|
吴悦,腾讯大讲堂特约讲师,腾讯T4技术专家。先后参与腾讯分布式文件系统(TFS),K-V存储,SQL集群,接入网关(TGW)的设计与研发。见证了腾讯NoSQL从07年诞生,08、09批量应用,10年至今应用于腾讯开放平台让更多的第三方开发者使用;关注于构建具有低成本、高性能、高可用,可扩展,易运营特点的互联网海量后台服务。目前任腾讯架构平台部平台开发中心技术总监。 此文已发表在《程序员》杂志。 一、前言 NoSQL的历史很长,最早可以追朔到Berkeley DB等嵌入式数据库的年代。互联网行业的高速发展对大数据的需求,为NoSQL的发展起到了推波助澜的作用。互联网时代的NoSQL,源起于Google为解决大数据的存储与计算而提出的GFS + Bigtable + Map Reduce。随后Hadoop(Hdfs+Hbase+MapReduce)、 Hypertable、Memcached,Tokyo cabinet,Redis, Dynamo,Cassandra等等NoSQL产品雨后春笋般的推出,使得NoSQL技术广泛应用于互联网各个领域。 在腾讯过去的几年中,互联网社交平台取得令人瞩目的发展。包括平台用户基数、在线、应用数都取得突飞猛进的增长;另外随着开放的加剧,还有越来越多的第三方选择社交平台开发应用。这些外部条件的变化对技术平台的而言,也带来了新挑战:除需要为用户提供更强的海量服务外,同时还需要提供开放的软件基础架构来帮助第三方开发海量服务。 在解决这些问题的实践中,总结了很多经验。其中关键一点则是通过NoSQL技术来构建海量服务的数据层,并通过分析和总结出不同的业务场景和技术特点,为各种场景提供更合适的数据层解决方案。具体而言:
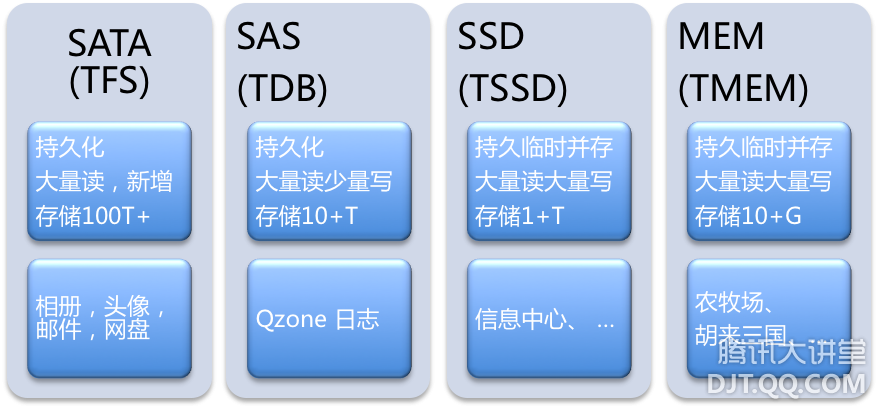
二、【2006~2008】因QQ相册而研发TFS、TDB 回顾NoSQL在腾讯的发展历程,需要从2006年腾讯分布式文件系统TFS的研发开始谈起,TFS目的是在公司内部构建统一的存储平台,为各个BU提供文件系统服务。第一期的重点是要能够支持到QQ相册的快速发展。当时QQ相册使用传统企业级存储硬件+标准Linux文件系统的老架构,在数百亿的图片数,每天近10亿长尾下载的规模下已难以为继。通过分析,老架构主要有下面三个问题:
