|
like关键字我们也是经常使用,用来模糊查询用户名,那么like如何进行优化呢?这篇博客就简单讨论一下like的优化,但是真实的生产环境要比这复杂多了。
1.%号不放最左边
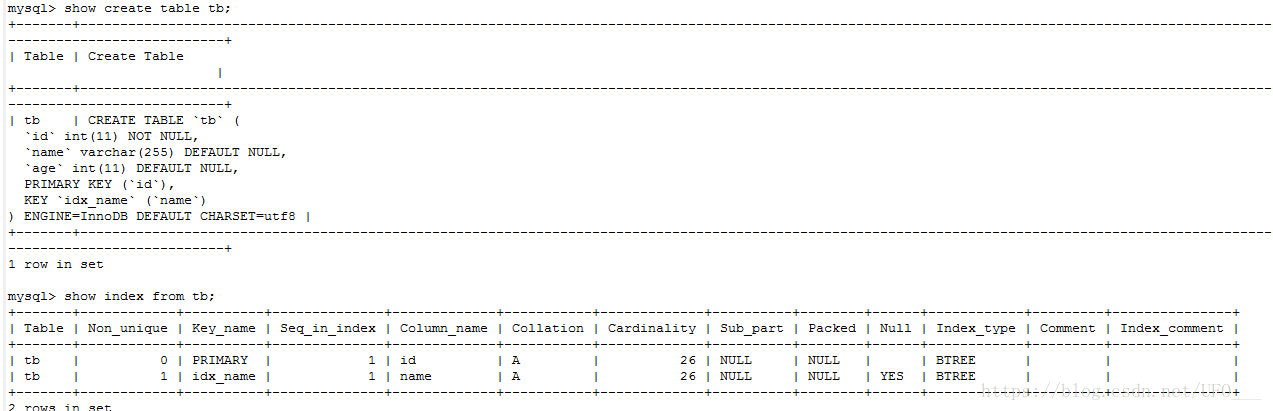
先创建表和索引。
然后进行查询【explain select * from tb where name like 'e%';】

可以看到我们的查询使用上了idx_name这个索引,因为我们的 'e%' 规定了只要以字符 'e' 开头的name,所以MySQL使用上了我们建立的索引。
把sql修改一下在进行查询【explain select * from tb where name like 'e%y_t';】

同样使用上了建立的索引。
再来修改一下【explain select * from tb where name like '%e%';】

可以看到这个时候就无法使用索引了,开头是不确定的,MySQL也无法进行优化了,只能扫描表了。
2.使用覆盖索引
如果业务需要%就放开头我们也没办法,一般情况需求都是这样的,毕竟优化还是为业务服务的。
这个时候可以考虑使用覆盖索引(关于覆盖索引:MySQL系列-优化之覆盖索引),假设业务需要通过name来获取用户的age的话,我们可以对name、age字段建立复合索引。
创建复合索引idx_name_age:

执行sql【explain select name,age from tb where name like '%e%';】
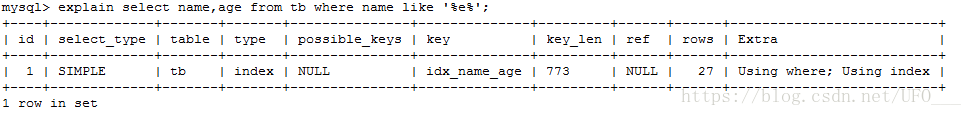
可以看到,查询是覆盖索引的,起码比全表扫描要好。
如果需要更多字段的数据而不单单是age的话,可以进行两次查询,第一次通过name来获取id(这一步是索引扫描),第二步拿获取来的数据在进行id匹配查询(这一步效率很高,ref或者const)。
(责任编辑:IT) |