|
近年来,Internet的发展步入黄金时期,网上信息交换的数量正在呈指数形式的增长。特别是,由于电子商务的蓬勃发展,人们已经预计在下一世纪,网上消费将成为日常生活的重要形式。 随着网络硬件设备的飞速进步,网络带宽的瓶颈效应日趋减弱,WEB服务器的性能问题逐渐显现出来。单一的服务器系统处理客户请求的能力有限,如何处理快速增长的客户请求,是当前研究人员关注的重要问题。从目前的研究方向看,服务器方向的研究可以归结为两个方面:
就某一商业Web站点而言,人们通常会认为,日访问人数越多,说明销售的潜力越大,潜在的购买者越多。但统计结果向我们显示的却是另一种结果。随着日访问人数的增加,销售量上升到一定程度后,反而下降。图1给出的是某汽车销售网站网上销售的模拟计算结果。注意,当网站日查询业务量为正常的120%或更高时,访问的服务时间明显增长,使得日收益反而比正常情况下降很多。 图1:某汽车销售商网上销售模拟计算结果
究其原因,我们不难发现,服务器的性能是导致这种现象的最根本的原因。当服务器负载接近边界时,负载的一个小小的增长都有可能使服务器陷入象死锁那样的一种境地。由此可以得出,如何优化Web服务器性能将是今后一段时间研究的一个热点。许多服务器制造商都在努力推出性能更加优良的服务器,但是单一服务器结构有一个致命的缺陷,那就是由于服务器的处理能力有限,有可能会出现死锁的情况。死锁的产生是由于新请求的到达率大于系统服务率,系统没有能力在短期内处理所有的请求,导致等待队列溢出,系统 稳定状态转为不稳定状态,最后崩溃。集群服务器具有良好的可扩展性,可以随着负载的增大动态地向集群中增加服务器,从而就避免了由于处理能力不足而导致的系统崩溃。 粗粒度分发策略在集群系统中,粒度指的是负载调度和迁移的单位。集群系统中的粗粒度指的是调度和迁移的单位是服务,而细粒度指的是进程。目前,关于集群式服务器的研究主要集中在体系结构和负载平衡策略的研究上,其中负载平衡策略的研究又是体系结构研究的基础。早期的集群式服务器系统常采用Round-Robin DNS算法实现客户请求的分发。实际上是一种粗粒度的负载分配策略。 1.1 工作原理正常情况下,域名服务器将主机名映射为一个IP地址,为了改善负载平衡状况,早期的集群服务器系统采用RR-DNS(Round-Robin DNS)调度算法将一个域名映射为一组IP地址,允许客户端链接到服务器集群中的某一台服务器上,由此提供了服务器站点的伸缩性。一些可伸缩Web服务器(例如Eddie和NCSA的Scalable Web Server)采用RR-DNS实现负载平衡,一些高吞吐率的站点(Yahoo)也继续采用这种简单应用。图2为这类服务器结构的工作原理图。 图 2 基于DNS机制的集群服务器结构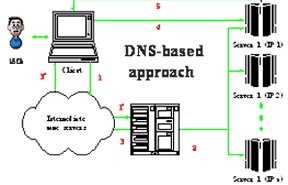
RR-DNS在解析域名时,附加一个生存期(TTL:Time-To-Live),这样一个请求生成后TTL时间内没有获得应答信息,可以向RR-DNS获取不同的IP地址。 1.2 工作流程
1.3 存在缺陷在一个TTL时期内,多个域名请求将被映射到相同的IP地址,这样大量的客户端请求可能出现在同一服务器上,导致明显的负载失衡。如果TTL很小,又会明显增加域名解析的网络负载。 另一个相关问题是由于客户端缓存域名-IP地址解析结果,客户端可以在未来的任意时刻发送请求,导致服务器的负载无法得到控制,出现服务器负载失衡。 1.4 相关算法研究为解决请求的负载分布均衡问题,研究者对RR-DNS算法进行了多种改进,这些改进依据TTL的设定形式可分为TTL恒定算法和自适应TTL算法。 TTL恒定算法 TTL恒定算法根据用户使用系统状态信息的情况又可分为系统无状态算法、基于服务器状态算法、基于客户状态算法和基于服务器/客户状态算法。
自适应TTL算法[20] 自适应TTL算法使用两步表决机制:首先DNS选择服务器的方法和基于客户状态算法相似;第二步,DNS根据负载分布情况、服务器处理能力和服务器的繁忙程度选择合适的TTL值,服务器越忙,设定的TTL值越小。 另外,自适应TTL算法的可扩展性很强,算法实现中的数据都可以动态获得。使用自适应TTL算法可以使服务器集群比较容易地从局域网拓展到广域网。 1.5 DNS算法比较由于客户端和中间域名服务器缓存URL-IP地址映射,使用服务器状态信息的DNS算法不能保证负载平衡[15],每个地址缓存都有可能引发大量的客户请求阻塞集群中的某个服务器节点。因此,合理地预测客户请求的到达率对于选择服务器更加有效。 使用客户到达率信息和服务器监听的调度算法可以获得更高可用性的服务器。但是这种算法明显不适于异构型集群服务器。 为平衡分布系统的请求负载,自适应TTL算法是最可靠、有效的。但是,这种算法忽略了客户-服务器距离的重要性。