TFS采用廉价的存储设备,在软件层面使用类似软raid的技术来满足系统基于不可靠硬件的可靠性要求。将对象数据与元数据分离:对象数据存储采用自研的CHUNK文件系统,inode节点更小,空间分配采用了基于append + delete更为紧凑的管理方式,使得单机最大可以支持数10亿的图片文件;元数据使用MYSQL存储。系统架构如下:
上面的架构很好的满足了数百亿级别规模下的QQ相册业务发展。大致在2007年的时候,QQ相册采用TFS的新架构趋于稳定,同时业务发展需要,对用户上传也放开了限制,用户上传浏览的活跃度上升的一个新的量级,用户目录、文件索引等元数据规模突破千亿。在使用MySQL应对如此大规模的元数据的场景下,暴露出一些问题:
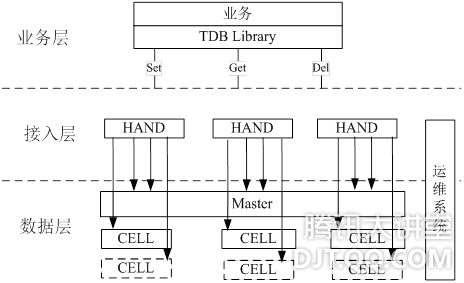
针对上面的问题结合业务需求,2007年底研发出TDB用以替代MySQL,TDB是一个典型的K-V存储系统。其特点是:接口简单,性能高效,具备优秀的扩展能力。
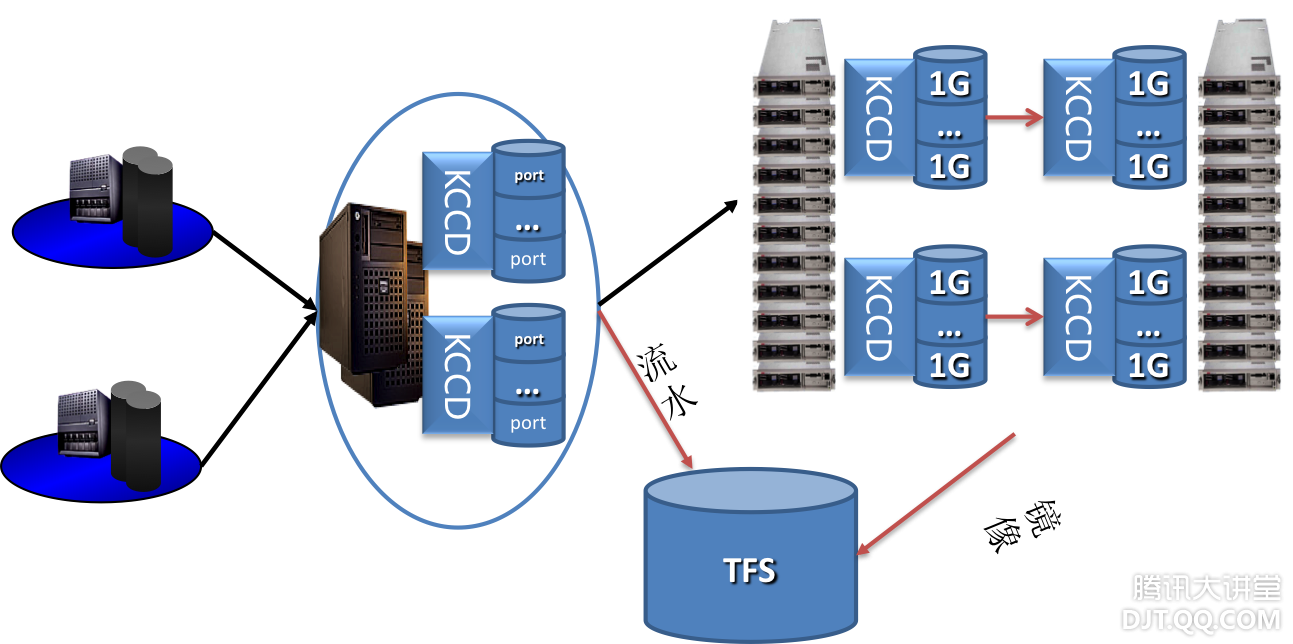
数据层面,索引设计使用HASH,通过KEY可直接定位磁盘物理偏移,避免B树设计导致的二次定位磁盘性能开销,解决索引低效的问题。同时采用16MB大磁盘块的设计,使得TDB的数据迁移速度可达网卡性能上限,解决迁移性能问题。另外系统可控性更强,一方面因为是专用场景,所以可以简化设计,方便定位问题与优化更新;另一方面打通了存储系统到磁盘IO的控制路径,避免MySQL的系统天花板。 接入层面,为业务提供透明的访问代理,从而实现无缝的水平扩展。由于接口简单,并且是PAAS,业务使用非常方便,从2007年底开始,在Qzone、朋友、群空间等社区应用中逐步取得了广泛应用。 