|
首先有个表: create table student( id char(1) primary key, name varchar(8), sex char(2) default '男' , age int(3) default 0 ) insert into student values ('1','王明','男',18); insert into student values ('2','孙丽','女',17); insert into student values ('3','王明','男',27); insert into student (id,sex,age) values ('4','男',27); 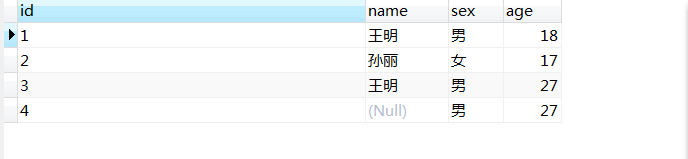 1、ORDER BY 对查询结果进行排序,必须置于SQL语句的最后。 语法:order by {column_name1, column_name2, column_name3, …column_namen} [asc|desc] 例: select * from student order by age;#按照age升序排列 select * from student order by age asc;#按照age升序排列 select * from student order by age desc;#按照age降序排列 order by之后可以跟多个字段,排序时首先按照第一个字段进行排序,若之间有相同数据在以第二个字段进行排序,之后以此类推直至排序完成。 order by 若不指定asc或者desc则默认升序排列。 2、group by group by用于将表中数据划分为若干个组,group by后面用于指定分组的依据 select sex,count(id) from student group by sex; #将student表学生按照sex分组,然后统计每组中的人数 执行结果:女生1人,男生3人 如果select语句中使用group by进行了分组,则select子句中只可以有聚集函数和分组字段,不能含有其他字段,否则SQL语句报错,并且如果group by子句后面跟着order by子句,则order by子句用于排序的字段也必须是聚集函数或分组字段; 3、having 因为where后面不能使用多行函数,只能使用单行函数和字段,having关键字弥补了这一不足:having子句用于对分组结果进行约束 select name from student group by name having count(name)>1#查询哪些名字重名了 执行结果:王明 4、distinct 表中,可能会包含重复值。这并不成问题,不过,有时也许希望仅仅列出不同(distinct)的值。 关键词 DISTINCT 用于返回唯一不同的值。 select distinct name from student; 执行结果:王明,孙丽 各个子句执行顺序 有如下代码: select sex,count(sex) total from student where name like '%' group by sex order by total 此处SQL语句执行过程为,首先筛选出符合where子句的数据,然后对这些数据以sex进行分组,最后将这些数据以count(sex)进行升序排序。 执行结果为: 女,1 男,2 各子句优先级为,where>group by >order by (责任编辑:IT) |