|
为什么你写的sql查询慢?为什么你建的索引常失效?通过本章内容,你将学会MySQL性能下降的原因,索引的简介,索引创建的原则,explain命令的使用,以及explain输出字段的意义。助你了解索引,分析索引,使用索引,从而写出更高性能的sql语句。还在等啥子?撸起袖子就是干! 案例分析
我们先简单了解一下非关系型数据库和关系型数据库的区别。
我们先通过两个简单的例子来入门。后面会详细介绍各个参数的作用和意义。 场景一:订单导入,通过交易号避免重复导单业务逻辑:订单导入时,为了避免重复导单,一般会通过交易号去数据库中查询,判断该订单是否已经存在。 最基础的sql语句mysql> select * from itdragon_order_list where transaction_id = "81X97310V32236260E"; +-------+--------------------+-------+------+----------+--------------+----------+------------------+-------------+-------------+------------+---------------------+ | id | transaction_id | gross | net | stock_id | order_status | descript | finance_descript | create_type | order_level | input_user | input_date | +-------+--------------------+-------+------+----------+--------------+----------+------------------+-------------+-------------+------------+---------------------+ | 10000 | 81X97310V32236260E | 6.6 | 6.13 | 1 | 10 | ok | ok | auto | 1 | itdragon | 2017-08-18 17:01:49 | +-------+--------------------+-------+------+----------+--------------+----------+------------------+-------------+-------------+------------+---------------------+ mysql> explain select * from itdragon_order_list where transaction_id = "81X97310V32236260E"; +----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+-------------+ | 1 | SIMPLE | itdragon_order_list | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 33.33 | Using where | +----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+-------------+
查询的本身没有任何问题,在线下的测试环境也没有任何问题。可是,功能一旦上线,查询慢的问题就迎面而来。几百上千万的订单,用全表扫描?啊?哼! 初步优化:为transaction_id创建索引mysql> create unique index idx_order_transaID on itdragon_order_list (transaction_id); mysql> explain select * from itdragon_order_list where transaction_id = "81X97310V32236260E"; +----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------+ | 1 | SIMPLE | itdragon_order_list | NULL | const | idx_order_transaID | idx_order_transaID | 453 | const | 1 | 100 | NULL | +----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------+
这里创建的索引是唯一索引,而非普通索引。 再次优化:覆盖索引mysql> explain select transaction_id from itdragon_order_list where transaction_id = "81X97310V32236260E"; +----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------------+ | 1 | SIMPLE | itdragon_order_list | NULL | const | idx_order_transaID | idx_order_transaID | 453 | const | 1 | 100 | Using index | +----+-------------+---------------------+------------+-------+--------------------+--------------------+---------+-------+------+----------+-------------+
这里将select * from 改为了 select transaction_id from 后 场景二,订单管理页面,通过订单级别和订单录入时间排序
业务逻辑:优先处理订单级别高,录入时间长的订单。 最基础的sql语句mysql> explain select * from itdragon_order_list order by order_level,input_date; +----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+----------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+----------------+ | 1 | SIMPLE | itdragon_order_list | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100 | Using filesort | +----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+----------------+
首先,采用全表扫描就不合理,还使用了文件排序Using filesort,更加拖慢了性能。 初步优化:为order_level,input_date 创建复合索引mysql> create index idx_order_levelDate on itdragon_order_list (order_level,input_date); mysql> explain select * from itdragon_order_list order by order_level,input_date; +----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+----------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+----------------+ | 1 | SIMPLE | itdragon_order_list | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 100 | Using filesort | +----+-------------+---------------------+------------+------+---------------+------+---------+------+------+----------+----------------+ 创建复合索引后你会惊奇的发现,和没创建索引一样???都是全表扫描,都用到了文件排序。是索引失效?还是索引创建失败?我们试着看看下面打印情况 mysql> explain select order_level,input_date from itdragon_order_list order by order_level,input_date; +----+-------------+---------------------+------------+-------+---------------+---------------------+---------+------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------------------+------------+-------+---------------+---------------------+---------+------+------+----------+-------------+ | 1 | SIMPLE | itdragon_order_list | NULL | index | NULL | idx_order_levelDate | 68 | NULL | 3 | 100 | Using index | +----+-------------+---------------------+------------+-------+---------------+---------------------+---------+------+------+----------+-------------+
将select * from 换成了 select order_level,input_date from 后。type从all升级为index,表示(full index scan)全索引文件扫描,Extra也显示使用了覆盖索引。可是不对啊!!!!检索虽然快了,但返回的内容只有order_level和input_date 两个字段,让业务同事怎么用?难道把每个字段都建一个复合索引? mysql> explain select * from itdragon_order_list force index(idx_order_levelDate) order by order_level,input_date; +----+-------------+---------------------+------------+-------+---------------+---------------------+---------+------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------------------+------------+-------+---------------+---------------------+---------+------+------+----------+-------+ | 1 | SIMPLE | itdragon_order_list | NULL | index | NULL | idx_order_levelDate | 68 | NULL | 3 | 100 | NULL | +----+-------------+---------------------+------------+-------+---------------+---------------------+---------+------+------+----------+-------+ 再次优化:订单级别真的要排序么?
