|
3. Codis实践
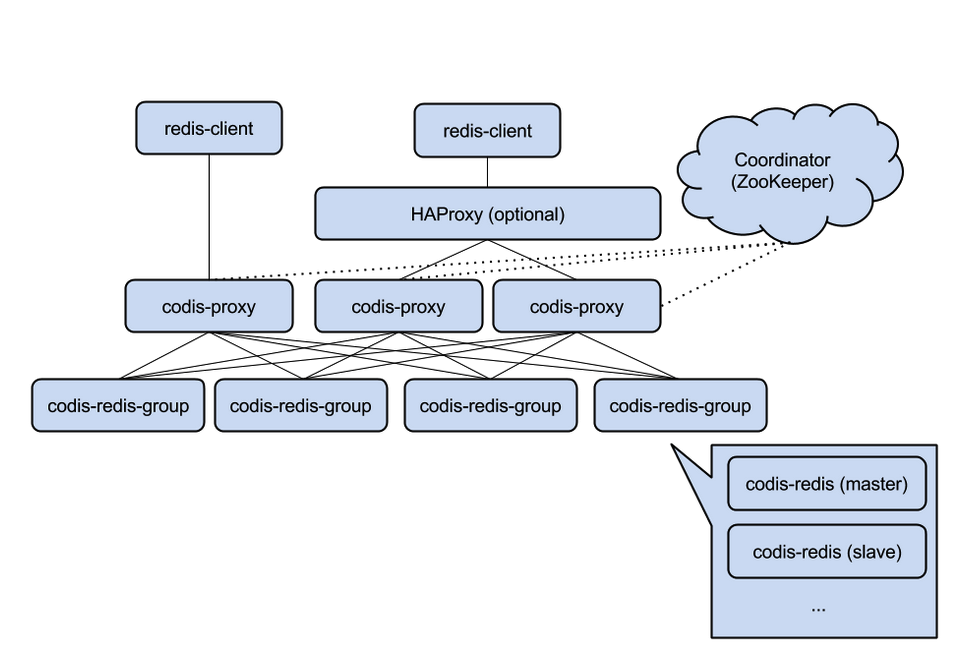
Codis由豌豆荚于2014年11月开源,基于Go和C开发,是近期涌现的、国人开发的优秀开源软件之一。现已广泛用于豌豆荚的各种Redis业务场景(已得到豌豆荚@刘奇同学的确认,呵呵)。 从3个月的各种压力测试来看,稳定性符合高效运维的要求。性能更是改善很多,最初比Twemproxy慢20%;现在比Twemproxy快近100%(条件:多实例,一般Value长度)。 3.1 体系架构Codis引入了Group的概念,每个Group包括1个Redis Master及至少1个Redis Slave,这是和Twemproxy的区别之一。这样做的好处是,如果当前Master有问题,则运维人员可通过Dashboard“自助式”切换到Slave,而不需要小心翼翼地修改程序配置文件。 为支持数据热迁移(Auto Rebalance),出品方修改了Redis Server源码,并称之为Codis Server。 Codis采用预先分片(Pre-Sharding)机制,事先规定好了,分成1024个slots(也就是说,最多能支持后端1024个Codis Server),这些路由信息保存在ZooKeeper中。
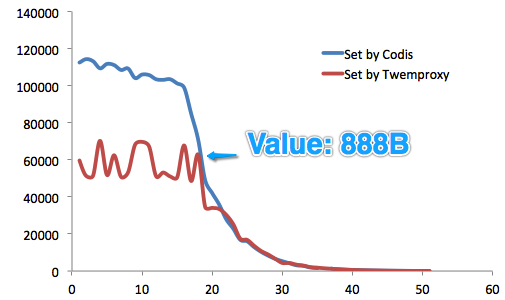
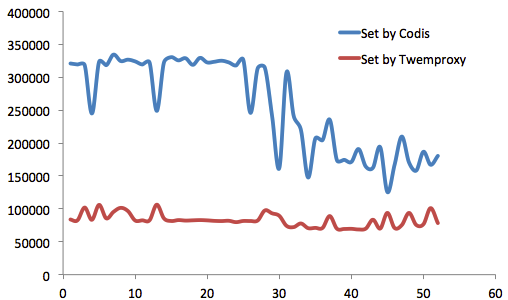
ZooKeeper还维护Codis Server Group信息,并提供分布式锁等服务。 3.2 性能对比测试Codis目前仍被精益求精地改进中。其性能,从最初的比Twemproxy慢20%(虽然这对于内存型应用而言,并不明显),到现在远远超过Twemproxy性能(一定条件下)。 我们进行了长达3个月的测试。测试基于redis-benchmark,分别针对Codis和Twemproxy,测试Value长度从16B~10MB时的性能和稳定性,并进行多轮测试。 一共有4台物理服务器参与测试,其中一台分别部署codis和twemproxy,另外三台分别部署codis server和redis server,以形成两个集群。 从测试结果来看,就Set操作而言,在Value长度<888B时,Codis性能优越优于Twemproxy(这在一般业务的Value长度范围之内)。