三、【2009】Social Game催生的TMEM 2009年有一款叫农场的游戏大家应该不会陌生,农场的火爆带动了一批Social Game应用的兴起。其典型特点(1)好友间互动性很强,用户背包数据会被频繁的修改与读取;(2)交叉访问,无明显热点数据;举个例子来说,对于传统的应用来说,用户间交互相对较弱,活跃用户数据就是热点数据;而对于Social Game而言,用户交互性强,通过交叉访问,活跃用户也会频繁访问与修改非活跃用户数据。(3)放大效果明显;比如用户每次登陆,通常会遍历好友的农场,会遍历菜地偷菜,捉虫,一次偷菜、捉虫会导致多个用户的多个背包数据修改。这些行为一方面导致整个系统中无明显热点数据,用户传统的读缓存+写落地的方式则难以很好的满足这些业务的需求;另一方面庞大的用户基数之上的火爆应用,往往单款应用就会有每秒数百万次的访问量,这种海量访问不光对存储层面,同时对网络通讯层面提出更高的性能要求。 针对以上新兴面临的问题,很明显TDB并不能很好的解决,所以09年围绕着网络通信,内存持久化两个方面,做了大量的设计与论证。2009年底左右推出新的服务TMEM。
核心有两点:
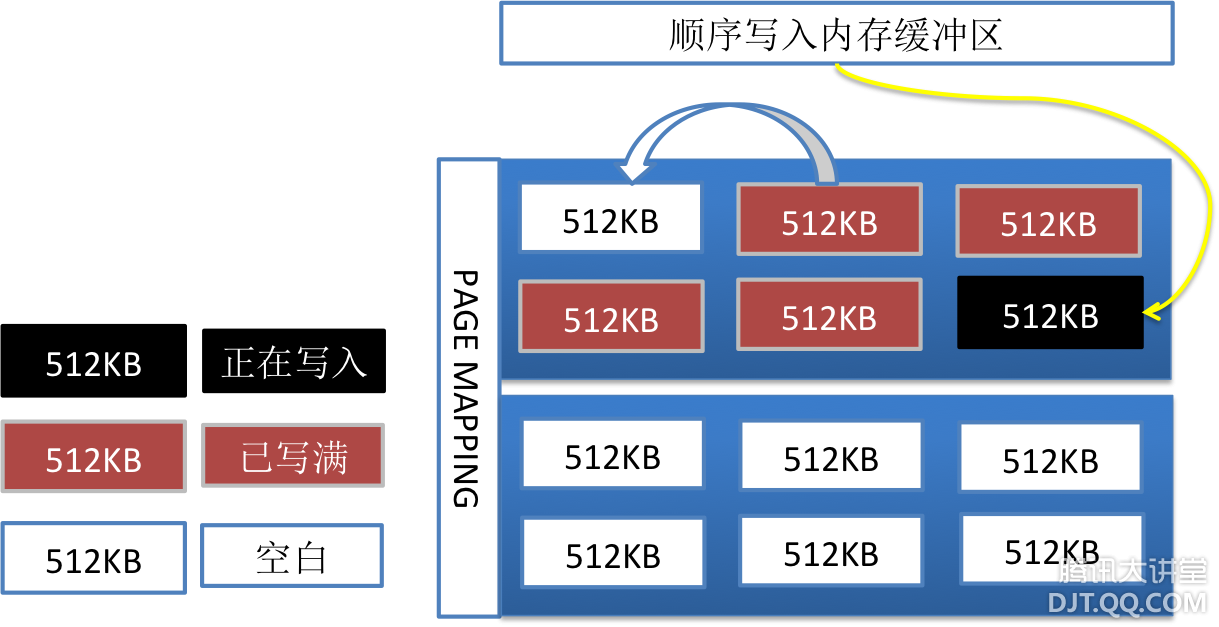
TMEM的出现很好的满足了业务海量访问的需求。不过毕竟内存介质的成本比较高,所以TMEM在小数据量的场景下,性价比比较高。但针对于中大数据规模的海量访问的场景,使用TMEM的成本偏高,而使用SAS介质的TDB,则IO性能又不能很好的满足。比如社区中各类应用产生的Feeds,数据量数十TB至数百TB,每天访问量数十亿至数百亿,应对该场景传统的做法必须得是前端内存缓存加上后端落地存储。分级存储导致的内存数据保护,各级间数据一致性,另外最为关键的一点,与Social Game类似,Feeds也是典型交叉访问,热点不是非常明显,等等这些都是数据层亟需解决的难题。 四、【2010】顺SSD之势的TSSD 在2010年的时候,引入了SSD存储介质,开始构建TSSD K-V存储系统。SSD的特点:有着很好的随机读取性能,往往单盘可达数万IOPS,远高于SAS、SATA的数百随机IOPS。