|
市面上太多kv的缓存,最常用的就属memcache了,但是memcache存在单点问题,不过小日本有复制版本,但是使用的人比较少,redis的出现让kv内存存储的想法成为现实。今天主要内容便是redis主从实现简单的集群,实际上redis的安装配置砸门ttlsa之前就有个文章,废话少说,进入正题吧
Redis简介
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、 list(链表)、set(集合)和zset(有序集合)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操 作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的 是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis 是一个高性能的key-value数据库。 redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部 分场合可以对关系数据库起到很好的补充作用。它提供了Python,Ruby,Erlang,PHP客户端,使用很方便。
1. 下载软件包
# cd /usr/local/src/
# wget http://redis.googlecode.com/files/redis-2.6.11.tar.gz
2. Redis安装
主从都需要安装
# tar -xzvf redis-2.6.11.tar.gz
# mv redis-2.6.11 /usr/local/
# cd /usr/local/redis-2.6.11/
# make
备注:这边就不make install 了,直接使用make好的文件
3. redis配置
找到配置文件/usr/local/redis-2.6.11/redis.conf
修改如下内容:
daemonize no 改为 yes # 是否后台运行
port 6379 改为 12002 # 端口
dir ./ 改为 /data/redis_12002/ 或者/www/redis_12002/ # 数据目录
其他配置请查看相应文档,文章结尾将会附上所有配置参数
4. redis启动与关闭
启动
/usr/local/redis-2.6.11/src/redis-server /usr/local/redis-2.6.11/redis.conf
停止
/usr/local/redis-2.6.11/src/redis-cli -n 12002 shutdown
5. redis命令测试
先登录shell客户端
/usr/local/redis-2.6.11/src/redis-cli -p 12002
set 测试
redis 127.0.0.1:12002> set name abc
OK <---成功
get 测试
redis 127.0.0.1:12002> get name
"abc"
关于list,hash等等就不在演示了,具体查看相关文档
6. Redis主从配置
6.1 只需要修改slave的配置
找到配置文件/usr/local/redis-2.6.11/redis.conf
修改如下内容:
slaveof 192.168.77.211 12002 # slaveof master的ip master的端口
6.2 主从测试
在master set
redis 192.168.77.211:12002> set testms gogogo
OK
在slave get
redis 192.168.77.197:12002> get testms
"gogogo" <---- 获取到的value
7. 附加:redis配置文件
daemonize yes
pidfile /var/run/redis.pid
port 12002
timeout 0
tcp-keepalive 0
loglevel notice
logfile stdout
databases 16
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir /www/redis_12002/
slave-serve-stale-data yes
slave-read-only yes
repl-disable-tcp-nodelay no
slave-priority 100
appendonly no
