|
Paddle Lite v2.3发布了,新功能包括:
了解更多内容,查看PaddlePaddle官网。 支持“无校准数据的训练后量化”方法模型压缩高达75% 在手机等终端设备上部署深度学习模型,通常要兼顾推理速度和存储空间。一方面要求推理速度越快越好,另一方面要求模型更加的轻量化。为了解决这一问题,模型量化技术尤其关键。 模型量化是指使用较少比特数表示神经网络的权重和激活,能够大大降低模型的体积,解决终端设备存储空间有限的问题,同时加快了模型推理速度。将模型中特定OP权重从FP32类型量化成INT8/16类型,可以大幅减小模型体积。经验证,将权重量化为INT16类型,量化模型的体积降低50%;将权重量化为INT8类型,量化模型的体积降低75%。 Paddle Lite结合飞桨量化压缩工具PaddleSlim,为开发者提供了三种产出量化模型的方法:量化训练、有校准数据的训练后量化和无校准数据的训练后量化。 其中“无校准数据的训练后量化”是本次Paddle Lite新版本重要新增内容之一。
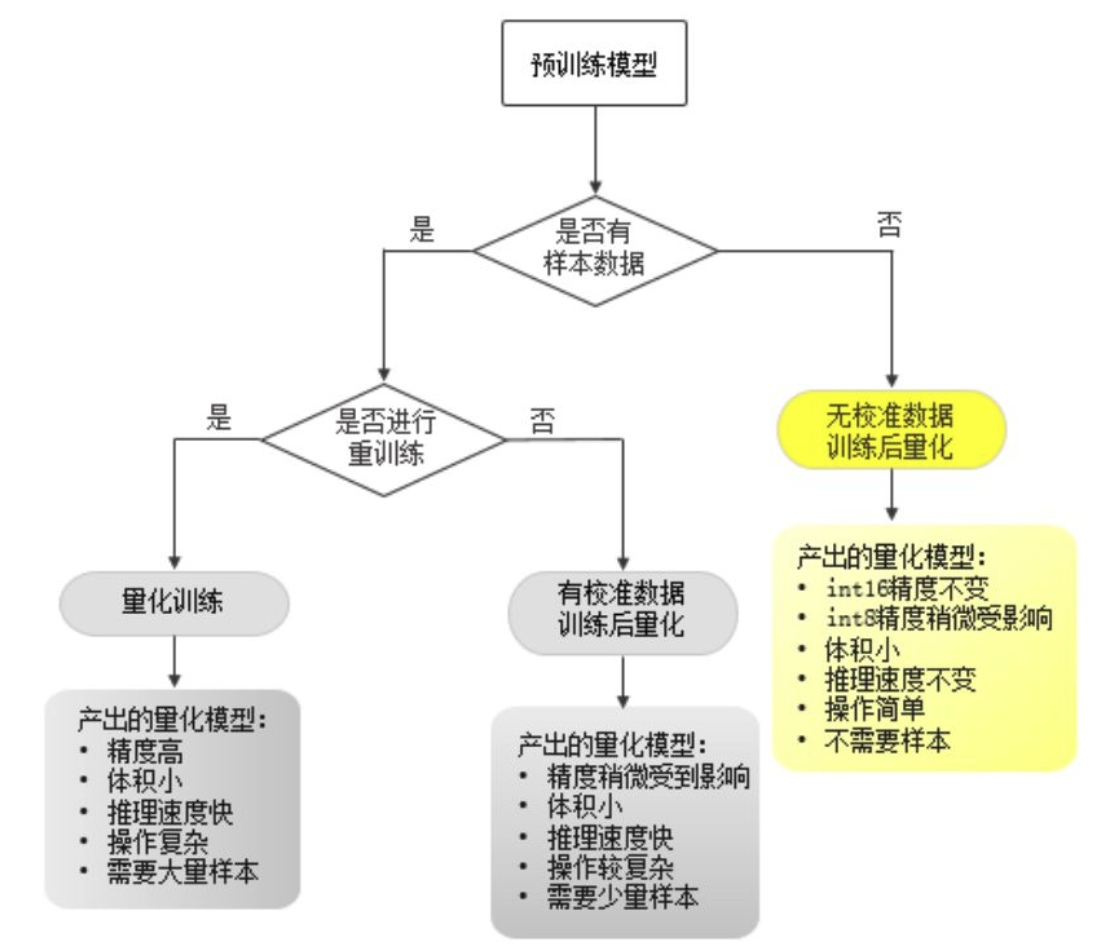
图1三种产出量化模型方法的处理示意图 “无校准数据的训练后量化”方法,在维持精度几乎不变的情况下,不需要样本数据,对于开发者来说使用更简便,应用范围也更广泛。 当然,如果希望同时减小模型体积和加快模型推理速度,开发者可以尝试采用PaddleSlim“有校准数据的训练后量化”方法和“量化训练”方法。 PaddleSlim除了量化功能以外,还集成了模型压缩中常用的剪裁、蒸馏、模型结构搜索、模型硬件搜索等方法。 下面以MoblieNetV1、MoblieNetv2和ResNet50模型为例,介绍本方法所获得的效果。
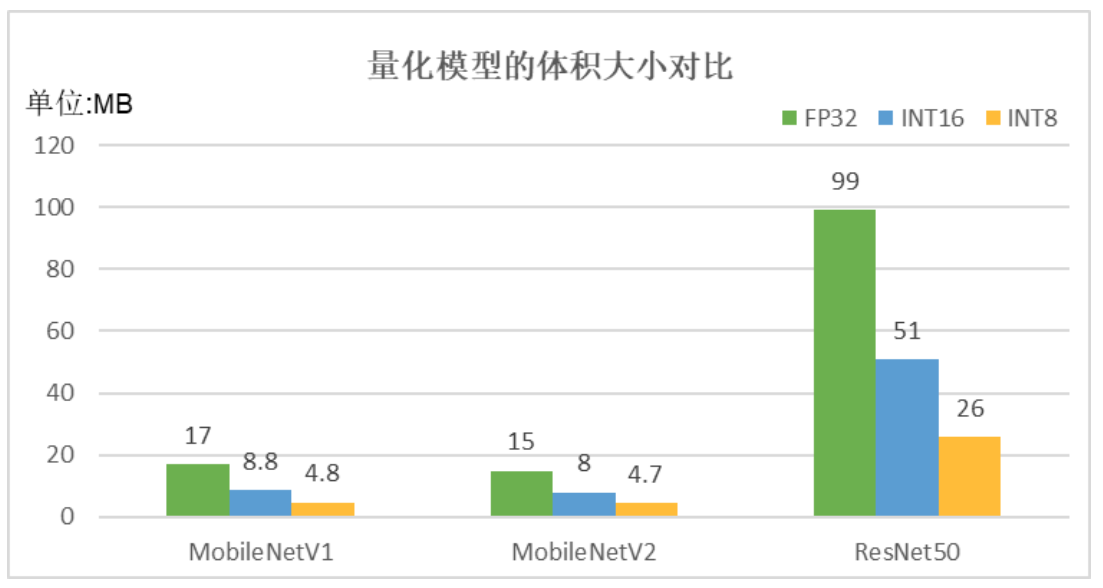
图2 “无校准数据的训练后量化”方法产出的量化模型体积对比图 由图2可知,INT16格式的量化模型,相比FP32,模型体积降低50%;INT8 格式的量化模型,相比FP32,模型体积降低75%。
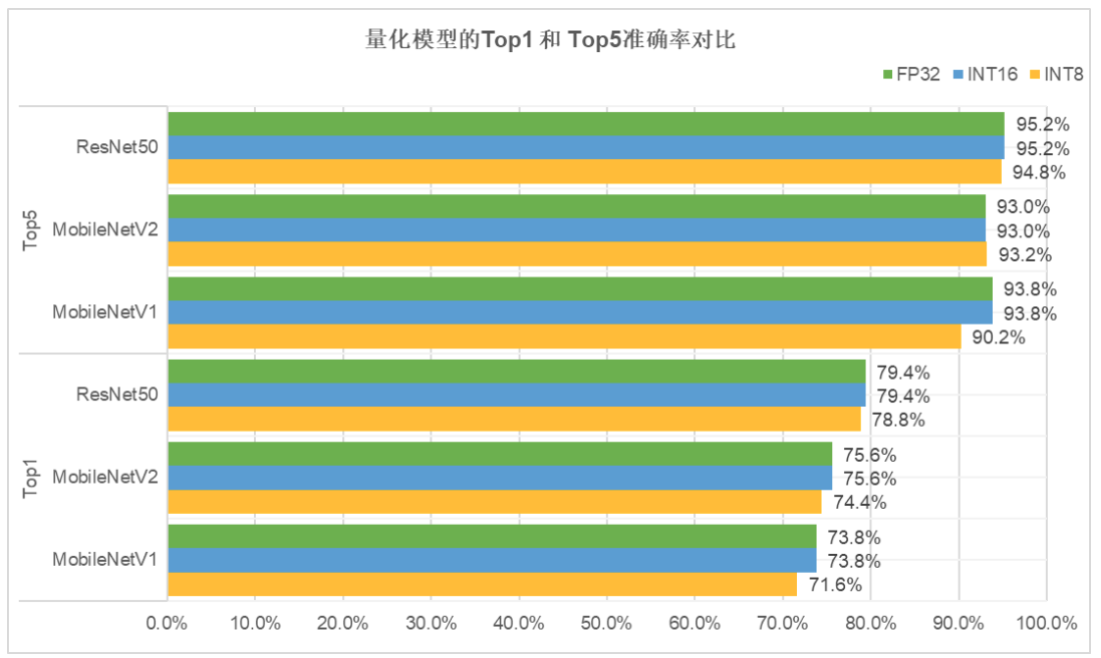
