|
Hive是facebook开源的一个非常伟大的工具,可以将hadoop中的数据用sql方式进行查询,比自己写map/reduce程序要方便很多。但是在实际使用中发现hive其实不够稳定,极少数情况会出现端口不响应或者进程丢失的问题,所以考虑将hive做成负载均衡的方式。或者更严格的说,叫做失效备份,避免出现某台个别的服务器连接数过大造成的端口不响应或者服务器故障造成无法查询。
前提是有2-3台服务器作为hive server,一台放置HAProxy。
一、安装配置HAProxy
#wget http://haproxy.1wt.eu/download/1.4/src/haproxy-1.4.20.tar.gz
#tar zxf haproxy-1.4.20.tar.gz #mv haproxy-1.4.20 /opt/modules/haproxy #cd /opt/modules/haproxy #make TARGET=linux26
这样就编译完成了。
然后来配置HAProxy为四层代理,仅作为端口转发器使用。
global
daemon nbproc 1 pidfile /var/run/haproxy.pid ulimit-n 65535 #################### defaults mode tcp #mode { tcp|http|health },tcp 表示4层,http表示7层(对我们没用),health仅作为健康检查使用 retries 2 #尝试2次失败则从集群摘除 option redispatch #如果失效则强制转换其他服务器 option abortonclose #连接数过大自动关闭 maxconn 1024 #最大连接数 timeout connect 1d #连接超时时间,重要,hive查询数据能返回结果的保证 timeout client 1d #同上 timeout server 1d #同上 timeout check 2000 #健康检查时间 log 127.0.0.1 local0 err #[err warning info debug] ################ listen admin_stats #定义管理界面 bind 0.0.0.0:1090 #管理界面访问IP和端口 mode http #管理界面所使用的协议 maxconn 10 #最大连接数 stats refresh 30s #30秒自动刷新 stats uri / #访问url stats realm Hive\ Haproxy #验证窗口提示 stats auth admin:123456 #401验证用户名密码 ########hive1################# listen hive #hive后端定义 bind 0.0.0.0:10000 #ha作为proxy所绑定的IP和端口 mode tcp #以4层方式代理,重要 balance leastconn #调度算法 'leastconn' 最少连接数分配,或者 'roundrobin',轮询分配 maxconn 1024 #最大连接数 server hive_215 192.168.1.49:10000 check inter 180000 rise 1 fall 2 #释义:server 主机代名(你自己能看懂就行),IP:端口 每180000毫秒检查一次。也就是三分钟。 #hive每有10000端口的请求就会创建一个log,设置短了,/tmp下面会有无数个log文件,删不完。 server hive_216 192.168.1.50:10000 check inter 180000 rise 1 fall 2 #同上,另外一台服务器。
用haproxy -f haproxy.conf启动。
比较重要的其实是timeout的前三个选项的时间定义,因为hive运算请求时间会比较长,通常都会超过一个tcp包正常的session响应时间。所以,hive需要一个长连接来等待数据返回,在TCP里面应该是TIME_WAIT我记得。如果设置太短了,SQL可以提交成功,但是你将不会获得任何返回值。因为被提交的session已经关闭了。所以普通的tcp代理转发并不适合hive的应用。这点在做定时任务的时候尤其重要,你可能会提交一个任务,但是不会获得任何返回,又查不出任何结果,就很头疼。作为hive的任务开发者,不了解tcp协议的工作情况,作为运维又不了解hive,所以如果这里出了错误,会很难发现。我写的1d是1天的意思,正常的话,当hive执行完毕,会自己发送关闭TCP的指令。这点倒是不用太担心累计连接数超过限定。
1d标志1天,类似的还有1h表示1小时,1s表示1秒,1ms表示1ms。
另外配合我之前写过的python daemon程序,稍加修改,用来监控hive的server进程,就基本可保证hive server集群的高可用了。
目前这个高可用方案在公司内部的phpHiveAdmin中已经可以使用了,查询和结果获取正常无误,thrift连接IP和端口只要指向到Haproxy的IP和端口就可以了。
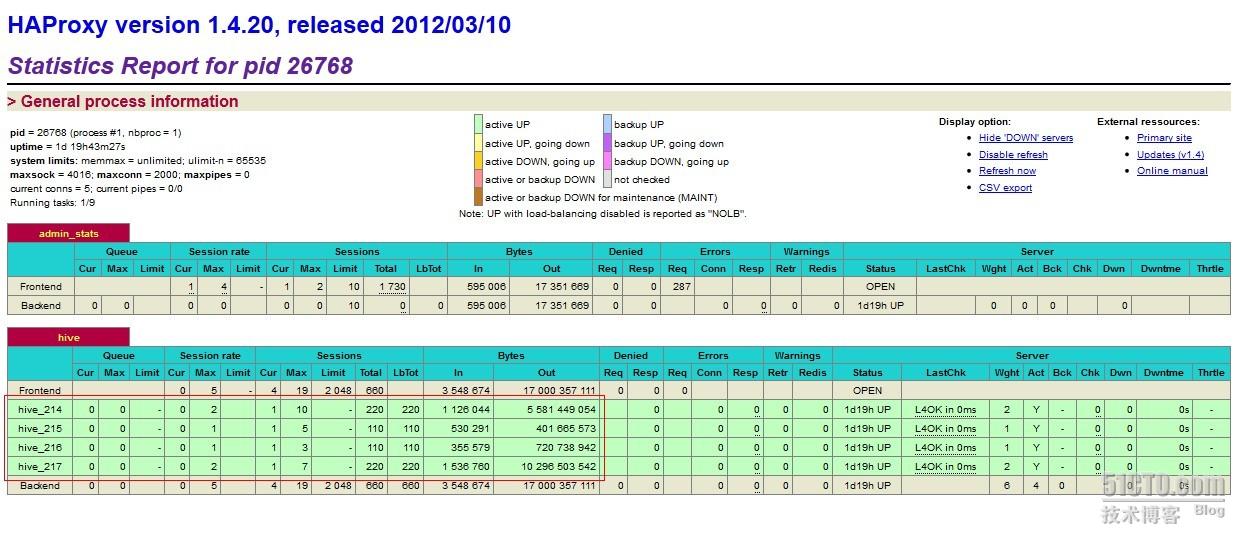
二、hive服务器端监控程序python
只要检测到hive进程没有或者端口消失,均重新启动hive
#!/usr/bin/env python
