|
分片是MongoDB的扩展方式,通过分片能够增加更多的机器来用对不断增加的负载和数据,还不影响应用. 1.分片简介 分片是指将数据拆分,将其分散存在不同机器上的过程.有时也叫分区.将数据分散在不同的机器上,不需要功能 强大的大型计算机就可以存储更多的数据,处理更大的负载. 使用几乎所有数据库软件都能进行手动分片,应用需要维护与若干不同数据库服务器的连接,每个连接还是完全 独立的.应用程序管理不同服务器上的不同数据,存储查村都需要在正确的服务器上进行.这种方法可以很好的工作,但是也 难以维护,比如向集群添加节点或从集群删除节点都很困难,调整数据分布和负载模式也不轻松. MongoDB支持自动分片,可以摆脱手动分片的管理.集群自动切分数据,做负载均衡.
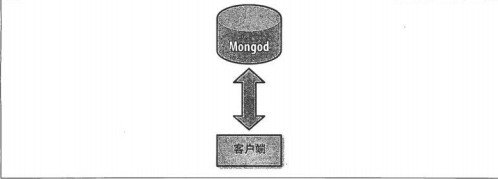
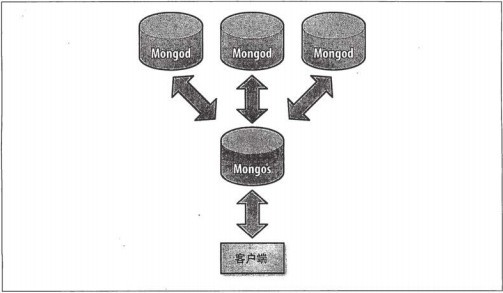
2.MongoDB的自动分片 MongoDB分片的基本思想就是将集合切分成小块.这些块分散到若干片里面,每个片只负责总数据的一部分.应用程序不必知道 哪片对应哪些数据,甚至不需要知道数据已经被拆分了,所以在分片之前要运行一个路由进程,进程名mongos,这个路由器知道 所有数据的存放位置,所以应用可以连接它来正常发送请求.对应用来说,它仅知道连接了一个普通的mongod.路由器知道和片的 对应关系,能够转发请求到正确的片上.如果请求有了回应,路由器将其收集起来回送给应用. 在没有分片的时候,客户端连接mongod进程,分片时客户端会连接mongos进程.mongos对应用隐藏了分片的细节. 从应用的角度看,分片和不分片没有区别.所以需要扩展的时候,不必修改应用程序的代码. 不分片的客户端连接:
分片的客户端连接:
什么时候需要分片: a.机器的磁盘不够用了 b.单个mongod已经不能满足些数据的性能需要了 c.想将大量数据放在内存中提高性能 一般来说,先要从不分片开始,然后在需要的时候将其转换成分片.
3.片键 设置分片时,需要从集合里面选一个键,用该键的值作为数据拆分的依据.这个键成为片键. 假设有个文档集合表示的是人员,如果选择名字"name"做为片键,第一篇可能会存放名字以A-F开头的文档. 第二片存G-P开头的文档,第三篇存Q-Z的文档.随着增加或删除片,MongoDB会重新平衡数据,是每片的流量比较 均衡,数据量也在合理范围内(如流量较大的片存放的数据或许会比流量下的片数据要少些)
4.将已有的集合分片 假设有个存储日志的集合,现在要分片.我们开启分片功能,然后告诉MongoDB用"timestamp"作为片键,就要所有数据放到 了一个片上.可以随意插入数据,但总会是在一个片上. 然后,新增一个片.这个片建好并运行了以后,MongoDB就会把集合拆分成两半,成为块.每个块中包含片键值在一定 范围内的所有文档,假设其中一块包含时间戳在2011.11.11前的文档,则另一块含有2011.11.11以后的文档.其中 一块会被移动到新片上.如果新文档的时间戳在2011.11.11之前,则添加到第一块,否则添加到第二块.