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
lua-time-limit 5000
slowlog-log-slower-than 10000
slowlog-max-len 128
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-entries 512
list-max-ziplist-value 64
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
如上为单机版本redis的配置文件,如果需要改为主从,只需要增加
slaveof 192.168.77.211(redis master IP) 12002(redis master 端口)
7. 结束语
当然,这还只是集群的第一步,大家可以使用keepalive来实现主的故障转移功能。工作中我们最常用的要数redis主从,所以keepalive + redis实现高可用性集群这边不在讲述。
根据一些测试整理出来的一份方案:
1. Redis 性能
对于redis 的一些简单测试,仅供参考:
测试环境:Redhat6.2 , Xeon E5520(4核)*2/8G,1000M网卡
Redis 版本:2.6.9
客户端机器使用redis-benchmark 简单GET、SET操作:
1. 1单实例测试
1. Value大小:10Byte~1390Byte
处理速度: 7.5 w/s,速度受单线程处理能力限制
2. Value 大小:1400 左右
处理速度突降到5w/s 样子,网卡未能跑满;由于请求包大于MTU造成TCP分包,服务端中断处理请求加倍,造成业务急剧下降。
3. Value大小:>1.5 k
1000M网卡跑满,速度受网卡速度限制
处理速度与包大小大概关系如下:
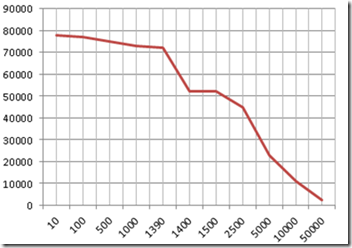
1.2 多实例测试
前提是系统网卡软中断均衡到多CPU核心处理,测试机器网卡开启RSS,有16个队列:
操作:10字节Value SET,服务端开启8个实例,四台客户端服务器每台开启两个redis-benchmark,每个client 速度近4W/s,服务端总处理30w/s左右。
网卡流量:

其中8个单数核心CPU全部耗尽,像是超线程没有利用上,测试已经达到很好效果,就没有继续测试下去了。从单实例跑满一个核心7.5w/s,8个实 例跑满8个核心,30W/s来看,CPU使用和性能提升不成正比, RSS会造成redis-server线程基本每收到一个请求都切换一次CPU核心,软中断CPU占用太高。这种情况RPS/RFS功能也许就很合适 了,RSS只需要映射1~2个核心,然后再讲软中断根据redis-server端口动态转发,保证redis进程都在一个核心上执行,减少进程不必要的 切换。
开多实例可以充分利用系统CPU、网卡处理小包能力。具体看业务场景,考虑包平均大小、处理CPU消耗、业务量。如果多实例是为了提高处理能力,需要注意配置网卡软中断均衡,否则处理能力也无法提升。
2. Redis 持久化
测试策略:AOF + 定时rewriteaof
1. 准备数据量:
1亿,Key:12 字节 Value:15字节,存储为string,进程占用内存12G
2. Dump
文件大小2.8G,执行时间:95s,重启加载时间:112s
2. Bgrewriteaof
文件大小5.1G,执行时间:95s,重启加载时间:165s
3.开启AOF后性能影响(每秒fsync一次):
8K/s SET 操作时:cup 从20% 增加到40%
4.修改1Kw数据:
文件大小:5.6G,重启加载时间:194s
5.修改2K数据
文件大小:6.1G,重启加载时间:200s
另:Redis2.4 版本以后对fsync做了不少优化, bgrewriteaof,bgsave 期间对redis对外提供服务完全无任何影响。
3. Redis 主从复制
因为目前版本没有mysql 主从那样的增量备份,对网路稳定性要求很高,如果频繁TCP连接断开会对服务器和网络带来很大负担。
就目前生产环境主从机器部署同一个机架下,几个月都不会又一次连接断开重连的情况的。
4. keepalived 简介
参考官方文档:http://keepalived.org/pdf/sery-lvs-cluster.pdf
Keepalived 是一个用c写的路由选择软件,配合IPVS 负载均衡实用,通过VRRP 协议提供高可用。目前最新版本1.2.7.Keepalived 机器之间实用VRRP路由协议切换VIP,切换速度秒级,且不存在脑裂问题。可以实现
可以实现一主多备,主挂后备自动选举,漂移VIP,切换速度秒级;切换时可通过运行指定脚本更改业务服务状态。
如两台主机A、B,可以实现如下切换:
1.A 、B 依次启动,A作为主、B为从
2 .主A 挂掉,B接管业务,作为主
3.A 起来,作为从SLAVEOF B
4.B 挂掉,A 切回主
将一台全部作为主,即可实现主从,可做读写分离;也可以通过多个VIP,在一台机器上多个实例中一半主、一半从,实现互备份,两机同时负责部分业务,一台宕机后业务都集中在一台上
安装配置都比较简单:
需要依赖包:openssl-devel(ubuntu 中为 libssl-dev),popt-devel (ubuntu中为libpopt-dev)。
配置文件默认路径:/etc/keepalived/keepalived.conf 也可以手动指定路径,不过要注意的是手动指定需要使用绝对路径。主要要确保配置文件的正确性,keepalived 不会检查配置是否符合规则。
使用keepalived -D 运行,即可启动3个守护进程:一个父进程,一个check健康检查,一个Vrrp,-D将日志写入/var/log/message,可以通过日志查看切换状况。
注意问题:
1. VRRP 协议是组播协议,需要保证主、备、VIP 都在同一个VLAN下
2. 不同的VIP 需要与不同的VRID 对应,一个VLAN 中VRID 不能和其他组冲突
3. 在keepalived 有两个角色:Master(一个)、Backup(多个),如果设置一个为Master,但Master挂了后再起来,必然再次业务又一次切换,这对于有 状态服务是不可接受的。解决方案就是两台机器都设置为Backup,而且优先级高的Backup设置为nopreemt 不抢占。
5. 通过keepalived实现的高可用方案
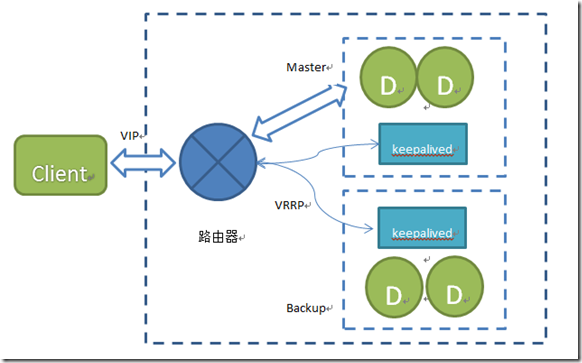
切换流程:
1. 当Master挂了后,VIP漂移到Slave;Slave 上keepalived 通知redis 执行:slaveof no one ,开始提供业务
2. 当Master起来后,VIP 地址不变,Master的keepalived 通知redis 执行slaveof slave IP host ,开始作为从同步数据
3. 依次类推
主从同时Down机情况:
1. 非计划性,不做考虑,一般也不会存在这种问题
2. 、计划性重启,重启之前通过运维手段SAVE DUMP 主库数据;需要注意顺序:
1. 关闭其中一台机器上所有redis,是得master全部切到另外一台机器(多实例部署,单机上既有主又有从的情况);并关闭机器
2. 依次dump主上redis服务
3. 关闭主
4. 启动主,并等待数据load完毕
5. 启动从
删除DUMP 文件(避免重启加载慢)
6. 使用Twemproxy 实现集群方案
一个由twitter开源的c版本proxy,同时支持memcached和redis,目前最新版本为:0.2.4,持续开发中;https://github.com/twitter/twemproxy .twitter用它主要减少前端与缓存服务间网络连接数。
特点:快、轻量级、减少后端Cache Server连接数、易配置、支持ketama、modula、random、常用hash 分片算法。
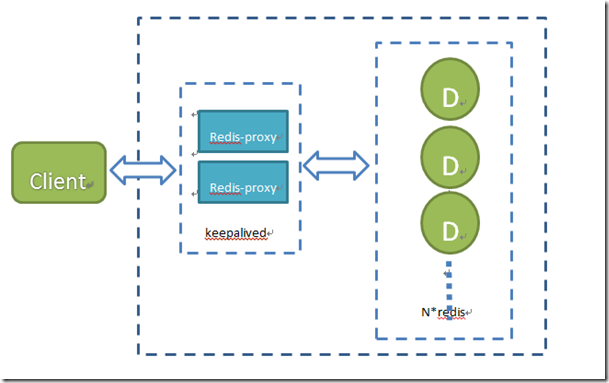
这里使用keepalived实现高可用主备方案,解决proxy单点问题;
优点:
1. 对于客户端而言,redis集群是透明的,客户端简单,遍于动态扩容
2. Proxy为单点、处理一致性hash时,集群节点可用性检测不存在脑裂问题
3. 高性能,CPU密集型,而redis节点集群多CPU资源冗余,可部署在redis节点集群上,不需要额外设备
7 . 一致性hash
使用zookeeper 实现一致性hash。
redis服务启动时,将自己的路由信息通过临时节点方式写入zk,客户端通过zk client读取可用的路由信息。
具体实现见我另外一篇:redis 一致性hash
8 . 监控工具
历史redis运行查询:CPU、内存、命中率、请求量、主从切换等
实时监控曲线
短信报警
使用基于开源Redis Live 修改工具,便于批量实例监控,基础功能都已实现,细节也将逐步完善。
源码地址如下:
https://github.com/LittlePeng/redis-monitor
(责任编辑:IT) |