|
Yelp 础设施团队的主要目标之一就是为了尽可能接近零停机时间。那也就是说当用户访问www.yelp.com 作出动作的时候,网站的响应速度必须尽可能的快。一种方法是使用 HAProxy 负载均衡能够保持 www.yelp.com 网站的响应速度。通常我们在任何地方都使用 HAProxy 来保持网站的外部负载均衡、内部负载均衡,甚至运用到构建面向服务的架构中。我们发现在 Yelp 的每台机器上运行 HAProxy,均可作为 SmartStack 的一部分。 我们喜欢在发展 SOA 的时候使用 SmartStack 给我们带来的灵活性,但这种灵活性是有代价的。通常当服务或在服务后端执行增加或永久删除命令的的时候,整个基础设施不得不重新加载 HAProxy 。这种重载方式会导致可靠性问题,因为 HAProxy 一旦运转起来就一直保持在工作状态且不会中断流量,但在重载的时候它会中断流量。 HAProxy 重载丢流量 HAProxy 的 1.5.11 版本不支持重启或重新加载配置时的零停机时间。相反,它支持快速重载——当一个新的 HAProxy 实例启动时,它尝试使用 SO_REUSEPORT 去绑定老 HAProxy 监听的相同端口并给老 HAProxy 实例发送信号去关闭。这种技术非常接近现代 Linux 内核的零停机时间,但这仍旧会经历一个短暂的时隙——当两个进程都绑定到端口时。在这个关键的时隙中,由于Linux内核自身(丢弃)处理多个接受进程的方式可能有流量会被丢掉。特别要提出来的,这个问题会潜在导致从 HAProxy 过来的新连接有一个 RST。这个问题是 SYN 包在老 HAProxy 被调用关闭前会被先放进其套接字队列中,这导致了这些连接的 RST。 这个问题有许多解决办法。例如,Willy Tarreau,HAProxy 的主要维护者,建议用户在重启 HAProxy 时丢掉 SYN 包,利用 TCP 的自动修复。不幸的是,RFC 6298 规定的初始 SYN 的超时时间是1s,Linux 内核坚守此规定。因此,丢弃 SYN 意味着任何试图在 HAProxy 加载的 20-50ms 之间重建的连接将会遭受一个额外的秒级或更长的延迟。确切的时间依赖于客户端的 TCP 实现,而一些移动设备重试时间为 200ms,很多设备只在 3S 后重试。鉴于 HAProxy 重载的次数和和 Yelp 的流量,这成为了我们服务可靠性的一个障碍。 让HAProxy重载不丢包为了避免延迟,我们采用了Willy提议的方案。他的方案实际上在不丢弃数据包上表现很好,但是额外的一秒延时是个问题。我们更好的解决方案是延迟SYN包直到重载已经完成,因为这样做只会对新的连接产生HAProxy重载所需要的延迟。 为了实现这种方案,我们求助于Linux队列原则 (qdiscs)。Linux队列原则是用来管理Linux内核处理网络数据包的方式。具体地说就是你可以控制数据包是如何入队和出队,这提供了速率限制,优先或指定输出数据包的能力。有关更多qdiscs的详情, 我极力推荐lartc howto以及相关的man页面。 我们的一个SRE(网站可靠性工程师),Josh Snyder花了一些晚上的时间阅读了Linux内核源代码,发现了一个文档记录很少的工具:plug排队原则(qdisc),qdisc是从Linux 3.4以来就存在了。使用plug qdisc和以下标准Linux技术, 我们可以实现HAProxy重载零宕机:
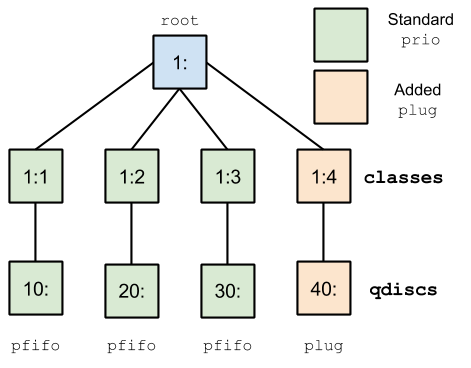
SmartStack客户端连接到loopback接口向HAProxy请求,HAProxy幸好将进入的包变成为输出包。这意味着我们可以在loopback接口上建立如图1的队列原则。