图3 “无校准数据的训练后量化”方法产出的量化模型准确率对比图 由图3可知,INT16格式的量化模型,相比FP32,准确率不变;INT8格式的量化模型,相比FP32,准确率仅微弱降低。 ARM CPU推理速度最高提升超20% Paddle Lite v2.3在ARM CPU性能优化方面的主要更新包括:
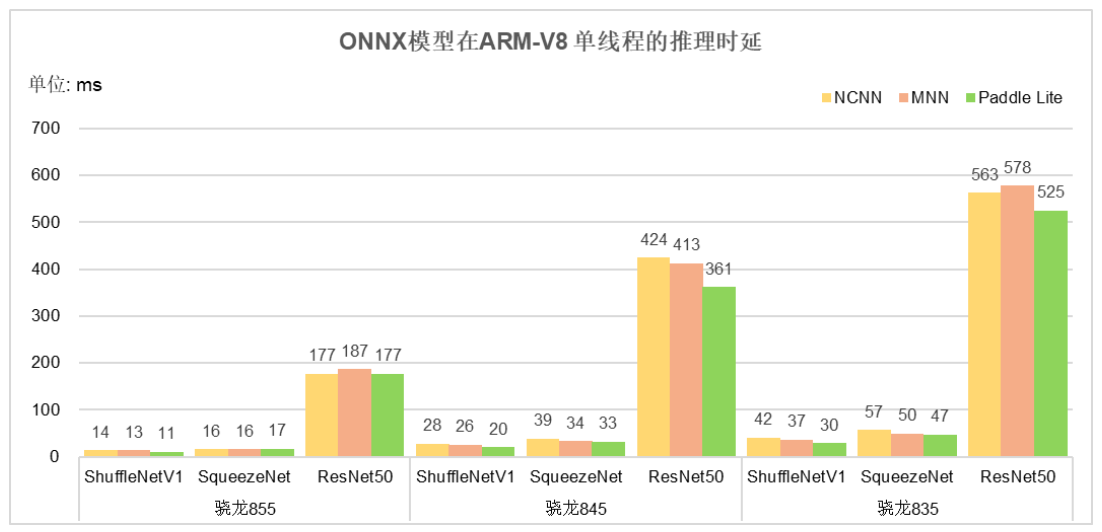
图4给出了Caffe框架的MobileNetV1、MobileNetV2 和ResNet50三个模型在Paddle Lite,NCNN和MNN框架上的推理时延对比图。
图4 Caffe框架模型的推理时延对比 由图4可知,Paddle Lite性能整体优于其他框架。如ResNet50模型,在高通骁龙845上,Paddle Lite相比其他框架,比MNN快10.259%,比NCNN快17.094%。 对于ONNX 公开模型如ShuffleNet、SqueezeNet和ResNet50, 在Paddle Lite、MNN和NCNN框架进行推理时延对比,其结果如图5所示。