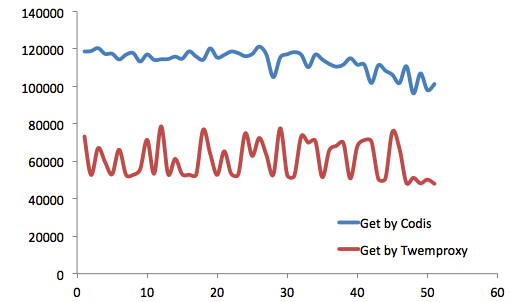
就Get操作而言,Codis性能一直优于Twemproxy。
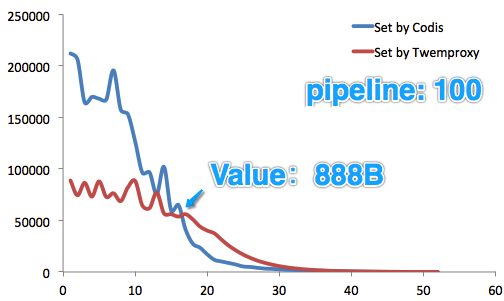
3.3 使用技巧、注意事项Codis还有很多好玩的东东,从实际使用来看,有些地方也值得注意。 1)无缝迁移Twemproxy出品方贴心地准备了Codis-port工具。通过它,可以实时地同步 Twemproxy 底下的 Redis 数据到你的 Codis 集群。同步完成后,只需修改一下程序配置文件,将 Twemproxy 的地址改成 Codis 的地址即可。是的,只需要做这么多。 2)支持Java程序的HACodis提供一个Java客户端,并称之为Jodis(名字很酷,是吧?)。这样,如果单个Codis Proxy宕掉,Jodis自动发现,并自动规避之,使得业务不受影响(真的很酷!)。 3)支持PipelinePipeline使得客户端可以发出一批请求,并一次性获得这批请求的返回结果。这提升了Codis的想象空间。 从实际测试来看,在Value长度小于888B字节时,Set性能迅猛提升;
Get性能亦复如是。
4)Codis不负责主从同步也就是说, Codis仅负责维护当前Redis Server列表,由运维人员自己去保证主从数据的一致性。 这是我最赞赏的地方之一。这样的好处是,没把Codis搞得那么重。也是我们敢于放手在线上环境中上线的原因之一。 5)对Codis的后续期待?好吧,粗浅地说两个。希望Codis不要变得太重。另外,加pipeline参数后,Value长度如果较大,性能反而比Twemproxy要低一些,希望能有改善(我们多轮压测结果都如此)。 因篇幅有限,源码分析不在此展开。另外Codis源码、体系结构及FAQ,参见如下链接: https://github.com/wandoulabs/codis PS:线上文档的可读性,也是相当值得称赞的地方。一句话:很走心,赞! 最后,Redis初学者请参考这个链接:http://www.gamecbg.com/bc/db/redis/13852.html,文字浅显易懂,而且比较全面。
本文得到Codis开发团队刘奇和黄东旭同学的大力协助,并得到Tim Yang老师等朋友们在内容把控方面的指导。本文共同作者为赵文华同学,他主要负责Codis及Twemproxy的对比测试。在此一并谢过。 |