容量方面也接近SAS盘的容量,可达数百GB。但SSD也有弊端:(1)寿命有限,随机写入的寿命相对于顺序写入为1/10左右;(2)随机写入场景,性能易受干扰,毛刺率较高;具体而言:受限于物理机制,SSD的存储单元只能先擦除才能写入,并且擦除次数有限,针对NAND芯片,在3000~5000次左右。其中擦除单元是512KB,写入单元是4KB。随机写入的场景,会带来写入放大。 因此应用SSD存储介质,必须优化随机写入性能。TSSD通过构建地址映射,增加随机写入内存缓冲区,实现随机转顺序的写入;通过定期的垃圾回收机制,回收垃圾数据。
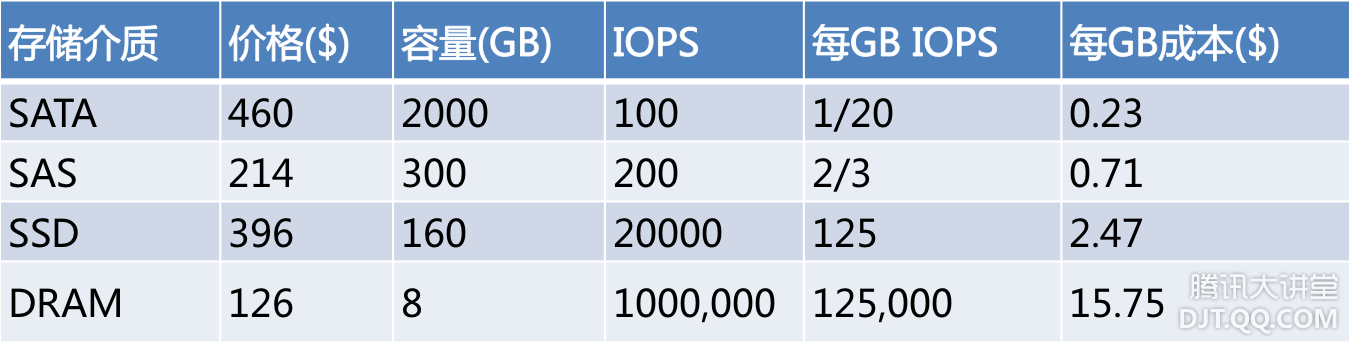
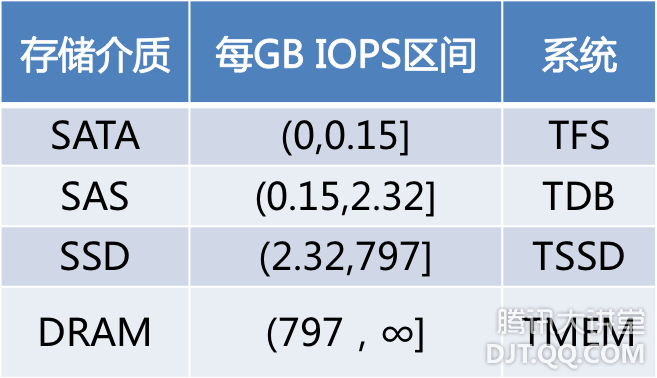
TSSD系统中,单机可以支持容量数TB,性能随机数万次IOPS。这样基于TSSD使用简单的架构,更少的机器便可支持到容量数十至数百TB,性能数十万IOPS的Feeds类应用。 五、NoSQL小结 至此,业已构建出基于内存、SSD、SAS、SATA各类存储介质的存储系统,在上面也已提到各类存储系统所对应的使用场景。实际应用中,各种业务场景千变万化,有没有统一的方法来判别和选择合适的存储系统呢?大致在1987年,Jim Gray发表了这个"五分钟法则"的观点,简而言之,如果一条记录频繁被访问,就应该放到内存里,否则的话就应该待在硬盘上按需要再访问。这个临界点就是五分钟。这个看似经验公式,隐含的是硬件性能和成本两个方面的因素。大约在1997年的时候,Jim Gray再次回顾了该法则,并引入了SSD,验证了该法则依然正确。这里不在赘述该法则。 很多情况下需要一种直接根据业务的访问模型,因此使用IO访问密度,即每GB的存储的IO访问次数,会更为直观。那看看目前常用的几种存储介质:
