|
一、引言 Hadoop是一种分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力高速运算和存储。Hadoop 1.2.1版本下载地址:http://apache.dataguru.cn/hadoop/common/hadoop-1.2.1/ 二、准备安装环境 我的本机是环境是windows8.1系统 +VMvare9虚拟机。VMvare中虚拟了3个ubuntu 12.10的系统,JDK版本为1.7.0_17.集群环境为一个master,两个slave,节点代号分别为node1,node2,node3.保证以下ip地址可以相互ping通,并且在/etc/hosts中进行配置
三、安装环境 1、首先修改机器名 使用root权限,使用命令:
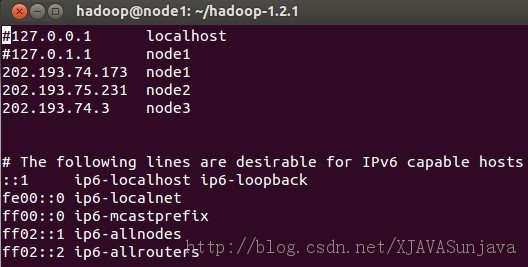
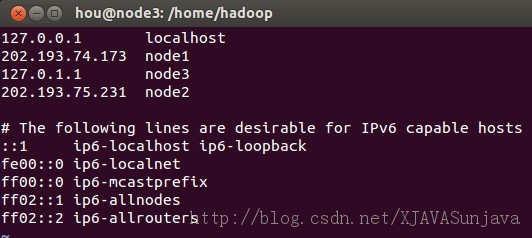
其中node1、node2、node3的/etc/hosts配置为:
/etc/hosts的配置很重要,如果配置的不合适会出各种问题,会影响到后面的SSH配置以及Hadoop的DataNode节点的启动。 2、安装JDK Ubuntu下的JDK配置请参考: http://developer.51cto.com/art/200907/135215.htm 3、添加用户 在root权限下使用以下命令添加hadoop用户,在三个虚拟机上都添加这个用户
将下载到的hadoop-1.2.1.tar文件放到/home/hadoop/目录下解压,然后修改解压后的文件夹的权限,命令如下:
4、安装和配置SSH 4.1)在三台实验机器上使用以下命令安装ssh:
安装以后执行测试:
输入当前用户名和密码按回车确认,说明安装成功,同时ssh登陆需要密码。 这种默认安装方式完后,默认配置文件是在/etc/ssh/目录下。sshd配置文件是:/etc/ssh/sshd_config 4.2)配置SSH无密码访问 在Hadoop启动以后,Namenode是通过SSH(Secure Shell)来启动和停止各个datanode上的各种守护进程的,这就须要在节点之间执行指令的时候是不须要输入密码的形式,故我们须要配置SSH运用无密码公钥认证的形式。 以本文中的三台机器为例,现在node1是主节点,他须要连接node2和node3。须要确定每台机器上都安装了ssh,并且datanode机器上sshd服务已经启动。 ( 说明:hadoop@hadoop~]$ssh-keygen -t rsa 这个命令将为hadoop上的用户hadoop生成其密钥对,询问其保存路径时直接回车采用默认路径,当提示要为生成的密钥输入passphrase的时候,直接回车,也就是将其设定为空密码。