其实给订单级别排序意义并不大,给订单级别添加索引意义也不大。因为order_level的值可能只有,低,中,高,加急,这四种。对于这种重复且分布平均的字段,排序和加索引的作用不大。 mysql> explain select * from itdragon_order_list where order_level=3 order by input_date; +----+-------------+---------------------+------------+------+---------------------+---------------------+---------+-------+------+----------+-----------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------------------+------------+------+---------------------+---------------------+---------+-------+------+----------+-----------------------+ | 1 | SIMPLE | itdragon_order_list | NULL | ref | idx_order_levelDate | idx_order_levelDate | 5 | const | 1 | 100 | Using index condition | +----+-------------+---------------------+------------+------+---------------------+---------------------+---------+-------+------+----------+-----------------------+ 和之前的sql比起来,type从index 升级为 ref(非唯一性索引扫描)。索引的长度从68变成了5,说明只用了一个索引。ref也是一个常量。Extra 为Using index condition 表示自动根据临界值,选择索引扫描还是全表扫描。总的来说性能远胜于之前的sql。 上面两个案例只是快速入门,我们需严记一点:优化是基于业务逻辑来的。绝对不能为了优化而擅自修改业务逻辑。如果能修改当然是最好的。 索引简介
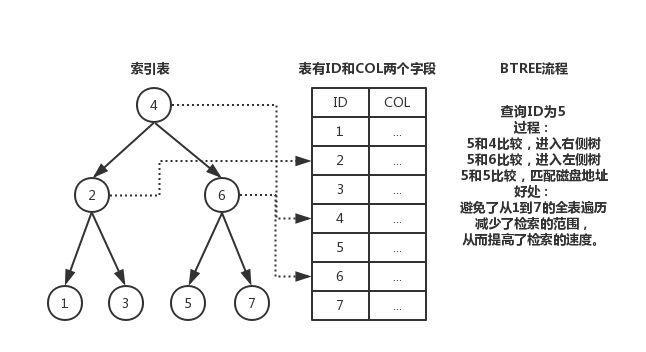
官方定义:索引(Index) 是帮助MySQL高效获取数据的数据结构。
创建索引的优势
创建索引的劣势 索引分类我们常说的索引一般指的是BTree(多路搜索树)结构组织的索引。其中还有聚合索引,次要索引,复合索引,前缀索引,唯一索引,统称索引,当然除了B+树外,还有哈希索引(hash index)等。
单值索引:一个索引只包含单个列,一个表可以有多个单列索引
基本语法: create [unique] index indexName on tableName (columnName...) alter tableName add [unique] index [indexName] on (columnName...) 删除: drop index [indexName] on tableName 查看: show index from tableName
哪些情况需要建索引:
哪些情况不要建索引: 性能分析MySQL 自身瓶颈
MySQL自身参见的性能问题有磁盘空间不足,磁盘I/O太大,服务器硬件性能低。 explain 分析sql语句使用explain关键字可以模拟优化器执行sql查询语句,从而得知MySQL 是如何处理sql语句。 +----+-------------+-------+------------+------+---------------+-----+---------+------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+-----+---------+------+------+----------+-------+ id
select 查询的序列号,包含一组可以重复的数字,表示查询中执行sql语句的顺序。一般有三种情况: select_type
select 查询的类型,主要是用于区别普通查询,联合查询,嵌套的复杂查询 partitions表所使用的分区,如果要统计十年公司订单的金额,可以把数据分为十个区,每一年代表一个区。这样可以大大的提高查询效率。 type
这是一个非常重要的参数,连接类型,常见的有:all , index , range , ref , eq_ref , const , system , null 八个级别。 possible_keys显示查询语句可能用到的索引(一个或多个或为null),不一定被查询实际使用。仅供参考使用。 key显示查询语句实际使用的索引。若为null,则表示没有使用索引。 key_len显示索引中使用的字节数,可通过key_len计算查询中使用的索引长度。在不损失精确性的情况下索引长度越短越好。key_len 显示的值为索引字段的最可能长度,并非实际使用长度,即key_len是根据表定义计算而得,并不是通过表内检索出的。 ref显示索引的哪一列或常量被用于查找索引列上的值。 rows根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数,值越大越不好。 extra
Using filesort: 说明MySQL会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。MySQL中无法利用索引完成的排序操作称为“文件排序” 。出现这个就要立刻优化sql。 filtered一个百分比的值,和rows 列的值一起使用,可以估计出查询执行计划(QEP)中的前一个表的结果集,从而确定join操作的循环次数。小表驱动大表,减轻连接的次数。
通过explain的参数介绍,我们可以得知: 性能下降的原因
从程序员的角度 总结
1 索引是排好序且快速查找的数据结构。其目的是为了提高查询的效率。 到这里,MySQL的索引优化分析就结束了,有什么不对的地方,大家可以提出来。如果觉得不错可以点一下推荐。 (责任编辑:IT) |