����Ŀ��������Ŀ��������߲�ѯЧ�ʣ���������ֵ䣬���Ҫ��“mysql”������ʣ����ǿ϶���Ҫ��λ��m��ĸ��Ȼ����������ҵ�y��ĸ�����ҵ�ʣ�µ�sql�����û����������ô�������Ҫ�����е��ʿ�һ������ҵ�����Ҫ�ģ���������ҵ�m��ͷ�ĵ����أ�����w��ͷ�ĵ����أ��Dz��Ǿ������û����������������������ɣ� ����ԭ��
���˴ʵ䣬�������洦�ɼ����������ӣ����վ�ij��α���ͼ���Ŀ¼�ȡ����ǵ�ԭ������һ���ģ�ͨ�����ϵ���С��Ҫ������ݵķ�Χ��ɸѡ��������Ҫ�Ľ����ͬʱ��������¼����˳����¼���Ҳ������������ͨ��ͬһ�ֲ��ҷ�ʽ���������ݡ� ����IO��Ԥ��ǰ���ᵽ�˷��ʴ��̣���ô�����ȼ���һ�´���IO��Ԥ�������̶�ȡ���ݿ����ǻ�е�˶���ÿ�ζ�ȡ���ݻ��ѵ�ʱ����Է�ΪѰ��ʱ�䡢��ת�ӳ١�����ʱ���������֣�Ѱ��ʱ��ָ���Ǵű��ƶ���ָ���ŵ�����Ҫ��ʱ�䣬��������һ����5ms���£���ת�ӳپ������Ǿ�����˵�Ĵ���ת�٣�����һ������7200ת����ʾÿ������ת7200�Σ�Ҳ����˵1������ת120�Σ���ת�ӳپ���1/120/2 = 4.17ms������ʱ��ָ���ǴӴ��̶���������д����̵�ʱ�䣬һ������㼸���룬�����ǰ����ʱ����Ժ��Բ��ơ���ô����һ�δ��̵�ʱ�䣬��һ�δ���IO��ʱ��Լ����5+4.17 = 9ms���ң���������ͦ�����ģ���Ҫ֪��һ̨500 -MIPS�Ļ���ÿ�����ִ��5����ָ���Ϊָ���������ǵ�����ʣ����仰˵ִ��һ��IO��ʱ�����ִ��40����ָ����ݿ��ʮ���������ǧ�����ݣ�ÿ��9�����ʱ�䣬��Ȼ�Ǹ����ѡ���ͼ�Ǽ����Ӳ���ӳٵĶԱ�ͼ������Ҳο���
���ǵ�����IO�Ƿdz��߰��IJ��������������ϵͳ����һЩ�Ż�����һ��IOʱ������ѵ�ǰ���̵�ַ�����ݣ����ǰ����ڵ�����Ҳ����ȡ���ڴ滺�����ڣ���Ϊ�ֲ�Ԥ����ԭ���������ǣ������������һ����ַ�����ݵ�ʱ���������ڵ�����Ҳ��ܿ챻���ʵ���ÿһ��IO��ȡ���������dz�֮Ϊһҳ(page)������һҳ�ж�����ݸ�����ϵͳ�йأ�һ��Ϊ4k��8k��Ҳ�������Ƕ�ȡһҳ�ڵ�����ʱ��ʵ���ϲŷ�����һ��IO��������۶������������ݽṹ��Ʒdz��а����� ���������ݽṹǰ�潲�����������������ӣ������Ļ���ԭ�������ݿ�ĸ����ԣ��ֽ��˲���ϵͳ�����֪ʶ��Ŀ�ľ����ô���˽⣬�κ�һ�����ݽṹ������ƾ�ղ����ģ�һ���������ı�����ʹ�ó��������������ܽ�һ�£�������Ҫ�������ݽṹ�ܹ���Щʲô����ʵ�ܼ��Ǿ��ǣ�ÿ�β�������ʱ�Ѵ���IO����������һ����С��������������dz�������������ô���Ǿ��뵽���һ���߶ȿɿصĶ�·�������Ƿ������������أ���������b+��Ӧ�˶����� b+�����
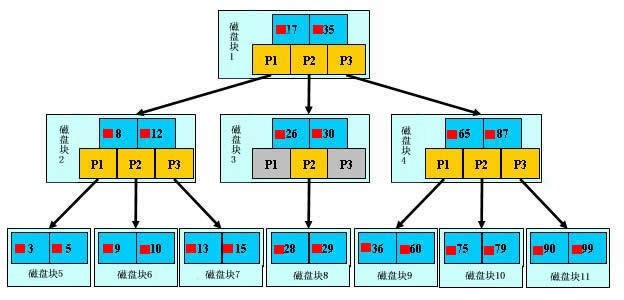
