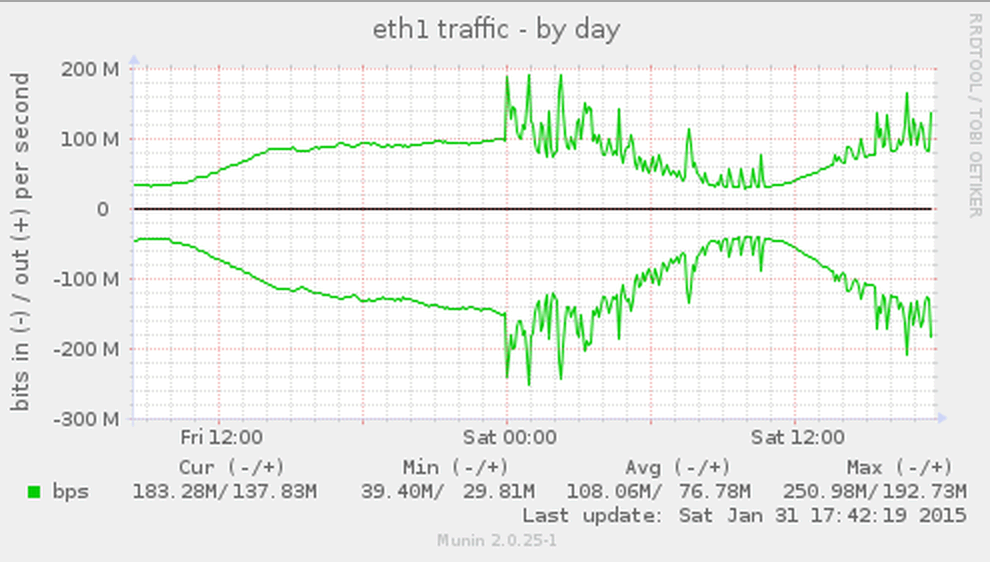
几周前,我们开始注意位于华盛顿的追踪API的服务器网络流量有很大的变化。从一个相当稳定的日常模式下,我们开始看到300-400 Mbps尖峰流量,但我们的合法的流量(事件和人为更新)是不变的。
突然,我们的网络流量开始飙升像疯了似的。
找到虚假的流量来源是当务之急,因为这些尖峰流量正触发我们的上游路由器启动DDOS减灾模式来阻止流量。 有一些很好的内置的Linux工具帮助诊断网络问题。
解决问题的线索是使用netstat -s命令的输出。 不幸的是,当你检查这个命令的输出的时候,还很难告诉这些数字意味着什么,应该是什么,以及它们是如何改变的。为了检查他们是如何变化的,我们创建了一个小程序来显示连续运行命令的输出,这让我们了解各种计数器变化的快慢。一个输出线看起来特别令人担忧。 此计数器的通常速率在未受影响的服务器上一般是 30-40 /秒,所以我们知道肯定是哪里出问题了。计数器表明我们正拒绝大量的包,因为这些包含有无效的 TCP 时间戳。临时的快速解决方案是用下面的命令关闭 TCP 时间戳:
?
这立即导致了包风暴停止。但是这不是一个永久性的解决方案,因为 TCP 时间戳是用于测量往返时间和分配数据包流中的延迟包到正确位置。在高速连接的时候这将成为一个问题,TCP 序列号可能在数秒间隔内缠绕。关于 TCP 的时间戳和性能的详细信息,请看 RFC 1323。 在 Mixpanel,每当我们看到异常流量模式的时候,我们一般也运行 tcpdump,这样我们能够分析流量,然后试图确定根本原因。我们发现大量的 TCP ACK 数据包在我们的 API 服务器和一个特定的 IP 地址之间来回发送。结果我们的服务器陷入到向另一台服务器来来回回发送 TCP ACK 包的无限循环里面。一个主机持续地发出 TCP 时间戳,但是另一主机却不能识别这是有效的时间戳。
这时,我们意识到我们正在处理一个只能在 Linux 内核的 TCP 协议栈才能解决问题。所以我们的 CTO求助于 linux-netdev 看看是否能找到一个解决方案。值得庆幸的是我们发现这个问题已经遇到过的,并且有一个解决方案。原来,这种类型的包风暴可以由一些硬件故障或第三方改变 TCP SEQ,ACK,或连接中的主机认为对方发送过期的数据包所触发。避免让这种情况变成一个包风暴的方法是限制速度,设置 Linux 发送重复的 ACK 数据包速度为每秒一个或两个。这里有一个非常好的解释。 我们将接受这个补丁而且将之移植到当前正在使用的Ubuntu(Trusty)内核当中。感谢Ubuntu让这一切变得非常简单,重新编译修补过的内核仅仅只需要运行下面的命令,安装生成的.deb包并重启系统。
|