|
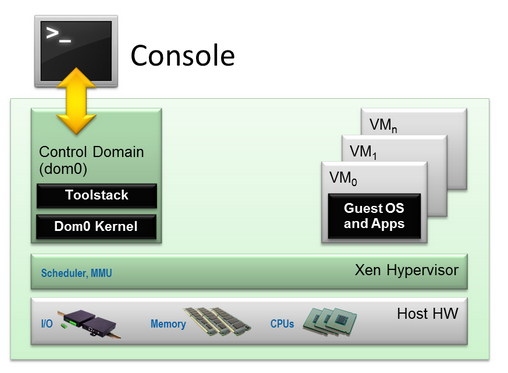
дкxenЯЕЭГжаЃЌДцдквЛИіЧсСПМЖЕФШэМўВуЃЌЯђдЫаадкЫќжЎЩЯЕФащФтЛњЬсЙЉащФтгВМўзЪдДЃЌЭЌЪБЗжХфКЭЙмРэетаЉзЪдДЃЌВЂБЃжЄащФтЛњжБМфЯрЛЅИєРыЃЌетбљЕФШэМўВувЛАуГЦЮЊащФтЛњМрЪгЦї(VMM)ЃЌдкxenжаБЛГЦЮЊhypervisorЃЌМђГЦxenЃЌащФтЛњБЛГЦЮЊdomainЁЃhypervisorЮЛгкВйзїЯЕЭГКЭгВМўжЎМфЃЌЮЊЦфжЎЩЯдЫааЕФВйзїЯЕЭГЬсЙЉащФтЛЏЕФгВМўЛЗОГЃЌxenВЩгУЛьКЯФЃЪНЃЌвђДЫдкxenжаДцдквЛИіdomainРДИЈжњxenЙмРэЦфЫћdomainЃЌетИіЬиШЈЕФdomianГЦЮЊdom0ЃЌЖјЦфЫћБЛЙмРэЕФdomianГЦЮЊdomUЃЌМђЕЅЕФШчЯТЭМЫљЪОЃК
xenЯђdomainЬсЙЉвЛИіГщЯѓВуЃЌЬсЙЉИїжжapiНгПкЃЌЦфжаdom0КЌгадЩњЩшБИЧ§ЖЏвВОЭЪЧецЪЕЕФЩшБИЧ§ЖЏЃЌПЩвджБНгЗУЮЪЮяРэгВМўЃЌdom0ЭЈЙ§xenЬсЙЉЕФapiРДНјааНЛЛЅЃЌЭЈЙ§ПижЦНгПкЙмРэЦфЫћdomUЁЃдкxenжаЃЌxenЯђdomainЬсЙЉСЫЛљБОЕФащФтгВМўКЭЪТМўЭЈЕРЃЌЭЌЪБЯђdom0ЬсЙЉСЫащФтгђЙмРэapiНгПкЃЌЪЙdom0ФмЙЛРћгУдкгУЛЇПеМфЕФЙмРэЙЄОпЙмРэЦфЫћdomUЃЌЖдгкdomUЖдЩшБИЕФЗУЮЪЃЌxenЬсЙЉСЫЯргІЕФгВМўНгПкЃЌвдБЃжЄЩшБИЗУЮЪАВШЋНјааЁЃ xenЕФПижЦНгПкжЛФмБЛdom0ЪЙгУЃЌЪЙdom0ЙмРэЦфЫћdomUЃЌdom0ПЩвдЭЈЙ§ПижЦНгПкДДНЈЁЂЯњЛйdomUЕШЃЌЛЙФмЪЕЯжИїжжcpuЕїЖШЁЂФкДцЗжХфЕШЁЃxenЕФАВШЋгВМўНгПкдђвЊЭъГЩCPUЁЂMMUжЎЭтЫљгаЕФгВМўащФтЙЄзїЃЌАВШЋгВМўНгПкжЛФмБЛгЕгадЩњЧ§ЖЏЕФdomЪЙгУ(dom0ЁЂIDD)ЃЌЯђЦфЫћdomUНіЬсЙЉащФтгВМўЗўЮёЁЃетИіЙ§ГЬЪЧНЈСЂдкгЕгадЩњЧ§ЖЏЕФdomКЭЦфЫћdomжЎМфЕФЩшБИЭЈЕРЭъГЩЕФЁЃЩшБИЭЈЕРЪЧгЩЪТМўЭЈЕРКЭЙВЯэФкДцЪЕЯжЕФЁЃЦфЫћdomUЭЈЙ§ЩшБИЭЈЕРЯђгЕгадЩњЧ§ЖЏЕФdomЬсНЛвьВНIOЧыЧѓЃЌдйгЩгЕгадЩњЧ§ЖЏЕФdomЭЈЙ§АВШЋгВМўНгПкЭъГЩIOЧыЧѓЁЃ ЮЊСЫЪЙdomUжаЕФгІгУГЬађФмЙЛе§ГЃжДааЃЌxenЮЊУПИіdomНЈСЫvcpuНсЙЙЃЌгУРДНгЪмdomUДЋЕнЕФжИСюЃЌЦфжаДѓВПЗжжИСюЖМБЛvcpuжБНгНЛИјЮяРэcpuжДааЃЌЖјЖдгкЬиШЈжИСюКЭСйНчжИСюдђашвЊОЙ§ШЗШЯКѓгЩxenДњЮЊжДааЁЃЖјащФтMMUгУРДАяжњdomUЭъГЩЕижЗзЊЛЏЃЌМДгЩащФтЕижЗЕНЛњЦїЕижЗЕФзЊЛЛЁЃЪТМўЭЈЕРгУгкdomКЭxenжЎМфЁЂdomКЭdomжЎМфЕФвЛжжвьВНЪТМўЭЈжЊЛњжЦЃЌгУгкДІРэdomUЕФащФтжаЖЯЁЂЮяРэжаЖЯвдМАdomжЎМфЕФЭЈбЖЁЃЩшБИЙмРэЦївВЪЧДцдкгкdom0жаЃЌИКд№дкdomЦєЖЏЪБМгдиЬиЖЈЕФЩшБИЧ§ЖЏЁЂНЈСЂЭЈЕРЕШЁЃПижЦУцАхдкdom0жаЭЌxenжаЕФПижЦНгПкНЛЛЅЃЌЭъГЩЖдећИіxenЯЕЭГЕФЙмРэЙЄзїЁЃдЩњЧ§ЖЏЪЧжИдРДВйзїЯЕЭГЯЕЭГЪЙгУЕФецЪЕЕФЩшБИЧ§ЖЏЃЌдкxenжажЛгаОЙ§ЪкШЈЕФdomВХФмЪЙгУдЩњЧ§ЖЏЗУЮЪецЪЕЕФгВМўЩшБИЁЃЮЛгкЦфЫћdomжаЕФЧАЖЫЧ§ЖЏНЋIOЧыЧѓЗЂЫЭИјЮЛгкdom0жаЕФКѓЖЫЧ§ЖЏЃЌКѓЖЫЧ§ЖЏНгЪмIOЧыЧѓЃЌШЛКѓЬсНЛдЩњЧ§ЖЏНјааДІРэЁЃ
ећИіМмЙЙЬхЯЕШчЯТЭМЃК
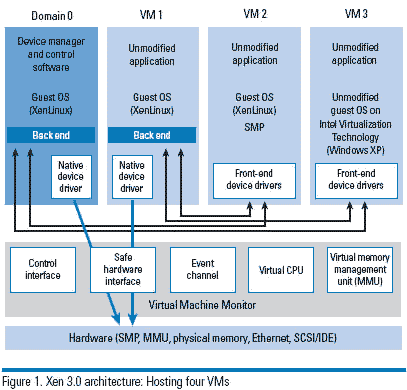 xen3.0 в§ШыСЫгВМўащФтЛЏММЪѕЃЌЪЙxenПЩвджЇГжВЛаоИФФкКЫЕФdomUЃЌдЫааЮДаоИФФкКЫЕФащФтЛњГЦЮЊгВМўащФтЛњ(HVM)ЃЌвђДЫxenЩЯЕФгђгаЫФжжЃКЬиШЈгђdom0ЁЂЖРСЂЩшБИЧ§ЖЏгђIDDЁЂгВМўащФтгђHVMЁЂЗЧЬиШЈгђdomUЁЃ Dom0дкxenжаЪЧЖРвЛЮоЖўЕФЃЌdom0жаКЌгадЩњЧ§ЖЏЃЌПЩвджБНгЗУЮЪгВМўЩшБИЃЌВЂЭЈЙ§ПижЦНгПкРДЭъГЩЖдЦфЫћгђЕФЙмРэЙЄзїЃЌdom0ЛЙПЩвдЖдЦфЫћdomНјааЩшБИЗУЮЪЕФЪкШЈЃЌетаЉОЙ§ЪкШЈЕФdomФмЙЛЗУЮЪдЩњЧ§ЖЏЫљФмЗУЮЪЕФВПЗжецЪЕгВМўЩшБИЁЃ IDDЃЌдкxenжЛгавЛИіЬиШЈгђdom0ЃЌЫљгагВМўЩшБИЖМБЛdom0дЫааЕФЯЕЭГПижЦЃЌЕЋетгаКмДѓЕФЮЪЬтЃЌШчЙћdom0ЕФЯЕЭГжаФГИіЧ§ЖЏАќКЌТЉЖДЃЌФЧОЭПЩФмЖдећИіdom0ФкКЫв§ШывўЛМЃЌДгЖјЕМжТећИіЯЕЭГБРРЃЃЌвђДЫЃЌНЋЩшБИЧ§ЖЏгЩdom0жаЧЈвЦЕНСэвЛИігђжаЃЌвЛЗНУцНЕЕЭdom0ЕФИКдиЃЌСэвЛЗНУцвВПЩвдНЕЕНЯЕЭГЕФЗчЯеЁЃетаЉОЙ§dom0ЪкШЈЕФЃЌПЩвдЪЙгУЬиЖЈЩшБИЧ§ЖЏЕФащФтгђГЦЮЊIDDЃЌIDDГ§СЫЬсЙЉЩшБИЧ§ЖЏЭтВЛзіЦфЫћЪТЧщЁЃ HVMЃЌxen3жЇГждЫааЮДаоИФФкКЫЕФOSЃЌеташвЊcpuжЇГжЃЌР§ШчЃКVT-XКЭAMD-VММЪѕЁЃгЩгкHVMУЛгааоИФФкКЫЃЌЫљвдguest OSВЛФмжЇГжxenдкАыащФтЛЏЯТВЩгУЕФЗжРыЩшБИЧ§ЖЏФЃаЭЁЃxenБиаыФЃФтГіguest OSФмЙЛжЇГжЕФЛЗОГЃЌСэЭтвЛАуdomUжаЕФguest OSЭЈЙ§ЪЙгУФкДцжаЕФЙмРэГЬађЬсЙЉЕФвЛЖЮв§ЕМаХЯЂЃЌдкБЃЛЄФЃЪНЯТв§ЕМЃЌЖјдкHVMжаguest OSдђЪЧДгЪЕФЃЪНв§ЕМЃЌВЂДгФЃЪНЕФBISOжаЖСШЁХфжУаХЯЂЁЃ DomUЃЌбЯИёРДЫЕГ§СЫdom0жЎЭтЕФЫљгагђЖМЪЧdomUЃЌЕЋЪЧIDDОЙ§ЪкШЈКѓФмЙЛжБНгЪЙгУЮяРэЩшБИЧ§ЖЏЃЌвђЖјIDDвВЪєгкЬиШЈгђЁЃЮоТлЪЧHVMЛЙЪЧdomUЖМВЛФмжБНгЗУЮЪЮяРэЩшБИЃЌБиаыНшжњdom0ЛђепIDDВХФмЭъГЩЁЃ
ЯТУцЪЧxenжаdomUЕФЗЂАќЙ§ГЬ
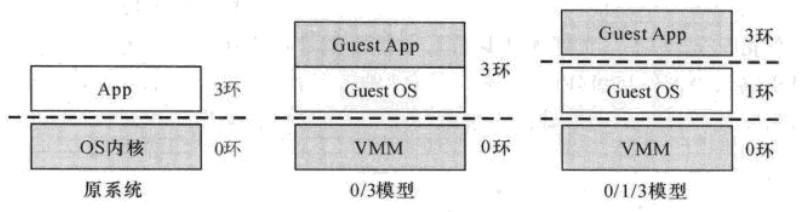
 CPUащФтЛЏ CPUащФтЛЏгжЗжЮЊАыащФтЛЏКЭгВМўащФтЛЏСНжжЃК 1 АыащФтЛЏ дкxenжаЃЌxenДІгкгВМўКЭВйзїЯЕЭГжЎМфЃЌЮЊЦфжЎЩЯЕФdomЬсЙЉащФтЛЏЕФгВМўЛЗОГЃЌетвтЮЖзХxenдкЯЕЭГжагЕгазюИпЕФЬиШЈЕШМЖЃЌЧвxenКЭdomВЛФмДІгкЯрЭЌЕФЕШМЖжаЃЌЫљвдdomОЭБЛЦШЧЈвЦЕННЯЕЭЕФЕШМЖжаЃЌx86МмЙЙЯТЃЌcpuЬсЙЉЫФИіЬиШЈМЖring0~ring3ЃЌ0МЖБ№зюИпЃЌЭЌЪБcpuжЇГжЗжЖЮКЭЗжвГЕФФкДцБЃЛЄЛњжЦЃЌЗжЖЮБЃЛЄЛњжЦжЇГжЫФИіЬиШЈЕШМЖЃЌЖјЗжвГБЃЛЄЛњжЦжЛжЇГжСНИіЬиШЈЕШМЖЃЌМДгУЛЇФЃЪНКЭЙмРэФЃЪНЃЌгУЛЇФЃЪНЯрЕБгкring3ЃЌring0-2дђБЛЛЎЗжЕНЙмРэФЃЪНжаЁЃЕЋЪЧФПЧАЕФДѓЖрЪ§ВйзїЯЕЭГжЛгУЕНСЫСНИіring0КЭring3ЃЌЯЕЭГдЫаадк0ЃЌгІгУГЬађдЫаадк3ЁЃ ащФтЛЏжаДцдкСНжжВЛЭЌЕФЬиШЈНтГ§ЗНЪНЃК0/1/3КЭ0/3ФЃаЭЃЌЖдБШШчЯТЭМЃК
0/1/3КЭ0/3ИїгаИїЕФЬиЕуЃЌ0/3ЮоЗЈдкВйзїЯЕЭГКЭгІгУГЬађжЎМфРћгУЗжвГЛђепЗжЖЮЛњжЦНјааБЃЛЄЃЌ0/1/3ЮоЗЈдкВйзїЯЕЭГКЭVMMжБНгРћгУЗжвГЛњжЦНјааБЃЛЄЃЌжЛФмВЩгУЗжЖЮЛњжЦЁЃxenВЩгУЕФЪЧ0/3ФЃаЭЃЌетОЭашвЊxenНЋВйзїЯЕЭГКЭгУЛЇПеМфИєРыПЊРДЁЃ ЮоТлВЩгУФФжжФЃаЭЃЌxenЖМЬцДњСЫдгаЕФФкКЫЃЌдЫаадкзюИпЬиШЈМЖБ№ЃЌdomЕФcpuПЩвджДаавЛаЉЦеЭЈЕФcpuжИСюЃЌЖдгквЛаЉЮЃЯеЕФЬиШЈжИСюашвЊxenЭЈЙ§ГЌМЖЕїгУЯђdomЬсЙЉжДааетаЉЬиШЈжИСюЕФНгПкЁЃдкдгаЕФМмЙЙЯТЃЌВйзїЯЕЭГЕФЦєЖЏЖМЪЧгЩЪЕФЃЪНЦєЖЏНјШыБЃЛЄФЃЪНЕФЃЌЖјдкxenжаЪЕФЃЪНЕНБЃЛЄФЃЪНЕФзЊЛЛЪЧдкxenжаЭъГЩЕФЃЌЫљвдdomЕФФкКЫЦєЖЏЪБОЭвбОДІгкБЃЛЄФЃЪНЯТЁЃ 2 гВМўащФтЛЏ
дкДѓВПЗжжЛгаСНИіЬиШЈМЖЕФНсЙЙжаЃЌЮЊСЫБмУтВЩгУ0/3ФЃаЭЖјЕМжТВйзїЯЕЭГКЭгІгУГЬађЮЛгкЭЌвЛЬиШЈМЖЯТЃЌетаЉЯЕЭГЖМжЇГжФГжжаЮЪНЕФгВМўащФтЛЏММЪѕЁЃЯЕЭГЭЈЙ§гВМўащФтГівЛИіБШ0 ringИќИпМЖЕФЬиШЈМЖ -1 ringЃЌVMMдђдЫаадк-1 ringЃЌЖјВйзїЯЕЭГШдОЩдЫаадк0 ringжаЃЌетбљПЩвдБЃГжVMMдЫаадкзюИпЬиШЈМЖжаЃЌгжПЩвдЗРжЙВйзїЯЕЭГФкКЫЭЌгУЛЇГЬађдкЭЌвЛИіПеМфжаЁЃVT-XКЭAMD-VВЩгУЕФЛљБОЫМЯыЪЧв§ШыаТЕФжИСюКЭДІРэЦїдЫааФЃЪНЃЌguest OSжЛФмдЫаадкЪмПиФЃЪНЯТЃЌЕБашвЊVMMНјааМрПиКЭФЃФтЪБЃЌгЩгВМўжЇГжФЃЪНЧаЛЛЃЌетбљЕФКУДІЪЧВЛдйашвЊаоИФguest OSЕФФкКЫЃЌЖјЪЧЭЈЙ§гВМўЗНЪНРДЭъГЩгЩдРДШэМўЭъГЩЕФжИСюВЖЛёЁЃ
