|
Mysql查询语句执行原理
数据库查询语句如何执行?
DML语句首先进行语法分析,对使用sql表示的查询进行语法分析,生成查询语法分析树。
语义检查:检查sql中所涉及的对象以及是否在数据库中存在,用户是否具有操作权限等
视图转换:将语法分析树转换成关系代数表达式,称为逻辑查询计划;
查询优化:在选择逻辑查询计划时,会有多个不同的表达式,选择最佳的逻辑查询计划;
代码生成:必须将逻辑查询计划转换成物理查询计划,物理查询计划不仅能指明要执行的操作,也给出了这些操作的执行顺序,每步所用的算法,存储数据的方式以及从一个操作传递给另一个操作的方式。
将DML转换成一串可执行的存取操作的过程称为束缚过程,
Mysql查询语句执行过程
这里简单介绍一下mysql数据库,mysql数据库是一款关系型数据库,所谓关系型数据库就是以二维表的形式存储数据,使用行和列方便我们对数据的增删改查。
这篇博客,我们以mysql数据库为例,对一条sql语句的执行流程进行分析。(本篇博客不涉及到表连接)
首先,创建一张student表,字段有自增主键id,学生姓名name,学科subject,成绩grade
建表语句:
DROP TABLE IF EXISTS student;
CREATE TABLE `student` (
`id` int(5) NOT NULL AUTO_INCREMENT,
`name` varchar(10) DEFAULT NULL,
`subject` varchar(10) DEFAULT NULL,
`grade` double(4,1) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=40 DEFAULT CHARSET=utf8;
初始化数据:
INSERT INTO student(`name`,`subject`,grade)VALUES('aom','语文',88);
INSERT INTO student(`name`,`subject`,grade)VALUES('aom','数学',99);
INSERT INTO student(`name`,`subject`,grade)VALUES('aom','外语',55);
INSERT INTO student(`name`,`subject`,grade)VALUES('jack','语文',67);
INSERT INTO student(`name`,`subject`,grade)VALUES('jack','数学',44);
INSERT INTO student(`name`,`subject`,grade)VALUES('jack','外语',55);
INSERT INTO student(`name`,`subject`,grade)VALUES('susan','语文',56);
INSERT INTO student(`name`,`subject`,grade)VALUES('susan','数学',35);
INSERT INTO student(`name`,`subject`,grade)VALUES('susan','外语',77);
INSERT INTO student(`name`,`subject`,grade)VALUES('alice','语文',88);
INSERT INTO student(`name`,`subject`,grade)VALUES('alice','数学',77);
INSERT INTO student(`name`,`subject`,grade)VALUES('alice','外语',100);
INSERT INTO student(`name`,`subject`,grade)VALUES('rajo','语文',33);
INSERT INTO student(`name`,`subject`,grade)VALUES('rajo','数学',55);
INSERT INTO student(`name`,`subject`,grade)VALUES('rajo','外语',55);
下面我们来看一下,数据在数据库中的存储形式。
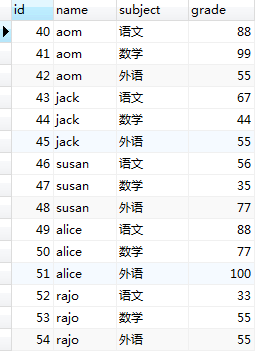
(图1.0)
现在针对这张student表中的数据提出一个问题:要求查询出挂科数目多于两门(包含两门)的前两名学生的姓名,如果挂科数目相同按学生姓名升序排列。
下面是这条查询的sql语句
SELECT `name`,COUNT(`name`) AS num FROM student WHERE grade < 60 GROUP BY `name` HAVING num >= 2 ORDER BY num DESC,`name` ASC LIMIT 0,2;
执行结果:
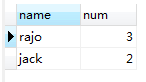
图(1.1)
以上这条sql语句基本上概括了单表查询中所有要注意的点,那么我们就以这条sql为例来分析一下一条语句的执行流程。
1,一条查询的sql语句先执行的是 FROM student 负责把数据库的表文件加载到内存中去,如图1.0中所示。(mysql数据库在计算机上也是一个进程,cpu会给该进程分配一块内存空间,在计算机‘服务’中可以看到,该进程的状态)

图(1.2)
2,WHERE grade < 60,会把(图1.0)所示表中的数据进行过滤,取出符合条件的记录行,生成一张临时表,如下图所示。
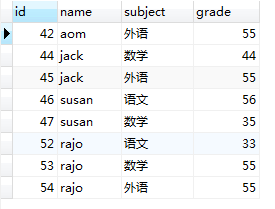
图(1.3)
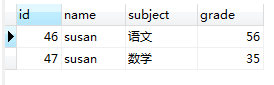
3,GROUP BY `name`会把图(1.3)的临时表切分成若干临时表,我们用下图来表示内存中这个切分的过程。
 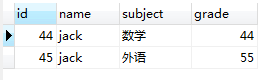  
4,SELECT 的执行读取规则分为sql语句中有无GROUP BY两种情况。
(1)当没有GROUP BY时,SELECT 会根据后面的字段名称对内存中的一张临时表整列读取。
(2)当查询sql中有GROUP BY时,会对内存中的若干临时表分别执行SELECT,而且只取各临时表中的第一条记录,然后再形成新的临时表。这就决定了查询sql使用GROUP BY的场景下,SELECT后面跟的一般是参与分组的字段和聚合函数,否则查询出的数据要是情况而定。另外聚合函数中的字段可以是表中的任意字段,需要注意的是聚合函数会自动忽略空值。
我们还是以本例中的查询sql来分析,现在内存中有四张被GROUP BY `name`切分成的临时表,我们分别取名为 tempTable1,tempTable2,tempTable3,tempTable4分别对应图(1.4)、图(1.5)、图(1.6),图(1.7)下面写四条"伪SQL"来说明这个查询过程。
SELECT `name`,COUNT(`name`) AS num FROM tempTable1;
SELECT `name`,COUNT(`name`) AS num FROM tempTable2;
SELECT `name`,COUNT(`name`) AS num FROM tempTable3;
SELECT `name`,COUNT(`name`) AS num FROM tempTable4;
最后再次成新的临时表,如下图:
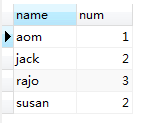
图(1.8)
5,HAVING num >= 2对上图所示临时表中的数据再次过滤,与WHERE语句不同的是HAVING 用在GROUP BY之后,WHERE是对FROM student从数据库表文件加载到内存中的原生数据过滤,而HAVING 是对SELECT 语句执行之后的临时表中的数据过滤,所以说column AS otherName ,otherName这样的字段在WHERE后不能使用,但在HAVING 后可以使用。但HAVING的后使用的字段只能是SELECT 后的字段,SELECT后没有的字段HAVING之后不能使用。HAVING num >= 2语句执行之后生成一张临时表,如下:
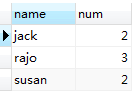
图(1.9)
6,ORDER BY num DESC,`name` ASC对以上的临时表按照num,name进行排序。
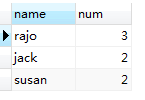
7,LIMIT 0,2取排序后的前两个。
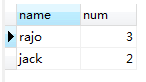
以上就是一条sql的执行过程,同时我们在书写查询sql的时候应当遵守以下顺序。
SELECT XXX FROM XXX WHERE XXX GROUP BY XXX HAVING XXX ORDER BY XXX LIMIT XXX;
(责任编辑:IT) |