|
话不多说,直接开始
以生成“用户表”测试数据为例
第一步:生成基础数据
//生成基础数据
delimiter $$
create procedure insert_llll(in start int(10),in max_num int(10))
begin
declare i int default 0;
declare newChar varchar(100) default '';
declare j int default 0;
set autocommit = 0;
repeat
set i = i +1;
set j = start+i;
set newChar = concat('', LPAD((i), 3, '0'));
insert into user_tb (Uid, head,wxAcount,wxName,zfbAcount,zfbName,tel,note) values (j,
substring(MD5(RAND()),1, RAND()*30), substring(MD5(RAND()),1, RAND()*20), substring(MD5(RAND()),1, RAND()*10), substring(MD5(RAND()),1, RAND()*10), substring(MD5(RAND()),1, RAND()*10), substring(MD5(RAND()),1, RAND()*10),
newChar);
until i = max_num
end repeat;
commit;
end $$
delimiter ;
//调用存储过程,生成note从001到999的999个数据
call insert_llll(1000000,999);
生成结果部分截图如下:
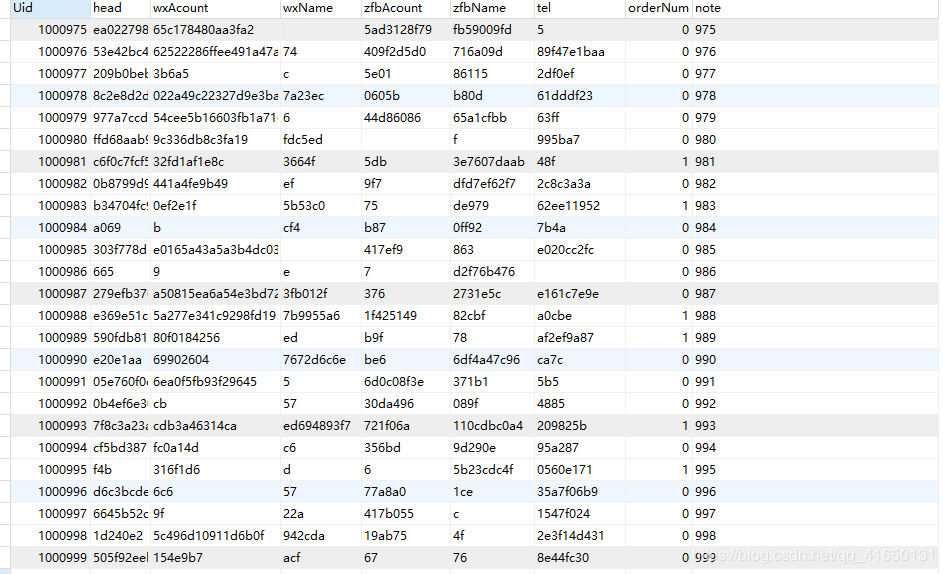
这里生成的最初的999个数据是最基础的原始数据,是最原始的“父编码”
第二步:生成之后的数据
基本原理:
1)从表中随机抽取一条纪录,提取其中的note值,将提取到的note值作为“父编码”;
2)随机一个1~200之间的整数(j),j也就是“父编码”的紧接着的下一级的子编码个数;
3)从1开始,一直到 j 进行循环,在每一次循环中插入 “父编码”+“xxx”,如:“父编码”为001,循环到第54个,那么“xxx”也就是054,最终插入的“新note”就是 001054。
4)这只是大致原理,最重要的还是看代码
delimiter $$
CREATE PROCEDURE `insert_la4`(in start int(10),in max_num int(10))
begin
/***** i 总循环计数 ******/
declare i int default 0;
declare k int default 0;
/***** j 子循环计数 ******/
declare j int default 0;
declare count int default 0;
/***** str1 父编码 ******/
declare str1 text default '';
/***** newChar 新生产的子编码部分 ******/
declare newChar varchar(100) default '';
/***** 最终插入时的note值(由str1和newChar拼凑而成) ******/
declare res text default '';
#set autocommit = 0 //把autocommit设置成0,这样可以只提交一次,否则。。。。。
set autocommit = 0;
set k = start;
repeat
set i = i +1;
SELECT note into str1
FROM user_tb AS t1 JOIN (SELECT ROUND(RAND() * ((SELECT MAX(Uid) FROM user_tb)-(SELECT MIN(Uid) FROM user_tb))+(SELECT MIN(Uid) FROM user_tb)) AS Uid) AS t2
WHERE t1.Uid >= t2.Uid
ORDER BY t1.Uid LIMIT 1;
set j = 1+RAND()*200;
while count<j do
set count = count +1;
/***** 将count变为001型的格式 ******/
set newChar = concat('', LPAD((count), 3, '0'));
set res = concat(str1, newChar);
set k = k+1;
insert into user_tb (head,wxAcount,wxName,zfbAcount,zfbName,tel,note) values (
substring(MD5(RAND()),1, RAND()*10), 1, 1, 1, 1, 1,
res);
end while;
set count = 0;
until i = max_num
end repeat;
commit;
end $$
delimiter ;
执行,ok,完美。几分钟后成功生成500W条数据
部分结果如下

备注:
1)如果要运行此存储过程,最好先把所有注释去掉,防止意外(!!!???);
2)推荐设计表时将Uid设为int自增型,否则每次插入时数据库都要进行一次查询(确保Uid,即主键不重复),这将花费大量大量大量的时间。(毕竟只是测试数据,将Uid设为int型也没啥大不了);
3)当然,这里的代码并不适合其他人,本文章仅供了解其中的大概原理
4)mysql自带的随机抽取函数效率太慢,因此从网上搜了一个
5)其实还可以继续提高效率,合并insert之类的,但现在的已经完全足够了,再花时间研究那些东西,数据都能生成几亿条了。。。。。。。
(责任编辑:IT) |