SATA:希捷2TB/7200转/SATA(ST32000644NS) SAS:希捷300GB/15000转/SAS(ST3300657SS) SSD:Intel 160GB X25-M G2 34nm DRAM:三星8GB DDR3 1333 REG ECC (中关村在线报价,人民币美元汇率:6.3157,2012/4/16) 根据业务IO访问密度,选择合适的存储介质,就是根据存储介质的IO访问密度特性与价格来选择性价比最高的存储介质,即找到每种存储介质之间IO访问密度的临界点。 临界点G(X,Y).IO per sec per GB = X.IO per sec per GB * Y.price per GB / X. price per GB,X与Y分别表示对比的两种存储介质,且Y.IO per sec per GB 大于 X.IO per sec per GB。根据上面的公式,可以得到表格如下:
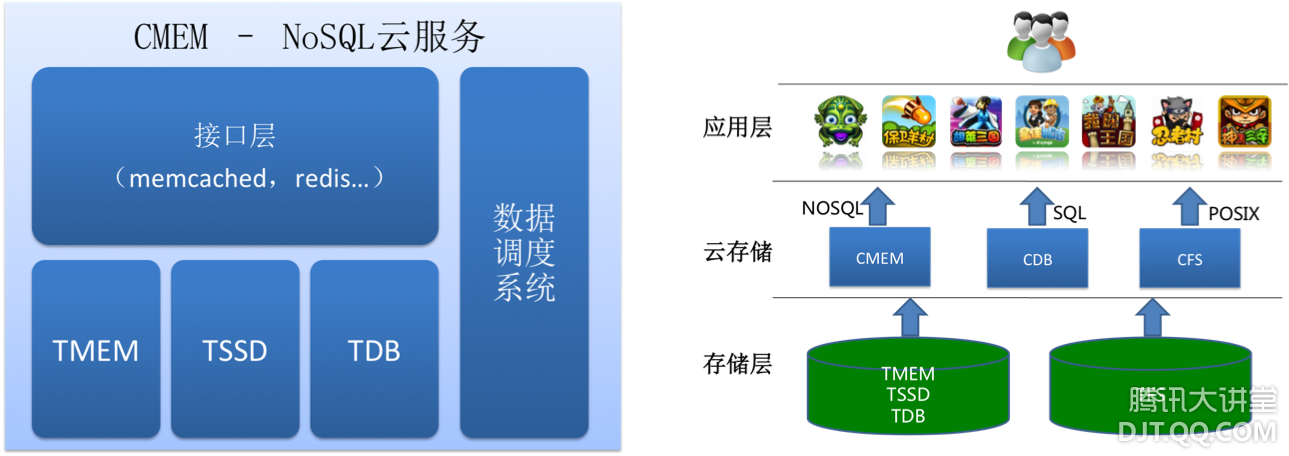
怎么理解上面的公式呢?举计算SATA与SAS之间的临界点为例,G(SATA,SAS).IO per sec per GB = SATA.IO per sec per GB* SAS.price per GB/SATA.price per GB = 1/20 * 0.71/0.23 = 0.15 per sec per GB。假设现在有1GB的数据,访问密度是X,X小于2/3,那么使用SAS介质则需要0.71$,如果选择SATA介质,则需要X/(1/20) * 0.23 $。当X为0.15时,选择SATA与SAS的成本是一样的,当大于0.15时,则使用SATA的成本相对于SAS则高;否则则低。SAS比SSD,SSD比DRAM也是类似。 实际上对于一款存储介质而言,IO访问特性与单位每GB的成本是决定了其存在与生命力的关键因素。通常来讲,其IO访问特性一般来讲不会有革命性的变化,而单位每GB的成本却是可以控制的,所以厂商总是会围绕容量来不断的深入优化。 六、开放的挑战 2010年底开始,随着开放的加剧,越来越多的第三方选择社交平台开发应用。这些外部条件的变化对技术平台的而言,也带来了新挑战:除需要为用户提供更强的海量服务外,同时还需要提供开放的软件基础架构来帮助第三方开发海量服务。