Figure 1: Queueing Discipline 该设置的一个分类实现了使用 prio qdisc 队列规定的标准 pfifo_fast,但只是使用了第四个“plug“通道。plug qdisc 并没有使他们退出队列,而是拥有队列数据包的性能。与一个 iptables 命令相结合的性能来允许我们在整个 HAProxy 重载期间重新定向,然后拔掉后重载的 SYN 插头的数据包。该控键(‘1:1’, ‘30:’等等)是允许我们一起连接 qdiscs,并且使用过滤器发送特定 qdiscs 的数据包。有关更多的信息,请查阅 lartc howto上面所引用的。 然后,我们把我们调用 qdisc_tool 的这个功能编进脚本。该工具允许我们的基础设施“保护”HAProxy 重载我们 plug 流量,重启haproxy,然后松开这个插头,交付延迟所有的 SYN 数据包。这个调用看起来像: qdisc_tool protect <normal HAProxy reload command>
我们可以轻易地在诸如 Ubuntu Trusty 的 linux 发行版本上使用标准的用户空间实用工具来复制该技术。如果你的设置并没有 nl-qdisc-add,但有3.4+ Linux 内核,那么你可以通过 netlink 来手动地操纵该插头。 设置队列规则在我们优雅重载HAProxy之前,我们必须先使用tc和nl-qdisc-add设置上面提到的队列规则。注意下面的每个命令必须以root运行。
setup_qdisc.sh 在 GitHub 上 生成 SYN 包我们希望所有的 SYN 包被路由到塞入通道,这我们可以通过 iptables 实现。我们使用一个本地链路地址,以便我们在重载时重定向我们想要的流量,客户如果希望避免塞入可以生成一个请求到127.0.0.1,这是一直可用的一个选项。请注意,这是假设你已经建立了一个连接到 169.254.255.254的本地链路。
重载时触发塞入一旦一切都成立,我们优雅重载 HAProxy 所需要做的是:在重载前缓存 SYN,重载,然后在重载后释放所有 SYN。这将导致任何尝试在重启过程中尝试建立的连接经历一个延迟,这个延迟等于 HAProxy 重启时间。
plug_manipulation.sh 在 GitHub 上 在生产中我们观察到这项技术对重启过程中的新进连接增加了约 20ms 的延迟,但没有请求被丢弃。
设计的权衡这个设计具有一定的优点和缺点。最大的缺点是其只针对传出连接而不针对传入的流量。其原因是队列规则在 Linux 上的工作方式,既你只能对传出的流量整形。而对于传入的流量,首先必须重定向到一个中介接口,然后再对中介接口的传出流量进行整形。我们正在研究类似的集成解决方案以应用在我们外部的负载均衡器中,但尚未投入生产环境。 此外,qdiscs 也应该调整地更有效。例如,我们以第一优先级将 qdisc 塞入,并调整 priomap 从而确保 SYN 包总是先于其他包被处理,或者调整 pfifo/qdiscs 的缓冲器大小。我认为这些可以在非环回口的接口上应用,塞入插件必须在第一优先级以确保 SYN 的输送能力。
我们决定采用这种解决方案而不是 huptime,修改传递到 HAProxy 的文件描述符,或在多个本地HAProxy 实例之间跳转的原因是因为我们认为采用 qdisc 方案的风险是最低的。huptime 被很快地排除,因为由于一个老的 libc 版本,我们无法让它在我们的机器上运行正常,并且我们也不确定LD_PRELOAD 机制是否会在一些复杂如 HAProxy 上工作。一个工程师在一个黑客马拉松上概念验证式地实施了文件描述符补丁,但是补丁的复杂性以及有可能引入大量分叉促使我们放弃了这个想法。它表明合理地文件描述符传递真的是困难的。 在这三种方案里面,我们最严肃地考虑过在同一台机器上运行多个 HAProxy 实例,使用 NAT,nginx 或另一个 HAProxy 实例来做切换。最终我们否决了这种方案因为有许多的实施不确定因素,以及基础架构的维护等级。 使用我们的解决方案,我们基本保持零基础设施,相信 Linux 内核和 HAProxy 可以处理。这几个月里, 这个方案一直在生产环境运行,我们没有发现任何问题,这种方案没有辜负我们的信任。
