|
Ruby 2.2.0已于2014年12月25日发布,这是给Ruby开发者的圣诞礼物。该版本的亮点包括一些垃圾收集方面的改进:引入了一个新的增量式垃圾收集算法,支持对符号(Symbol)进行垃圾收集。核心类和标准库方面也有小幅改进。
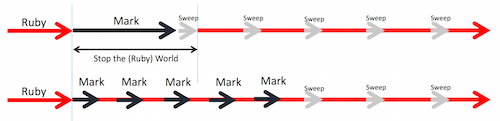
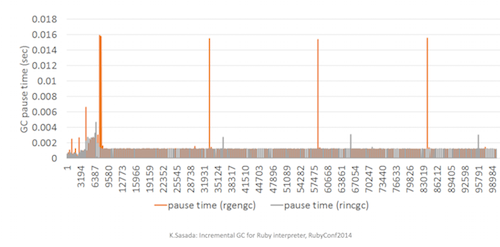
根据Ruby 2.1.0中分代垃圾收集(RGenGC)相关的说明,分代方式可以改进GC吞吐量。在新版本中,Ruby的维护者继续引入了重要的改进。大部分对象都会在很年轻的时候死掉,根据这个假设,分代垃圾收集将对象分为几个代。这个假设使得对较年轻对象的处理有较高的吞吐量和较低的延迟,因为较老的对象会在内存不足时才去计算是否要删除。不过也意味着,较老的对象仍然要承受高延迟之困。 增量式垃圾收集(RIncGC)是在分代垃圾收集的基础上构建的,致力于在维持同样吞吐量的前提下减少停顿时间。通过将标记阶段(把对象标记为可以进行垃圾收集)与Ruby的正常执行交错进行,较少了停顿时间。而在Ruby 2.2.0之前,标记阶段要占用很大的一步。 RGenGC和RIncGC都不能管理所有对象,意味着某些对象不会被提升到较老的一代。主要是因为C扩展,无法保证全部满足RGenGC和RIncGC的约束。在RubyConf 2014大会上, Koichi Sasada详细描述了RGenGC和RIncGC。如果想了解所有的算法细节和性能基准测试,这是很好的材料。
全局停顿GC与增量式GC之对比 来源:Koichi Sasada
RIncGC消除了长期停顿 来源:Koichi Sasada Ruby 2.2.0引入的对符号的垃圾收集,也改进了Ruby的内存管理。这个改进如此之大,乃至计划于2015年秋季发布的Ruby on Rails 5.0,将仅支持Ruby 2.2及以上的版本。
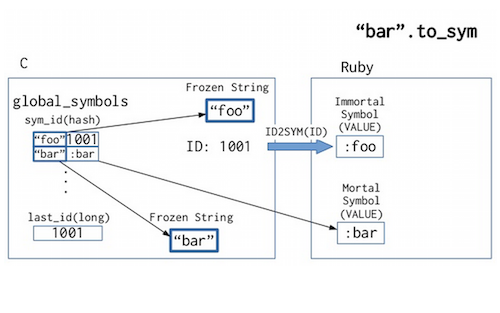
因为Ruby内部会将每个符号映射到一个整形数(integer),带来了一个问题。CRuby(用C实现的Ruby)将这个整形数用作符号的ID。如果一个符号在Ruby端释放了,之后又创建了同样的字符串,那会出现不同的CRuby整形数ID。这意味着,根据语言规范是同样的符号,但是出现了不同的ID,所以是个bug。 最简单的解决方案是用字符串替换CRuby中的整形数,这样在两端(C和Ruby)就一致了。另外,C扩展将问题变得更复杂了,因为它们会妨碍运行时探测和管理所有的符号。解决方案是将符号分成两组:永久的(immortal)和非永久的(mortal)。永久的符号会继续使用整形数ID,不会被回收。这类例子包括方法名、变量名、常量和其他语言元素。非永久的符号,比如"foo".to_sym,没有整形数ID,可以被回收。
非永久的符号与永久的符号之对比 来源:Narihiro Nakamura Narihiro Nakamura在RubyKaigi2014大会上描述了符号GC的解决方案,还介绍之所以使用这种方案的所有约束条件。 仍然是内存管理方面,Ruby 2.2.0还提供了一个选择,即使用jemalloc代替系统的malloc,此举有可能会提高速度,并减少内存碎片。这还是一个实验性特性,在收集到更多性能数据和使用案例后才会正式提供。 诸如system()和spawn()等创建进程的方法,在可能的情况下会使用vfork(2),代替了fork()。这种改变也会提高性能,尤其是当父进程会消耗大量内存时。这也是个实验性特性,未来可能会发生变化。 核心库现已支持Unicode 7.0,还引入了一些新方法,如Enumerable#slice_after、Enumerable#slice_when、Float#next_float、Float#prev_float、File.birthtime、File#birthtime和String#unicode_normalize。 Ruby 2.2.0废弃了mathn库,同时还更新了其他一些库:
更多细节,包括废弃的一些C API以及一些非兼容的改变,详见Ruby 2.2.0相关新闻。与Ruby 2.1.0相比,Ruby 2.2.0有1557处文件改动,包括125039条插入和74376条删除。 |