|
MapReduce数据处理模型非常简单:map和reduce函数的输入和输出是键/值对(key/value pair)
1.MapReduce的类型 Hadoop的MapReduce一般遵循如下常规格式:
map:对数据进行抽去过滤数据,组织key/value对等操作. combine:为了减少reduce的输入和Hadoop内部网络数据传输负载,需要在map端对输出进行预处理,类似reduce。combine不一定适用任何情况,选用 partition:将中间键值对划分到一个reduce分区,返回分区索引号。实际上,分区单独由键决定(值是被忽略的),分区内的键会排序,相同的键的所有值会合成一个组(list(V2)) reduce:每个reduce会处理具有某些特性的键,每个键上都有值的序列,是通过对所有map输出的值进行统计得来的,reduce根据所有map传来的结果,最后进行统计合并操作,并输出结果。 注:combine与reduce一样时,K3与K2相同,V3与V2相同。
MapReduce的Java API代码:一般Combine函数与reduce的一样的
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { public class Context extends MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { // ... } protected void map(KEYIN key, VALUEIN value, Context context) throws IOException, InterruptedException { // ... }
} public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { public class Context extends ReducerContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { // ... } protected void reduce(KEYIN key, Iterable<VALUEIN> values, Context context) throws IOException, InterruptedException { // ... }
}
用于处理中间数据的partition函数 API代码:
public abstract class Partitioner<KEY, VALUE> { public abstract int getPartition(KEY key, VALUE value, int numPartitions);
}
关于默认的MapReduce作业 默认的map是Mapper,是一个泛型类型,简单的将所有输入的值和键原封不动的写到输出中,即输入输出类型相同。 Mapper的实现
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { protected void map(KEYIN key, VALUEIN value, Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
}
默认的 partitioner是HashPartitioner,对每天记录的键进行哈希操作以决定该记录属于那个分区让reduce处理,每个分区对应一个reducer任务,所以分区数等于Job的reduce的个数 HashPartitioner的实现
public class HashPartitioner<K, V> extends Partitioner<K, V> { public int getPartition(K key, V value, int numReduceTasks) { return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
默认的reduce函数Reducer,也是泛型类型,简单的将所有输入写到输出中。记录在发给reduce之前,会被排序,一般是按照键值的大小排序。reduce的默认输出格式是TextOutputFormat----它将键和值转换成字符串并用Tab进行分割,然后一条记录一行地进行输出。 Reducer 的实现
public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { protected void reduce(KEYIN key, Iterable<VALUEIN> values, Context context) throws IOException, InterruptedException { for (VALUEIN value: values) {
context.write((KEYOUT) key, (VALUEOUT) value);
}
}
}
选择reduce的个数:一般集群的总共的slot个数等于node的数目乘以每个node上的slot数目,而reduce的数目一般设置为比总slot数目少一些 默认MapReduce函数实例程序
public class MinimalMapReduceWithDefaults extends Configured implements Tool {
@Override public int run(String[] args) throws Exception {
Job job = JobBuilder.parseInputAndOutput(this, getConf(), args); if (job == null) { return -1;
}
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(Mapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setPartitionerClass(HashPartitioner.class);
job.setNumReduceTasks(1);
job.setReducerClass(Reducer.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Text.class);
job.setOutputFormatClass(TextOutputFormat.class); return job.waitForCompletion(true) ? 0 : 1;
} public static void main(String[] args) throws Exception { int exitCode = ToolRunner.run(new MinimalMapReduceWithDefaults(), args);