5.递增片键还是随机片键 片键的选择决定了插入操作在片之间的分布. 如果选择了像"timestamp"这样的键,这个值可能不断增长,而且没有太大的间断,就会将所有数据发送到一个片上 (含有2011.11.11以后日期的那片).如果有添加了新片,再拆分数据,还是会都导入到一台服务器上.添加了新片, MongoDB肯能会将2011.11.11以后的拆分成2011.11.11-2021.11.11.如果文档的时间大于2021.11.11以后, 所有的文档还会以最后一片插入.这就不适合写入负载很高情况,但按照片键查询会非常高效. 如果写入负载比较高,想均匀分散负载到各个片,就得选择分布均匀的片键.日志例子中时间戳的散列值,没有模式的"logMessage" 都是复合这个条件的. 不论片键随机跳跃还是稳定增加,片键的变化很重要.如,如果有个"logLevel"键的值只有3种值"DEBUG","WARN","ERROR", MongoDB无论如何也不能把它作为片键将数据分成多于3片(因为只有3个值).如果键的变化太少,但又想让其作为片键, 可以把这个键与一个变化较大的键组合起来,创建一个复合片键,如"logLevel"和"timestamp"组合. 选择片键并创建片键很像索引,以为二者原理相似.事实上,片键也是最常用的索引.
6.片键对操作的影响 最终用户应该无法区分是否分片,但是要了解选择不同片键情况下的查询有何不同. 假设还是那个表示人员的集合,按照"name"分片,有3个片,其名字首字母的范围是A-Z.下面以不同的方式查询: db.people.find({"name":"Refactor"}) mongos会将这个查询直接发送给Q-Z片,获得响应后,直接转发给客户端 db.people.find({"name":{"$lt":"L"}}) mongos会将其先发送给A-F和G-P片,然后将结果转发给客户端. db.people.find().sort({"email":1}) mongos会在所有片上查询,返回结果时还会做归并排序,确保结果顺序正确. mongos用游标从各个服务器上获取数据,所以不必等到全部数据都拿到才向客户端发送批量结果. db.people.find({"email":"refactor@msn.cn"}) mongos并不追踪"email"键,所以也不知道应该将查询发给那个片.所以他就向所有片顺序发送查询. 如果是插入文档,mongos会依据"name"键的值,将其发送到相应的片上.
7.建立分片 建立分片有两步:启动实际的服务器,然后决定怎么切分数据. 分片一般会有3个组成部分: a.片 片就是保存子集合数据的容器,片可是单个的mongod服务器(开发和测试用),也可以是副本集(生产用).所以一片 有多台服务器,也只能有一个主服务器,其他的服务器保存相同的数据. b.mongos mongos就是MongoDB配的路由器进程.它路由所有的请求,然后将结果聚合.它本身并不存储数据或者配置信息 但会缓存配置服务器的信息. c.配置服务器 配置服务器存储了集群的配置信息:数据和片的对应关系.mongos不永久存房数据,所以需要个地方存放分片的配置. 它会从配置服务器获取同步数据.
8.启动服务器 首先要启动配置服务器和mongos.配置服务器需要先启动.因为mongos会用到其上的配置信息. 配置服务器的启动就像普通的mongod一样 mongod --dbpath "F:\mongo\dbs\config" --port 20000 --logpath "F:\mongo\logs\config\MongoDB.txt" --rest 配置服务器不需要很多的空间和资源(200M实际数据大约占用1kB的配置空间)
建立mongos进程,一共应用程序连接.这种路由服务器连接数据目录都不需要,但一定要指明配置服务器的位置: mongos --port 30000 --configdb 127.0.0.1:20000 --logpath "F:\mongo\logs\mongos\MongoDB.txt" 分片管理通常是通过mongos完成的.
添加片 片就是普通的mongod实例(或副本集) mongod --dbpath "F:\mongo\dbs\shard" --port 10000 --logpath "F:\mongo\logs\shard\MongoDB.txt" --rest mongod --dbpath "F:\mongo\dbs\shard1" --port 10001 --logpath "F:\mongo\logs\shard1\MongoDB.txt" --rest 连接刚才启动的mongos,为集群添加一个片.启动shell,连接mongos: 确定连接的是mongos而不是mongod,通过addshard命令添加片: >mongo 127.0.0.1:30000
mongos> db.runCommand(
mongos> db.runCommand( 当在本机运行片的时候,得设定allowLocal键为1.MongoDB尽量避免由于错误的配置,将集群配置到本地, 所以得让它知道这仅仅是开发,而且我们很清楚自己在做什么.如果是生产环境中,则要将其部署在不同的机器上. 想添加片的时候,就运行addshard.MongoDB会负责将片集成到集群.
切分数据 MongoDB不会将存储的每一条数据都直接发布,得先在数据库和集合的级别将分片功能打开. 如果是连接配置服务器,
E:\mongo\bin>mongo 127.0.0.1:20000 应该是连接 路由服务器: db.runCommand({"enablesharding":"test"})//将test数据库启用分片功能. 对数据库分片后,其内部的集合便会存储到不同的片上,同时也是对这些集合分片的前置条件. 在数据库级别启用了分片以后,就可以使用shardcollection命令堆积和进行分片: db.runCommand({"shardcollection":"test.refactor","key":{"name":1}})//对test数据库的refactor集合进行分片,片键是name 如果现在对refactor集合添加数据,就会依据"name"的值自动分散到各个片上.