import sys, os, time, atexit, string from signal import SIGTERM class Daemon: def __init__(self, pidfile, stdin='/dev/null', stdout='/dev/null', stderr='/dev/null'): self.stdin = stdin self.stdout = stdout self.stderr = stderr self.pidfile = pidfile def _daemonize(self): try: pid = os.fork() if pid > 0: sys.exit(0) except OSError, e: sys.stderr.write('fork #1 failed: %d (%s)\n' % (e.errno, e.strerror)) sys.exit(1) os.chdir("/") os.setsid() os.umask(0) try: pid = os.fork() if pid > 0: sys.exit(0) except OSError, e: sys.stderr.write('fork #2 failed: %d (%s)\n' % (e.errno, e.strerror)) sys.exit(1) sys.stdout.flush() sys.stderr.flush() si = file(self.stdin, 'r') so = file(self.stdout, 'a+') se = file(self.stderr, 'a+', 0) os.dup2(si.fileno(), sys.stdin.fileno()) os.dup2(so.fileno(), sys.stdout.fileno()) os.dup2(se.fileno(), sys.stderr.fileno()) atexit.register(self.delpid) pid = str(os.getpid()) file(self.pidfile,'w+').write('%s\n' % pid) def delpid(self): os.remove(self.pidfile) def start(self): try: pf = file(self.pidfile,'r') pid = int(pf.read().strip()) pf.close() except IOError: pid = None if pid: message = 'pidfile %s already exist. Daemon already running?\n' sys.stderr.write(message % self.pidfile) sys.exit(1) self._daemonize() self._run() def stop(self): try: pf = file(self.pidfile,'r') pid = int(pf.read().strip()) pf.close() except IOError: pid = None if not pid: message = 'pidfile %s does not exist. Daemon not running?\n' sys.stderr.write(message % self.pidfile) return try: while 1: os.kill(pid, SIGTERM) time.sleep(0.1) os.system("kill -9 `ps -ef | grep java | grep hive | grep -v 'grep' | awk '{print $2}'`") except OSError, err: err = str(err) if err.find('No such process') > 0: if os.path.exists(self.pidfile): os.remove(self.pidfile) else: print str(err) sys.exit(1) def restart(self): self.stop() self.start() def _run(self): while True: datanode = os.popen('ps -fe | grep "java" | grep "hive" | grep -v "grep" | wc -l').read().strip() if datanode == '0': os.system('export HADOOP_HOME=/opt/modules/hadoop/hadoop-0.20.203.0; export JAVA_HOME=/usr/java/jdk1.6.0_21; /opt/modules/hive/hive-0.7.1/bin/hive --service hiveserver 10001 &') time.sleep(2) if __name__ == '__main__': daemon = Daemon('/tmp/watch_process.pid') if len(sys.argv) == 2: if 'start' == sys.argv[1]: daemon.start() elif 'stop' == sys.argv[1]: daemon.stop() elif 'restart' == sys.argv[1]: daemon.restart() else: print 'Unknown command' sys.exit(2) sys.exit(0) else: print 'usage: %s start|stop|restart' % sys.argv[0] sys.exit(2)
给可执行权限,然后用./daemon.py start启动,每两秒检测一次进程和端口。
2012-06-01
修改监控代码
(责任编辑:IT) |