现有已成熟的NoSQL的架构能否被外部第三方接受,其关键的一点是接口的友好性和兼容性。采用的标准化的接口,会大大降低外部开发者的使用门槛。因此,在2011年推出了CMEM 的NoSQL云存储服务,开发者可直接使用memcached接口,并即将支持redis接口。同时也提供了SQL云存储服务,开发者可用MySQL客户端直接访问。后续推出CFS文件系统云存储服务,开发者可使用posix接口访问到TFS。
回顾TFS、TDB、TMEM、TSSD、CMEM、CDB、CFS等一系列存储系统过去近6个年头的演进发展。有两点经验可供分享: 1、建议NoSQL开发者尽量选择构建PAAS服务。一方面对业务开发者而言,不需关心日常运维,使用更为方便,易于接受;另一方面更容易形成用户需求提出、实现与发布的闭环,从而方便小步快跑,快速迭代出完善的服务。 2、建议中小业务开发者尽量使用云服务。通常一个NoSQL服务所面临的挑战有两个方面:一方面是大家所直观感受的产品本身;另一方面是服务背后的运营体系。类似与铁路系统、消防系统,用户所直观感受到的火车、铁路,消防栓、消防车只是整个服务其中一个部分,是冰山海平面之上的部分;用户所感受不到的铁路规划、调度系统、消防规划、消防演练,报警系统等后台运营体系通常是冰山海平面以下的部分,往往需要有大量的人力和财力投入,可能是中小公司难以投入的。而在没有稳固的后台运营体系支撑下,类似动车事故、火灾等生产系统故障难以避免,并最终为业务带来不可估量的损失。
从过去几年来看,硬件在变,存储介质的性能与容量在不断提升,并不断会有新存储介质的产生;业务在变,不断有新兴的产品和新的业务体验,并对后台系统提出新的挑战和需求;唯一不变的就是需要拥抱变化,为业务提供更贴切与更优化的存储服务。想了解更多关于腾讯TFS、TDB、TMEM、TSSD、CMEM、CDB、CFS等一系列存储系统过去近6个年头的演进发展,大家可以到腾讯大讲堂网站(djt.qq.com)翻阅架构平台部的分享文章,谢谢。 |