9.生产配置 进入生产环境后,需要更健壮的分片方案,成功的构建分片需要如下条件: 多个配置服务器 多个mongos服务器 每个片都是副本集 正确的设置w
健壮的配置 设置多个配置服务器是很简单的. 设置多个配置服务器和设置一个配置服务器一样 mongod --dbpath "F:\mongo\dbs\config" --port 20000 --logpath "F:\mongo\logs\config\MongoDB.txt" --rest mongod --dbpath "F:\mongo\dbs\config1" --port 20001 --logpath "F:\mongo\logs\config1\MongoDB.txt" --rest mongod --dbpath "F:\mongo\dbs\config2" --port 20002 --logpath "F:\mongo\logs\config2\MongoDB.txt" --rest 启动mongos的时候应将其连接到3个配置服务器上: mongos --port 30000 --configdb 127.0.0.1:20000,127.0.0.1:20001,127.0.0.1:20002 --logpath "F:\mongo\logs\mongos\MongoDB.txt" 配置服务器使用的是两步提交机制,而不是普通的MongoDB的异步复制,来维护集群配置的不同副本.这样能保证集群的状态 的一致性.这意味着,某台配置服务器宕机后,集群的配置信息是只读的.客户端还是能够读写,但是只有所有配置服务器备份了 以后才能重新均衡数据.
多个mongos mongos的数量不受限制,建议针对一个应用服务器只运行一个mongos进程.这样每个应用服务器就可以与mongos进行 本地回话,如果服务器不工作了,就不会有应用试图与不存的mongos通话了
健壮的片 生产环境中,每个片都应是副本集,这样单个服务器坏了,就不会导致整个片失效.用addshard命令就可以将副本集作为片添加, 添加时,只要指定副本集的名称和种子就行了. 如要添加副本集refactor,其中包含一个服务器127.0.0.1:10000(还有别的服务器),就可以用下列命令将其添加到集群中: db.runCommand({"addshard":"refactor/127.0.0.1:10000"}) 如果127.0.0.1:10000服务器挂了,mongos会知道它所连接的是一个副本集,并会使用新的主节点.
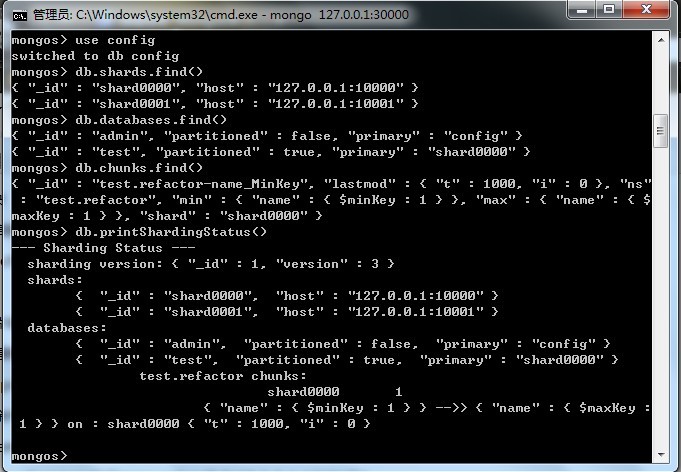
10.管理分片 分片信息主要存放在config数据库上,这样就能被任何连接到mongos的进程访问到了. 配置集合 在shell中连接了mongos,并使用了use config数据库 a.片 可以在shareds集合中查到所有的片 db.shards.find() b.数据库 databases集合含有已经包含在片上的数据库列表和一些相关信息 db.databases.find() 返回的文档解释: "_id" 表示数据库名 "partitioned" 表示是否启用了分片功能 "primary" 这个值与"_id"相对应,表名这个数据的"大本营"在哪里.不论分片与否,数据库总会有个大本营.要是分片的话,创建数据库时会 随机选择一个片.也就是说,大本营是开始创建数据库文档的位置.虽然分片时数据库也会用到很多别的服务器,但会从这个片开始. c.块 块信息存储在chunks集合中.这可以看到数据到底是怎么切分到集群中的 db.chunks.find()
分片命令 获得概要 db.printShardingStatus() 删除片 用removeshard就能从集群中删除片.removeshard会把给定片上的所有块的数据都挪到其他片上 db.runCommand({"removeshard":"127.0.0.1:10001"}) 在挪动过程中,removeshard会显示进程
(责任编辑:IT) |