|
上次我们根据用户创建账号和登录日志进行了《用SQL进行用户留存率计算》,今天我们继续用这份用户登录日志来计算用户连续登录天数。
1. 数据预览
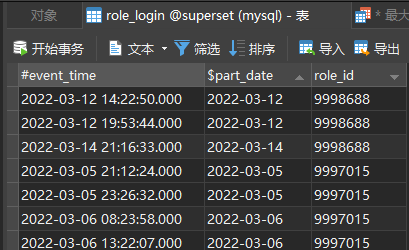
这里我们用到的是用户登录的日志,其中用户每天可能存在多次登录。
用户登录日志
用户登录
以上案例数据 后台回复 955 可以在SQL文件夹里data领取
2. 思路分析
其实,我们之前分享过几期类似的案例,大家感兴趣可以去看看。
《『数据分析』pandas计算连续行为天数的几种思路》
《利用Python统计连续登录N天或以上用户》
今天,我们用SQL来进行本次的操作,大致分为以下几步:
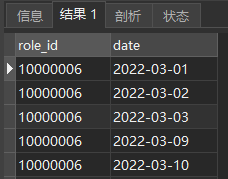
SELECT DISTINCT
role_id,
$part_date date
FROM
role_login
-
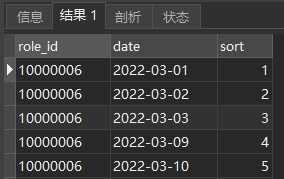
进行用户id分组并按照日期进行排序(获取排序序号,
窗口函数)
SELECT
role_id,
date,
row_number() OVER ( PARTITION BY role_id ORDER BY date ASC ) sort
FROM
( SELECT DISTINCT
role_id
, $part_date date
FROM
role_login ) temp_1
-
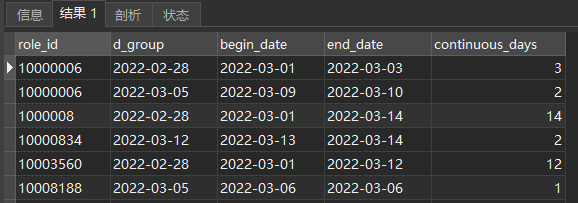
再用登录日期和排序序号进行差值计算(
DATE_SUB),并按照用id和差值进行分组计数(这就是用户的连续登录天数)
SELECT
role_id
, DATE_SUB(date,INTERVAL sort DAY) d_group
, min(date) begin_date
, max(date) end_date
, count(1) continuous_days
FROM
(
SELECT
role_id
, date
, row_number() OVER (PARTITION BY role_id ORDER BY date ASC) sort
FROM
(
SELECT DISTINCT
role_id
, $part_date date
FROM
role_login
) temp_1
) temp_2
GROUP BY role_id, DATE_SUB(date,INTERVAL sort DAY)
3. 完整代码
SELECT
role_id
, begin_date
, end_date
, continuous_days max_continuous_days
FROM
(
SELECT
*
, row_number() OVER (PARTITION BY role_id ORDER BY continuous_days DESC) sort_continuous_days
FROM
(
SELECT
role_id
, DATE_SUB(date,INTERVAL sort DAY) d_group
, min(date) begin_date
, max(date) end_date
, count(1) continuous_days
FROM
(
SELECT
role_id
, date
, row_number() OVER (PARTITION BY role_id ORDER BY date ASC) sort
FROM
(
SELECT DISTINCT
role_id
, $part_date date
FROM
role_login
) temp_1
) temp_2
GROUP BY role_id, DATE_SUB(date,INTERVAL sort DAY)
) temp_3
) temp_4
WHERE (sort_continuous_days = 1)
ORDER BY max_continuous_days DESC
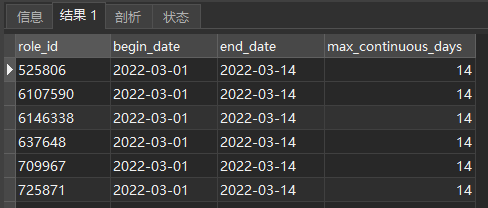
结果:
以上就是本次全部内容了。。
(责任编辑:IT) |