实验性安装为了证明这个解决方案确实有效,我们可以启动一个nginx HTTP后端,与此同时HAProxy作为前端,Apache Benchmark产生很多流量,当我们重启HAProxy的时候,我们来看看发生了什么。我们可以用这种方式评估不同的解决方案。 所有的测试都是在一个新的c3.large AWS机器上用Ubuntu Trusty和3.13 Linux内核进行的。HAProxy 1.5.11被编译在本地,用TARGET=linux2628(编译命令)。Nginx使用默认配置方式启动,并在8001端口进行监听,服务器发送一个简单的“pong”回答用来代替默认的html。我们编译HAProxy的基本配置,它有一个单独的后端,端口是8001,与之对应的前端端口是16000。
仅重新加载HAProxy在这个实验里,我们仅仅重启HAProxy,使用‘-sf’选项,它会以最快速度进行重启处理。这是一个不那么真实的测试,因为我们每100ms重启一次HAProxy,但是这个实验可以说明这一点(解决方案是否有效)。
实验
reload_experiment.sh 在 GitHub 上 结果
socket 重置了!重启HAProxy已经导致了失败请求,即便我们的后端是正常的。下面让我们告诉Apache基准测试器来继续接受错误并生成更多的请求:
reload_longer_result 托管在 GitHub 上 只有 0.25% 的请求失败。这也不是太坏,但仍高于我们 0 的目标。
丢掉 SYN 包,让 TCP 做余下的工作现在让我们尝试下丢掉 SYN 包的方法。这个方法可以以高的重启速率以达到重试连接的效果,为得到可靠的结果我每秒重启一次 HAProxy。 实验
iptables_experiment.sh 托管在 GitHub 结果
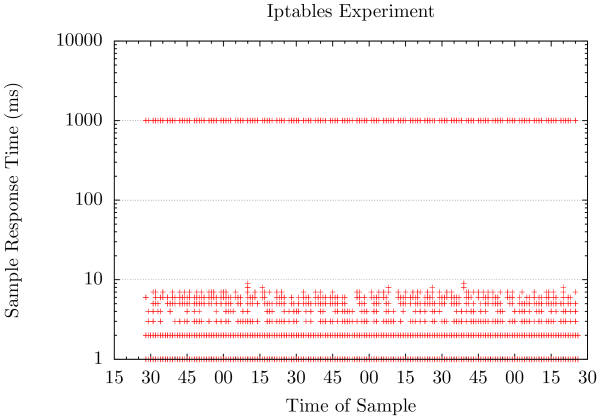
图2: Iptables实验结果 正如预期的那样,我们没有丢弃请求但收到了一个额外的一秒钟的延迟。在请求绘制图图2中我们可以看到明显地看到命中重启时的两个峰值,其需要满满的一秒来完成请求。小于百分之一的测试请求观察到了高延迟,但这仍足以成为一个问题。
使用我们的平和重启方法在这个实验中,我们将使用 ‘-sf’ 选项重启HAProxy以使用我们的队列策略来延时传入的SYN包。为确保我们不是因为运气,我们做了一百万的请求。在本试验中我们对HAProxy重启了1500次以上。 实验
结果
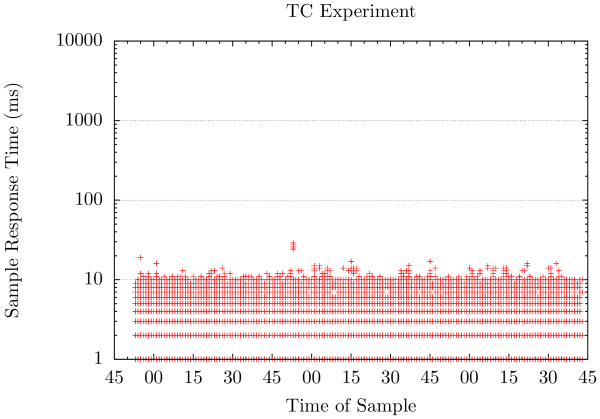
图3: TC实验结果 成功啦!重启HAProxy已基本对我们的流量没有影响,在图3中可以看仅造成了轻微的延迟。请注意,该方法主要依赖HAProxy重载配置所花费的时间,由于我们使用了一个精简的配置,结果好的有点离谱。在我们的生产环境中,HAProxy重启时我们能观察到一个20ms的延迟影响。 结论这项技术似乎在我们实现目标——为开发构建提供坚实的基础服务设施上运行地很好。通过延迟SYN包进入每台机器上运行的HAProxy负载均衡器,我们能够最小化HAProxy重载所影响到的流量,这允许在达成我们SOA的情况下添加,删除和更改服务后端,而不必恐惧该过程显著影响用户的流量。
英文原文:True Zero Downtime HAProxy Reloads
(责任编辑:IT) |