回页首 细粒度分发策略为实现客户请求的集中调度和完全路由控制,采用细粒度负载分配策略的服务器结构中必须包含一个路由器节点──平衡器(可能是一个硬件路由器或集群服务器中配置专用软件的节点)接收发向Web站点的所有请求,根据某种负载平衡算法将请求转发到不同的服务器节点上。 与基于DNS的体系结构不同的是,平衡器采用单一的、虚拟IP地址IP-SVA(single virtual IP adress),这个IP地址是众所周知的一个IP地址,而节点服务器的实际地址对用户是透明的。由于此机制是在URL层进行请求的处理,Web页中包含的多个目标,可以由集群中的不同节点提供,这样提供了比RR-DNS更细粒度的控制策略。 根据路由机制的不同,细粒度负载分配策略又可分为报文重写(单向重写或双向重写)、报文转发和HTTP重定向。 2.1 PDR:报文双向重写策略PDR采用集中调度方式完成客户请求的路由控制,服务器系统的平衡器负责客户请求的接收、分发和结果的返回工作。与RR-DNS策略不同,平衡器在IP层进行地址重写,使用动态地址映射表,实现客户请求的重定向。采用单一的虚拟IP地址(IP-SVA),用户可见的只是平衡器,节点服务器是透明的。在选择节点服务器时采用的调度策略主要有:Round Robin(轮转)、Weighted Round Robin(加权轮转)、Least Connection(最少连接)和Weighted Least Connection(加权最少连接)。平衡器将客户和节点服务器的映射添加到映射表中,这样就保证了同一客户的所有请求都发送到同一台节点服务器上,从而保证了访问的持续性。采用PDR策略的典型代表是Cisco的Local Director,从路由机制上看,Local Director当前采用最少连接数策略。图1-3给出了Local Director处理客户请求的原理图。 图 3 LocalDirector原理图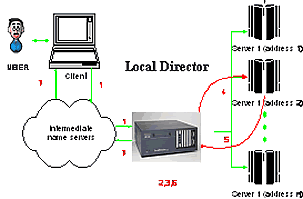
工作流程
性能分析
2.2 PSR:报文单向重写策略在某些体系结构中,平衡器对接收的客户请求进行二次路由,将客户报文的目的IP地址改写为实际处理节点的IP地址,例如基本的TCP路由机制[15]。 在TCP路由机制中,服务器集群由一组节点服务器和一个TCP路由器组成,TCP路由器充当IP地址平衡器。当客户请求到达TCP路由器时,由于IP-SVA是唯一公开的IP地址,平衡器将请求报文中的目标IP地址重写为节点服务器的私有IP地址。由于一个客户请求可能是由多个报文构成,TCP路由器在地址表中记录客户(具有相同的源IP地址)与执行服务器的地址映射,保证来自同一客户的所有报文都能到达同一台节点服务器。服务器在发送应答报文给客户时,将平衡器的IP-SVA写入源IP地址,这样客户并不知道请求是由隐藏的执行服务器完成。图4给出了服务器使用报文单向重写策略时,客户请求的执行过程。 工作流程:
图 4:报文单向重写示意图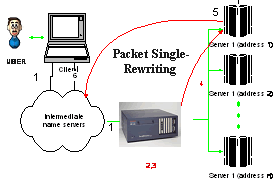
性能分析 2.3 PF:报文转发由于报文重写增加了平衡器处理请求的复杂度,导致平衡器负载加重,研究者提出了报文转发策略(PF)。采用PF策略,平衡器和执行服务器共用一个IP-SVA地址,客户请求报文到达平衡器后,平衡器根据调度选择执行服务器,利用执行服务器的物理地址(MAC)将报文转发给执行节点。转发过程中不需要进行地址解析,所以不必改动客户请求报文。采用PF策略的典型代表是IBM的Network Dispatcher。 局域网内部的Network Dispatcher集群处理客户请求的原理与图5相似,其工作流程如下:
为了将服务器集群从局域网拓展到广域网,Network Dispatcher采用两级平衡器机制,图5显示了广域网服务器集群的原理图。一级平衡器到二级服务器之间采用类似报文单向重写策略,平衡器将客户请求报文的目的地址(IP-SVA)改写为二级平衡器的IP地址,选择二级平衡器的原则是根据客户-服务器间的距离,将客户请求分发到最近的服务器子群上。二级平衡器将客户请求报文的目的地址改回IP-SVA,然后将报文转发到执行服务器上,服务器子群要求必须在同一局域网中。 图 5:广域网实现的报文转发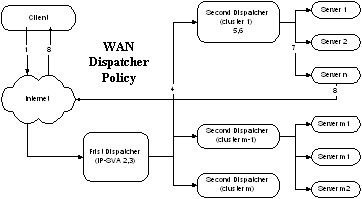
在广域网环境下,实现客户请求报文处理的流程是:
随着负载数量的增长,相应的处理变得越来越复杂(每个服务器节点每秒处理的请求数量有限),目前路由器只负责接收报文,但链接的复杂性、每个请求的返回数据量都限制了路由器的可伸缩性。 2.4 HTTP重定向策略集中式平衡器接收所有客户请求,使用HTTP重定向机制将客户请求分发到不同的执行服务器上。平衡器根据特殊的响应状态码,指明客户请求文件在服务器上的位置,因此重定向机制是高度透明的。与其他分发机制不同的是,HTTP重定向机制不需要对通讯报文的IP地址进行修改,HTTP重定向机制可以由以下两种技术实现。
2.4.1 基于服务器状态分发
2.4.2 基于位置的分发 回页首 细粒度分发策略的比较基于平衡器的报文双向重写机制的问题是,平衡器必须对应答报文进行重写,而应答报文的数量明显超过请求报文的数量。 使用TCP路由器结构的报文单向重写机制,由于执行服务器处理众多的应答报文,减轻了平衡器的负载。广域网环境下的Network Dispatcher仅对请求报文进行两次重写,因而执行效率更高。 报文转发机制可以有效避免报文重写带来的开销,然而共享单IP地址导致静态调度策略失效(服务器状态不决定路由)。基于路由的平衡器需要对每个报文进行二次路由,基于广播的平衡器需要把报文广播到每个执行服务器,这样明显加重了服务器负载。 局域网环境下的Network Dispatcher结构避免了共享IP地址、TCP路由和双向重写的开销等问题,但是它只能在同一网段内实现,可伸缩性很差。HTTP重定向可以很好地应用于局域网和广域网中,但必须复制一定数量的TCP连接。 回页首 各种负载平衡策略的比较基于DNS机构的实现机制可以明显减轻服务器的瓶颈效应,可伸缩能力得到加强,服务器环境从局域网拓展到广域网。但是,使用这种结构,服务器的数量不能超过32台(受UDP报文长度的限制)。基于DNS结构的服务器通过地址映射决定客户请求的目的地址,然而,这种粗粒度负载平衡机制要求TTL必须大于0,由于客户端对服务器地址进行缓存,导致服务器负载平衡不能保证,人们提出了基于状态信息算法和自适应TTL算法对DNS策略的性能进行改进。总的来说,单纯基于DNS策略的服务器适合于小规模的同构型服务器集群,但不适于异构性服务器结构。 基于平衡器结构的服务器由于受到单仲裁入口的限制,客户请求迅速增长可能导致平衡器成为系统瓶颈;由于平衡器对客户请求报文重写或转发,增加了客户等待延迟,降低了服务器性能;另外使用集中调度策略,若平衡器当机,则整个系统都会崩溃。从另一方面讲,平衡器实现的细粒度负载平衡策略,共享服务器IP地址又克服客户端网络层地址缓存问题。基于服务器拓扑结构实现的报文重写和转发策略是目前局域网或高速广域网中集群服务器实现的主要策略。 改进执行服务器处理过程将原有的请求集中控制改为部分分布控制,是服务器结构研究的一种进步,与平衡器结构服务器相同,这种技术也是一种细粒度负载平衡策略,但它带来的客户等待延迟要比其他策略增加很多。 从目前集群式服务器结构研究的现状分析可以看出,今后服务器集群的发展趋势将是面向广域网的分布控制的服务器集群研究。 参考资料
(责任编辑:IT) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
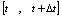 的客户接受服务器k1的服务,时刻
的客户接受服务器k1的服务,时刻 的客户接受服务器k2的服务,式中的 为TTL值。客户获取服务器地址后,将地址缓存在客户端,然后根据需要,向服务器发请求。
的客户接受服务器k2的服务,式中的 为TTL值。客户获取服务器地址后,将地址缓存在客户端,然后根据需要,向服务器发请求。