����ͼ����һ��b+��������ֻ˵һЩ�ص㣬dz��ɫ�Ŀ����dz�֮Ϊһ�����̿飬���Կ���ÿ�����̿�����������������ɫ��ʾ����ָ�루��ɫ��ʾ��������̿�1����������17��35������ָ��P1��P2��P3��P1��ʾС��17�Ĵ��̿飬P2��ʾ��17��35֮��Ĵ��̿飬P3��ʾ����35�Ĵ��̿顣��ʵ�����ݴ�����Ҷ�ӽڵ㼴3��5��9��10��13��15��28��29��36��60��75��79��90��99����Ҷ�ӽڵ�ֻ���洢��ʵ�����ݣ�ֻ�洢ָ������������������17��35������ʵ���������ݱ��С� b+���IJ��ҹ�����ͼ��ʾ�����Ҫ����������29����ô���Ȼ�Ѵ��̿�1�ɴ��̼��ص��ڴ棬��ʱ����һ��IO�����ڴ����ö��ֲ���ȷ��29��17��35֮�䣬�������̿�1��P2ָ�룬�ڴ�ʱ����Ϊ�dz��̣���ȴ��̵�IO�����Ժ��Բ��ƣ�ͨ�����̿�1��P2ָ��Ĵ��̵�ַ�Ѵ��̿�3�ɴ��̼��ص��ڴ棬�����ڶ���IO��29��26��30֮�䣬�������̿�3��P2ָ�룬ͨ��ָ����ش��̿�8���ڴ棬����������IO��ͬʱ�ڴ��������ֲ����ҵ�29��������ѯ���ܼ�����IO����ʵ������ǣ�3���b+�����Ա�ʾ�ϰ�������ݣ�����ϰ�������ݲ���ֻ��Ҫ����IO��������߽��Ǿ�ģ����û��������ÿ�������Ҫ����һ��IO����ô�ܹ���Ҫ����ε�IO����Ȼ�ɱ��dz��dz��ߡ� b+������
1.ͨ������ķ���������֪��IO����ȡ����b+���ĸ߶�h�����赱ǰ���ݱ�������ΪN��ÿ�����̿���������������m������h=�S(m+1)N����������Nһ��������£�mԽ��hԽС����m = ���̿�Ĵ�С / ������Ĵ�С�����̿�Ĵ�СҲ����һ������ҳ�Ĵ�С���ǹ̶��ģ����������ռ�Ŀռ�ԽС�������������Խ�࣬���ĸ߶�Խ�͡������Ϊʲôÿ��������������ֶ�Ҫ������С������intռ4�ֽڣ�Ҫ��bigint8�ֽ���һ�롣��Ҳ��Ϊʲôb+��Ҫ�����ʵ�����ݷŵ�Ҷ�ӽڵ�������ڲ�ڵ㣬һ���ŵ��ڲ�ڵ㣬���̿��������������½������������ߡ������������1ʱ�����˻������Ա��� ����ѯ�Ż�����MySQL����ԭ���DZȽϿ���Ķ��������ֻ��Ҫ��һ�����Ե���ʶ��������Ҫ����÷dz��������롣���ǻ�ͷ������һ��ʼ����˵������ѯ���˽�������ԭ��֮����Dz�����ʲô�뷨�أ����ܽ�һ�������ļ������ԭ�� �������ļ���ԭ��
1.����ǰƥ��ԭ�dz���Ҫ��ԭ��mysql��һֱ����ƥ��ֱ��������Χ��ѯ(>��<��between��like)��ֹͣƥ�䣬����a = 1 and b = 2 and c > 3 and d = 4 �������(a,b,c,d)˳���������d���ò��������ģ��������(a,b,d,c)�����������õ���a,b,d��˳�������������� һ����sql�IJ�ѯ�Ż�select count(*) from task where status=2 and operator_id=20839 and operate_time>1371169729 and operate_time<1371174603 and type=2;
��������ƥ��ԭ��sql��������Ӧ����status��operator_id��type��operate_time����������������status��operator_id��type��˳����Եߵ�;
select * from task where status = 0 and type = 12 limit 10; ��ѯ�Ż����� – explain��������explain�������Ŵ�Ҳ���İ���������÷����ֶκ�����Բο�����explain-output��������Ҫǿ��rows�Ǻ���ָ�꣬����rowsС�����ִ��һ���ܿ죨�����⣬����ὲ�����������Ż��������϶������Ż�rows�� ����ѯ�Ż���������
0.�����п����Ƿ���ĺ�����ע������SQL_NO_CACHE (���α༭��IT) |