System.exit(exitCode);
}
}
关于默认的stream作业(Stream概念见第二章) stream最简单的形式:
注意,必须提供一个mappe:默认的identity mapp不能在stream工作 这里再给出更多设置的stream形式,其他详见权威指南:
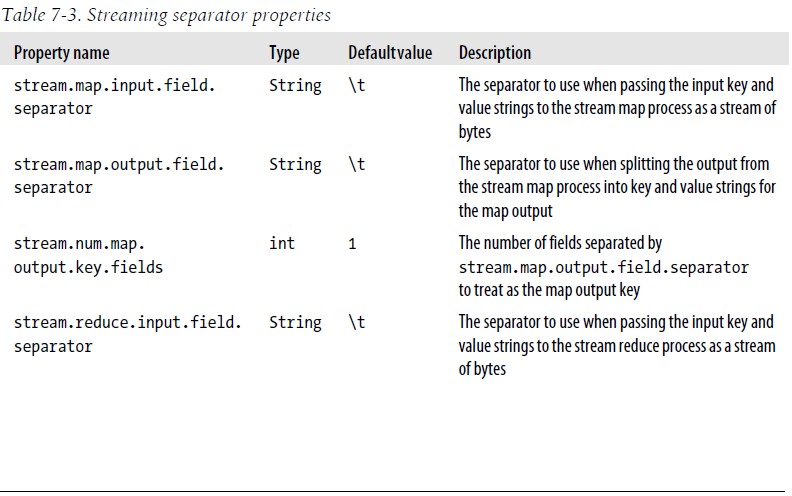
关于Streaming中的键和值 Streaming用分隔符用于通过标准输入把key/value对转换为一串比特发送到map或reduce函数 默认时,用Tab分隔符,也可以根据需要,用配置的分隔符来进行分割,例如:来自输出的键可以由一条记录的前n个字段组成(stream.num.map.output.key.fields或stream.num.reduce.output.key.fields定义),剩下的就是值,eg,输出的是"a,b,c",n=2,则键为"a、b",而值是"c"。Map和Reduce的分隔符是相互独立进行配置的,参见下图
2.输入格式 1).输入分片与记录 一个输入分片(input split)是由单个map处理的输入块,即每一个map只处理一个输入分片,每个分片被划分为若干个记录(records),每条记录就是一个key/value对,map一个接一个的处理每条记录,输入分片和记录都是逻辑的,不必将他们对应到文件上。注意,一个分片不包含数据本身,而是指向数据的引用和。 输入分片在Java中被表示为InputSplit借口
public abstract class InputSplit { public abstract long getLength() throws IOException, InterruptedException; public abstract String[] getLocations() throws IOException,InterruptedException;
}
InputFormat负责创建输入分片并将它们分割成记录,下面就是原型用法:
public abstract class InputFormat<K, V> { public abstract List<InputSplit> getSplits(JobContext context) throws IOException, InterruptedException; public abstract RecordReader<K, V> createRecordReader(InputSplit split,
TaskAttemptContext context) throws IOException,
InterruptedException;
}
客户端通过调用getSpilts()方法获得分片数目,在TaskTracker或NM上,MapTask会将分片信息传给InputFormat的createRecordReader()方法,进而这个方法来获得这个分片的RecordReader,RecordReader基本就是记录上的迭代器,MapTask用一个RecordReader来生成记录的key/value对,然后再传递给map函数,如下代码
public void run(Context context) throws IOException, InterruptedException {
setup(context); while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
cleanup(context);
}
此处的Context实现接口MapContextImpl,并且封装调用RecordReader下面的经过实现的方法,包括nextKeyValue,getCurrentKey,getCurrentValue。nextKeyValue()方法反复被调用用来为mapper生成key/value对,然后把这些key/value传递给map()方法,直到独到stream的末尾,此时nextKeyValue返回false
A.FileInputFormat类 FileInputFormat是所有使用文件为数据源的InputFormat实现的基类,它提供了两个功能:一个定义哪些文件包含在一个作业的输入中;一个为输入文件生成分片的实现,把分片割成记录的作业由其子类来完成。 下图为InputFormat类的层次结构:
B.FileInputFormat类输入路径 FileInputFormat提供四种静态方法来设定Job的输入路径,其中下面的addInputPath()方法addInputPaths()方法可以将一个或多个路径加入路径列表,setInputPaths()方法一次设定完整的路径列表(可以替换前面所设路径) public static void addInputPath(Job job, Path path); public static void addInputPaths(Job job, String commaSeparatedPaths); public static void setInputPaths(Job job, Path... inputPaths); public static void setInputPaths(Job job, String commaSeparatedPaths); 如果需要排除特定文件,可以使用FileInputFormat的setInputPathFilter()设置一个过滤器: public static void setInputPathFilter(Job job, Class<? extends PathFilter> filter);
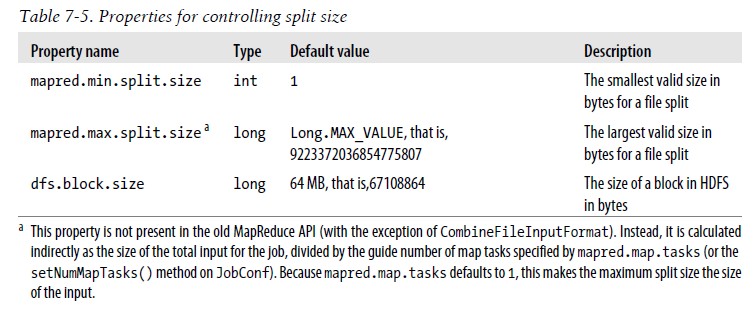
C.FileInputFormat类的输入分片 FileInputFormat类一般之分割超过HDFS块大小的文件,通常分片与HDFS块大小一样,然后分片大小也可以改变的,下面展示了控制分片大小的属性:
这里数据存储在HDFS上的话,输入分片大小不宜设置比HDFS块更大,原因这样会增加对MapTask来说不是本地文件的块数。 最大的分片的大小默认是Java long类型的表示的最大值,这样设置的效果:当它的值被设置成小于块大小时,将强制分片比快小(?) 分片大小公式: 默认情况
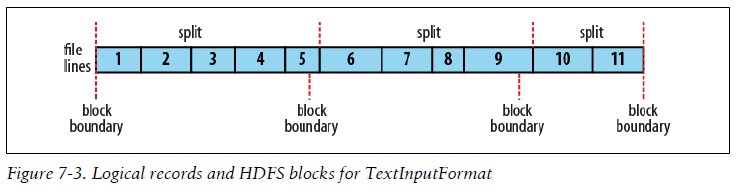
下图距离说明如何控制分片的大小