ФкДцащФтЛЏ
x86ЭЌЪБжЇГжЗжЖЮКЭЗжвГЛњжЦЃЌдкАыащФтЛЏЯТЃЌФкДцЕФЗжЖЮБЃЛЄЛњжЦЃЌЪЙxenКЭguest OSЙВДцгкЭЌвЛИіФкДцЕижЗПеМфжаЃЌМђЛЏСЫxenЖдdomФкДцЕФЗжХфЙмРэЙ§ГЬЃЌРћгУЗжвГЛњжЦЃЌxenФмЙЛБЃЛЄИїИіdomдкФкДцЩЯгааЇИєРыЃЌxenБиаыШЗБЃШЮКЮЕФЗЧЬиШЈdomUВЛЛсЗУЮЪЕНЭЌвЛИіФкДцЧјгђЃЌвђДЫЃЌУПвЛвГЕФИќаТЖМБиаыОЙ§xen ЕФШЗШЯЃЌвдБЃжЄУПИіdomUжЛФмПижЦздМКЕФвГБэЁЃдкЮяРэФкДцЙмРэжаЃЌxenВЩгУСЫЦјЧђЧ§ЖЏРДЕїНкЗжХфИјИїИіdomUЕФФкДцЃЌЦјЧђЧ§ЖЏдЫаадкguest OSжаЃЌguest OSЭЈЙ§ЦјЧђЧ§ЖЏПЩвдКЭxenЭЈбЖЃЌЕБdomUашвЊФкДцЪБЃЌЭЈЙ§ЦјЧђЧ§ЖЏКЭxenЭЈбЖЩъЧыФкДцЃЌxenАбЮДЗжХфЕФФкДцЭЈЙ§ЦјЧђЧ§ЖЏЗжХфИјЬсНЛЧыЧѓЕФdomUЁЃxenЮЊСЫЛиЪеФкДцЃЌОЭЛсЪЙЦјЧђЧ§ЖЏ“ХђеЭ”ЃЌguest OSЮЊСЫИјЦјЧђЗжХфзуЙЛЕФПеМфОЭЛсЛиЪевГУцЪЭЗХФкДцЃЌШЛКѓЦјЧђЧ§ЖЏдйНЋвГУцДЋЕнИјxenЁЃ
IOащФтЛЏ
дкАыащФтЛЏЯТЃЌxenВЩгУЗжРыЩшБИЧ§ЖЏФЃаЭРДЪЕЯжIOащФтЛЏЁЃНЋЩшБИЧ§ЖЏЗжЮЊЃКЧАЖЫЧ§ЖЏЁЂКѓЖЫЧ§ЖЏЁЂдЩњЧ§ЖЏЁЃЧАЖЫЧ§ЖЏдкdomUжаЃЌКѓЖЫЧ§ЖЏКЭдЩњЧ§ЖЏдкdom0КЭIDDжаЁЃЧАЖЫЧ§ЖЏИКд№НЋdomUЕФIOЧыЧѓДЋЕнИјdom0жаЕФКѓЖЫЧ§ЖЏЃЌКѓЖЫЧ§ЖЏНтЮіЪеЕНЕФIOЧыЧѓВЂгГЩфЕНЪЕМЪЮяРэЩшБИЃЌзюКѓНЛИјЫћЕФЩшБИЧ§ЖЏГЬађРДПижЦгВМўЭъГЩIOЧыЧѓЁЃЮЊСЫЪЕЯжДѓСПDMAЪ§ОндкdomUКЭdom0жЎМфИпаЇДЋЕнЃЌxenВЩгУЪкШЈБэЛњжЦЃЌЭЈЙ§жБНгЬцЛЛвГУцгГЩфЙиЯЕРДБмУтВЛБивЊЕФФкДцПНБДЁЃ
(д№ШЮБрМЃКIT) |