生成的密钥对id_rsa,id_rsa.pub,默认存储在/home/hadoop/.ssh目录下然后将id_rsa.pub的内容复制到每个机器(也包括本机)的/home/dbrg/.ssh/authorized_keys文件中,如果机器上已经有authorized_keys这个文件了,就在文件末尾加上id_rsa.pub中的内容,如果没有authorized_keys这个文件,直接复制过去就行.) 4.3)首先设置namenode的ssh为无需密码自动登陆, 切换到hadoop用户( 保证用户hadoop可以无需密码登录,因为我们后面安装的hadoop属主是hadoop用户。)
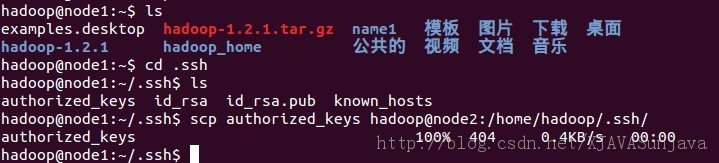
最后一个命令输入完成以后一直按回车, 完成后会在/home/hadoop/目录下产生完全隐藏的文件夹.ssh, 进入.ssh文件夹,然后将id_rsa.pub复制到authorized_keys文件,命令如下,
node1无密码登陆的效果:
4.4)配置node1无密码访问node2和node3 首先以node2为例,node3参照node2的方法 在node2中执行以下命令:
在node1中进入/home/hadoop/.ssh目录中,复制authorized_keys到node2的.ssh文件夹中 执行以下命令
修改已经传输到node2的authorized_keys的许可权限,需要root权限
node3同上面的执行步骤
5、安装hadoop 将当前用户切换到hadoop用户,如果集群内机器的环境完全一样,可以在一台机器上配置好,然后把配置好的软件即hadoop-0.20.203整个文件夹拷贝到其他机器的相同位置即可。 可以将Master上的Hadoop通过scp拷贝到每一个Slave相同的目录下,同时根据每一个Slave的Java_HOME 的不同修改其hadoop-env.sh 。 5.1)配置conf/hadoop-env.sh文件 切换到hadoop-1.2.1/conf目录下,添加JAVA_HOME路径
5.2)配置/conf/core-site.xml
fs.default.name是NameNode的URI。hdfs://主机名:端口/ hadoop.tmp.dir :Hadoop的默认临时路径,这个最好配置,如果在新增节点或者其他情况下莫名其妙的DataNode启动不了,就删除此文件中的tmp目录即可。不过如果删除了NameNode机器的此目录,那么就需要重新执行NameNode格式化的命令。 5.3)配置/conf/mapred-site.xml
mapred.job.tracker是JobTracker的主机(或者IP)和端口。主机:端口。其中/home/hadoop/hadoop_home/var目录需要提前创建,并且注意用chown -R 命令来修改目录权限 5.4)配置/conf/hdfs-site.xml
dfs.name.dir是NameNode持久存储名字空间及事务日志的本地文件系统路径。 当这个值是一个逗号分割的目录列表时,nametable数据将会被复制到所有目录中做冗余备份。 dfs.replication是数据需要备份的数量,默认是3,如果此数大于集群的机器数会出错。 此处的name1和data1等目录不能提前创建,如果提前创建会出问题。 5.5)配置master和slaves主从节点 配置conf/masters和conf/slaves来设置主从结点,注意最好使用主机名,并且保证机器之间通过主机名可以互相访问,每个主机名一行。 vi masters: 输入: node1 vi slaves: 输入: node2 node3 配置结束,把配置好的hadoop文件夹拷贝到其他集群的机器中,并且保证上面的配置对于其他机器而言正确,
安装结束
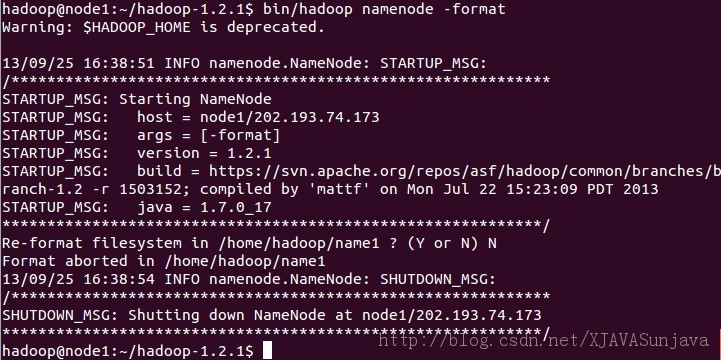
四、Hadoop启动与测试 1、格式化一个新的分布式文件系统
成功的情况下输入一下(我的hadoop已经使用,不想重新格式化选择了No)
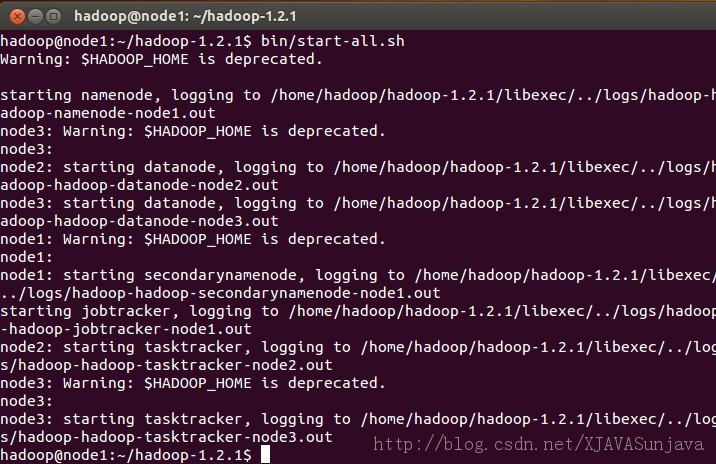
2、启动所有节点
3、查看集群的状态:
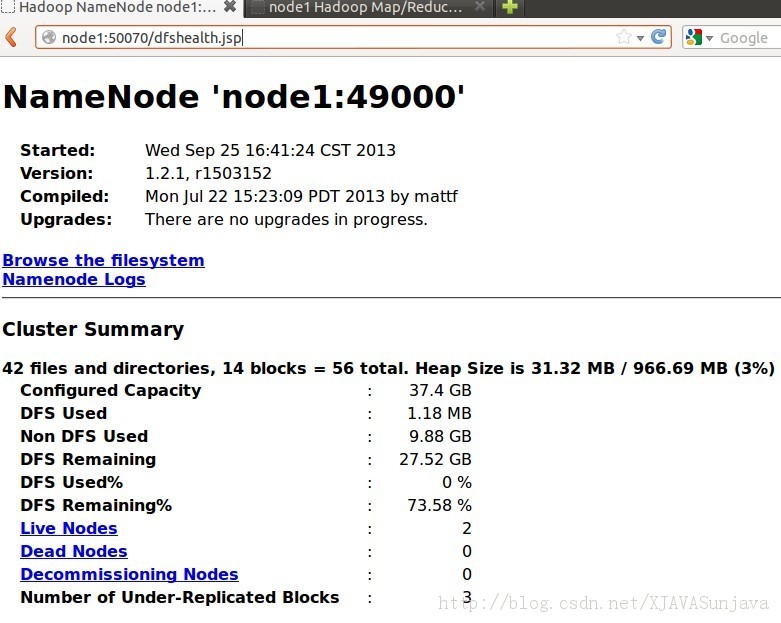
4、Hadoop测试 浏览NameNode和JobTracker的网络接口,它们的地址默认为: NameNode - http://node1:50070/ JobTracker - http://node1:50030/
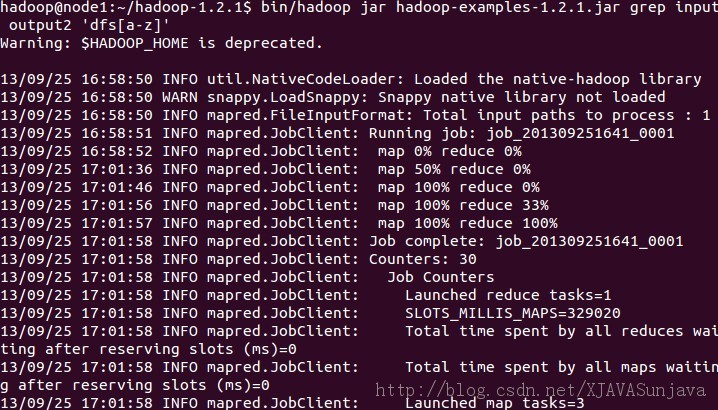
要想检查守护进程是否正在运行,可以使用 jps 命令(这是用于 JVM 进程的ps 实用程序)。这个命令列出 5 个守护进程及其进程标识符。 将输入文件拷贝到分布式文件系统:
到此为止,hadoop已经配置完成,当然在配置的过程中会遇到各种错误,主要都是权限问题和网络ip配置问题,请注意。 五、Hadoop一些常用的操作命令 1、hdfs常用操作: hadoopdfs -ls 列出HDFS下的文件 hadoop dfs -ls in 列出HDFS下某个文档中的文件 hadoop dfs -put test1.txt test 上传文件到指定目录并且重新命名,只有所有的DataNode都接收完数据才算成功 hadoop dfs -get in getin 从HDFS获取文件并且重新命名为getin,同put一样可操作文件也可操作目录 hadoop dfs -rmr out 删除指定文件从HDFS上 hadoop dfs -cat in/* 查看HDFS上in目录的内容 hadoop dfsadmin -report 查看HDFS的基本统计信息,结果如下 hadoop dfsadmin -safemode leave 退出安全模式 hadoop dfsadmin -safemode enter 进入安全模式 2、负载均衡 start-balancer.sh,可以使DataNode节点上选择策略重新平衡DataNode上的数据块的分布。 (责任编辑:IT) |