D.小文件与CombineFileInputFormat CombineFileInputFormat是针对小文件设计的,CombineFileInputFormat会把多个文件打包到一个分片中一边每个mapper可以处理更多的数据;减少大量小文件的另一种方法可以使用SequenceFile将这些小文件合并成一个或者多个大文件。 CombineFileInputFormat不仅对于处理小文件实际上对于处理大文件也有好处,本质上,CombineFileInputFormat使map操作中处理的数据量与HDFS中文件的块大小之间的耦合度降低了 CombineFileInputFormat是一个抽象类,没有提供实体类,所以需要实现一个CombineFileInputFormat具体类和getRecordReader()方法(旧的接口是这个方法,新的接口InputFormat中则是createRecordReader(),似乎3rd权威指南在这个地方有些错误)
E.避免切分 有些应用程序可能不希望文件被切分,而是用一个mapper完整处理每一个输入文件,有两种方法可以保证输入文件不被切分。第一种方法就是增加最小分片大小,将它设置成大于要处理的最大文件大小,eg:把这个值设置为long.MAXVALUE即可。第二种方法就是使用FileInputFormat具体子类,并且重载isSplitable()方法,把其返回值设置为false,如下所示
import org.apache.hadoop.fs.Path; import org.apache.hadoop.mapreduce.JobContext; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; public class NonSplittableTextInputFormat extends TextInputFormat {
@Override protected boolean isSplitable(JobContext context, Path file) { return false;
}
}
F.mapper中的文件信息 处理文件输入分片的mapper可以从文件配置对象的某些特定属性中读入输入分片的有关信息,这可以通过在mapper实现中实现configure()方法来获取作业配置对象JobConf,下图显示了文件输入分片的属性
G.把整个文件作为一条记录处理 有时,mapper需要访问问一个文件中的全部内容。即使不分割文件,仍然需要一个RecordReader来读取文件内容为record的值,下面给出实现这个功能的完整程序,详细解释见权威指南 InputFormat的实现类WholeFileInputFormat
public class WholeFileInputFormat extends FileInputFormat<NullWritable, BytesWritable> {
@Override protected boolean isSplitable(JobContext context, Path file) { return false;
}
@Override public RecordReader<NullWritable, BytesWritable> createRecordReader(
InputSplit split, TaskAttemptContext context) throws IOException,
InterruptedException {
WholeFileRecordReader reader = new WholeFileRecordReader();
reader.initialize(split, context); return reader;
}
}
WholeFileRecordReader的实现:WholeFileInputFormat使用RecordReader将整个文件读为一条记录
class WholeFileRecordReader extends RecordReader<NullWritable, BytesWritable> { private FileSplit fileSplit; private Configuration conf; private BytesWritable value = new BytesWritable(); private boolean processed = false;
@Override public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException { this.fileSplit = (FileSplit) split; this.conf = context.getConfiguration();
}
@Override public boolean nextKeyValue() throws IOException, InterruptedException { if (!processed) { byte[] contents = new byte[(int) fileSplit.getLength()];
Path file = fileSplit.getPath();
FileSystem fs = file.getFileSystem(conf);
FSDataInputStream in = null; try {
in = fs.open(file);
IOUtils.readFully(in, contents, 0, contents.length);
value.set(contents, 0, contents.length);
} finally {
IOUtils.closeStream(in);
}
processed = true; return true;
} return false;
}
@Override public NullWritable getCurrentKey() throws IOException,
InterruptedException { return NullWritable.get();
}
@Override public BytesWritable getCurrentValue() throws IOException,
InterruptedException { return value;
}
@Override public float getProgress() throws IOException { return processed ? 1.0f : 0.0f;
}
@Override public void close() throws IOException { // do nothing }
}
将若干个小文件打包成顺序文件的MapReduce程序
public class SmallFilesToSequenceFileConverter extends Configured implements Tool { static class SequenceFileMapper extends Mapper<NullWritable, BytesWritable, Text, BytesWritable> { private Text filenameKey;
@Override protected void setup(Context context) throws IOException,
InterruptedException {
InputSplit split = context.getInputSplit();
Path path = ((FileSplit) split).getPath();
filenameKey = new Text(path.toString());
}
@Override protected void map(NullWritable key, BytesWritable value,
Context context) throws IOException, InterruptedException {
context.write(filenameKey, value);
}
}
@Override public int run(String[] args) throws Exception {
Job job = JobBuilder.parseInputAndOutput(this, getConf(), args); if (job == null) { return -1;
}
job.setInputFormatClass(WholeFileInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(BytesWritable.class);
job.setMapperClass(SequenceFileMapper.class); return job.waitForCompletion(true) ? 0 : 1;
} public static void main(String[] args) throws Exception { int exitCode = ToolRunner.run(new SmallFilesToSequenceFileConverter(),
args);
System.exit(exitCode);
}
}
由于输入格式为WholeFileInputFormat,所以mapper只需要找到文件输入分片的文件名。
2).文本输入 A.TextInputFormat TextInputFormat是默认的InputFormat。每条记录是一行输入。key是LongWritable类型,存储该行在整个文件中的字节偏移量,value是这行的内容,不包括任何终止符(换行符和回车符),它是Text类型 如下例
每条记录表示以下key/value对
上面的key明显不是行号,因为每个分片需要单独处理的原因,行号只是一个片内的顺序标记,所以在分片内在的行号是可以的,而在文件中是很难办到的。然而为了使key是唯一的,我们可以利用已知的上一个分片的大小,计算出当前位置在整个文件中的偏移量(不是行号),这样加上文件名,就能确定唯一key,如果行固定长,就可以算出行号 PS:因为FileInputFormat定义的是逻辑结构,不能匹配HDFS块大小,所以TextFileInputFormat的以行为单位的逻辑记录中,很有可能某一行是跨文件块存储的,如下所示
B.KeyValueTextInputFormat 对下面的文本,KeyValueTextInputFormat比较适合处理,其中可以通过mapreduce.input.keyvaluelinerecordreader.key.value.separator属性设置指定分隔符,默认值为制表符,以下指定"→"为分隔符
C.NLineInputFormat 如果希望mapper收到固定行数的输入,需要使用NLineInputFormat作为InputFormat。与TextInputFormat一样,key是文件中行的字节偏移量,值是行本身。 N是每个mapper收到的输入行数,默认时N=1,每个mapper会正好收到一行输入,mapreduce.input.lineinputformat.linespermap属性控制N的值。以刚才的文本为例:
例如,如果N=2,则每个输入分片包括两行。第一个mapper会收到前两行key/value对:
另一个mapper则收到:
3).二进制输入 A.SequenceFileInputFormat 如果要用顺序文件数据作为MapReduce的输入,应用SequenceFileInputFormat。key和value顺序文件,所以要保证map输入的类型匹配 虽然从名称看不出来,但是SequenceFileInputFormat可以读MapFile和SequenceFile,如果在处理顺序文件时遇到目录,SequenceFileInputFormat类会认为值正在读MapFile,使用的是其数据文件,因此没有MapFileInputFormat类是自然的
B.SequenceFileAsTextInputFormat和SequenceFileAsBinaryInputFormat 两者均是SequenceFileInputFormat的变体,前者将顺序文件(其实就是SequenceFile)的key和value转成Text对象,后者获取顺序文件的key和value作为二进制对象
4).多种输入 对于不同格式,不同表示的文本文件输出的处理,可以用MultipleInputs类里处理,它允许为每条输入路径指定InputFormat和Mapper,例如,下满对Met Office和NCDC两种不同格式的气象数据放在一起进行处理: MultipleInputs.addInputPath(job, ncdcInputPath,TextInputFormat.class, MaxTemperatureMapper.class); MultipleInputs.addInputPath(job, metOfficeInputPath,TextInputFormat.class, MetOfficeMaxTemperatureMapper.class); 两个数据源的行格式不同,所以使用了两个不同的mapper MultipleInputs类有一个重载版本的addInputPath()方法: public static void addInputPath(Job job, Path path,Class<? extends InputFormat> inputFormatClass) 在有多种输入格式只有一个mapper时候(调用Job的setMapperClass()方法),这个方法会很有用
另外还有一个用于食用JDBC从关系数据库中读取数据的输入格式--DBInputFormat(参见权威指南)
3.输出格式 OutputFormat类的层次结构:
1).文本输出 默认输出格式是TextOutputFormat,它本每条记录写成文本行,key/value任意,这里key和value可以用制表符分割,用mapreduce.output.textoutputformat.separator书信可以改变制表符,与TextOutputFormat对应的输入格式是KeyValueTextInputFormat 可以使用NullWritable来省略输出的key和value。
2).二进制输出 A.SequenceFileOutputFormat SequenceFileOutputFormat将它的输出写为一个顺序文件,因为它的格式紧凑,很容易被压缩,所以易于作为MapReduce的输入
B.SequenceFileAsBinaryOutputFormat和MapFileOutputFormat 前者把key/value对作为二进制格式写到一个SequenceFile容器中,后者把MapFile作为输出,MapFile中的key必需顺序添加,所以必须确保reducer输出的key已经排好序。
3).多个输出--MultipleOutputs类 有时可能需要对输出的把文件名进行控制,或让每个reducer输出多个文件。MapReduce为此提供了库:MultipleOutputs类 MultipleOutputs允许我们依据输出的key和value或者二进制string命名输出的文件名,如果为map输出的文件,则文件名的格式为"name-m-nnnnn", 如果reduce输出的文件,则文件名的格式为"name-r-nnnnn",其中"name"由MapReduce程序决定,”nnnnn“为part从0开始的整数编号,part编号确保从不同分区的输出(mapper或reducer)生成的文件名字不会冲突 下面的程序使用MultipleOutputs类将整个数据集切分为以气象站ID命名的文件
public class PartitionByStationUsingMultipleOutputs extends Configured implements Tool { static class StationMapper extends Mapper<LongWritable, Text, Text, Text> { private NcdcRecordParser parser = new NcdcRecordParser();
@Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
parser.parse(value);
context.write(new Text(parser.getStationId()), value);
}
} static class MultipleOutputsReducer extends Reducer<Text, Text, NullWritable, Text> { private MultipleOutputs<NullWritable, Text> multipleOutputs;
@Override protected void setup(Context context) throws IOException,
InterruptedException {
multipleOutputs = new MultipleOutputs<NullWritable, Text>(context);
}
@Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { for (Text value : values) {
multipleOutputs
.write(NullWritable.get(), value, key.toString());
}
}
@Override protected void cleanup(Context context) throws IOException,
InterruptedException {
multipleOutputs.close();
}
}
@Override public int run(String[] args) throws Exception {
Job job = JobBuilder.parseInputAndOutput(this, getConf(), args); if (job == null) { return -1;
}
job.setMapperClass(StationMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setReducerClass(MultipleOutputsReducer.class);
job.setOutputKeyClass(NullWritable.class); return job.waitForCompletion(true) ? 0 : 1;
} public static void main(String[] args) throws Exception { int exitCode = ToolRunner.run( new PartitionByStationUsingMultipleOutputs(), args);
System.exit(exitCode);
}
}
程序解释略,运行后有以下结果:
我们还可以适当 改变MultipleOutputs类中的write方法中的路径名参数,来得到我们想要输出文件名(例如:029070-99999/1901/part-r-00000),有下面程序:
@Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { for (Text value : values) {
parser.parse(value);
String basePath = String.format("%s/%s/part",
parser.getStationId(), parser.getYear());
multipleOutputs.write(NullWritable.get(), value, basePath);
}
}
4).延时输出
有些文件应用倾向于不创建空文件,此时就可以利用LazyOutputFormat,它是一个封装输出格式,可以保证指定分区第一条记录输出时才真正的创建文件,要使用它,用JobConf和相关输出格式作为参数来调用setOutputFormatClass()方法. |