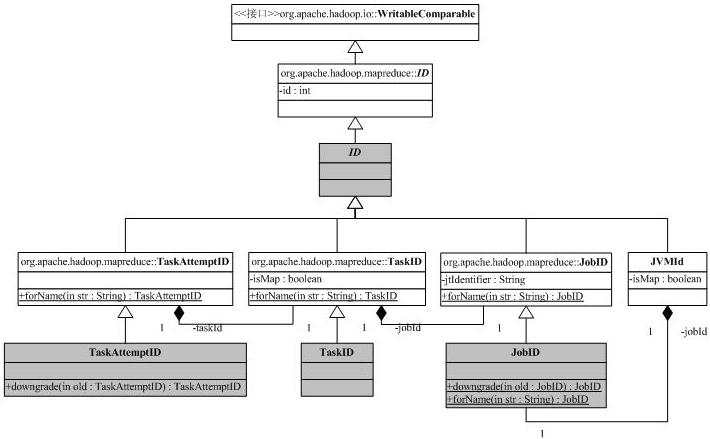
* Licensed to the Apache Software Foundation (ASF) under one
package org.apache.hadoop.mapreduce;
import java.io.DataInput;
/**
* JobID represents the immutable and unique identifier for
* the job. JobID consists of two parts. First part
* represents the jobtracker identifier, so that jobID to jobtracker map
* is defined. For cluster setup this string is the jobtracker
* start time, for local setting, it is "local".
* Second part of the JobID is the job number. <br>
* An example JobID is :
* <code>job_200707121733_0003</code> , which represents the third job
* running at the jobtracker started at <code>200707121733</code>.
* <p>
* Applications should never construct or parse JobID strings, but rather
* use appropriate constructors or {@link #forName(String)} method.
*
* @see TaskID
* @see TaskAttemptID
* @see org.apache.hadoop.mapred.JobTracker#getNewJobId()
* @see org.apache.hadoop.mapred.JobTracker#getStartTime()
*/
public class JobID extends org.apache.hadoop.mapred.ID
implements Comparable<ID> {
protected static final String JOB = "job";
private final Text jtIdentifier;
protected static final NumberFormat idFormat = NumberFormat.getInstance();
static {
idFormat.setGroupingUsed(false);
idFormat.setMinimumIntegerDigits(4);
}
/**
* Constructs a JobID object
* @param jtIdentifier jobTracker identifier
* @param id job number
*/
public JobID(String jtIdentifier, int id) {
super(id);
this.jtIdentifier = new Text(jtIdentifier);
}
public JobID() {
jtIdentifier = new Text();
}
public String getJtIdentifier() {
return jtIdentifier.toString();
}
@Override
public boolean equals(Object o) {
if (!super.equals(o))
return false;
JobID that = (JobID)o;
return this.jtIdentifier.equals(that.jtIdentifier);
}
/**Compare JobIds by first jtIdentifiers, then by job numbers*/
@Override
public int compareTo(ID o) {
JobID that = (JobID)o;
int jtComp = this.jtIdentifier.compareTo(that.jtIdentifier);
if(jtComp == 0) {
return this.id - that.id;
}
else return jtComp;
}
/**
* Add the stuff after the "job" prefix to the given builder. This is useful,
* because the sub-ids use this substring at the start of their string.
* @param builder the builder to append to
* @return the builder that was passed in
*/
public StringBuilder appendTo(StringBuilder builder) {
builder.append(SEPARATOR);
builder.append(jtIdentifier);
builder.append(SEPARATOR);
builder.append(idFormat.format(id));
return builder;
}
@Override
public int hashCode() {
return jtIdentifier.hashCode() + id;
}
@Override
public String toString() {
return appendTo(new StringBuilder(JOB)).toString();
}
@Override
public void readFields(DataInput in) throws IOException {
super.readFields(in);
this.jtIdentifier.readFields(in);
}
@Override
public void write(DataOutput out) throws IOException {
super.write(out);
jtIdentifier.write(out);
}
/** Construct a JobId object from given string
* @return constructed JobId object or null if the given String is null
* @throws IllegalArgumentException if the given string is malformed
*/
public static JobID forName(String str) throws IllegalArgumentException {
if(str == null)
return null;
try {
String[] parts = str.split("_");
if(parts.length == 3) {
if(parts[0].equals(JOB)) {
return new org.apache.hadoop.mapred.JobID(parts[1],
Integer.parseInt(parts[2]));
}
}
}catch (Exception ex) {//fall below
}
throw new IllegalArgumentException("JobId string : " + str
+ " is not properly formed");
}
}