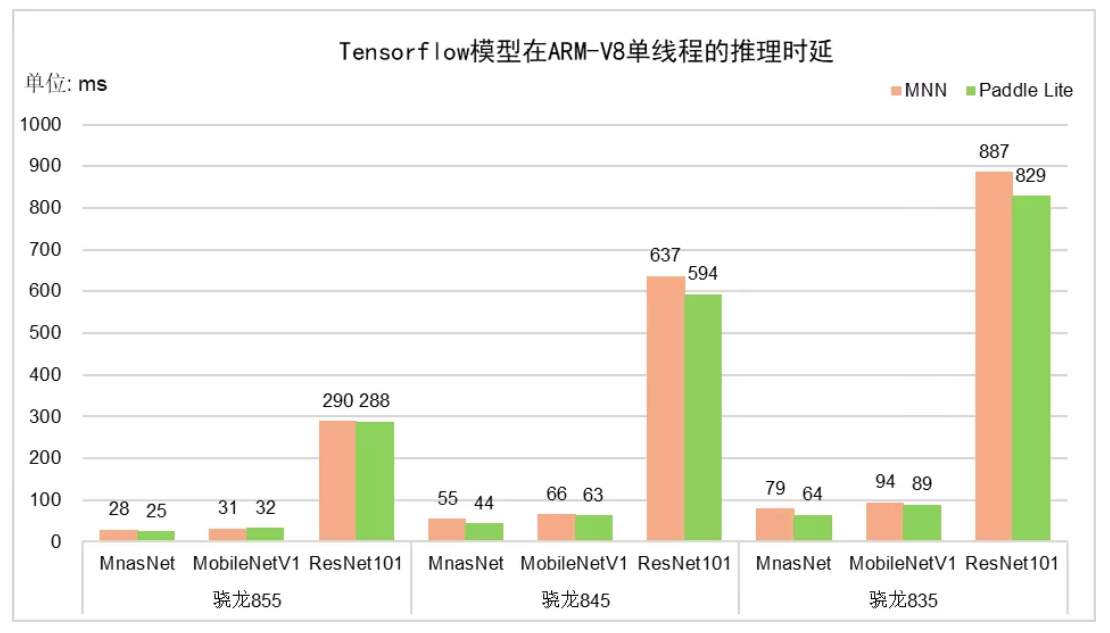
图5 ONNX框架模型的推理时延对比 由图5可知,Paddle Lite性能整体优于其他框架。如ShuffleNet模型,在高通骁龙845上,Paddle Lite相比其他框架,比MNN快21.185%,比NCNN快26.36%。 Tensorflow公开模型,比如MnasNet、 MobileNetV1和ResNet101,Paddle Lite与MNN推理框架在推理时延性能指标上进行对比,结果如图6所示。
图6 Tensorflow框架模型的推理时延对比 由图6可知,Paddle Lite性能整体优于MNN框架。如MnasNet模型,在高通骁龙855上,Paddle Lite比MNN快12.06%;在高通骁龙845上,Paddle Lite比MNN快18.91%;在高通骁龙835上,Paddle Lite比MNN快18.61%。 新版本更详细的性能数据,请参见GitHub的Benchmark: https://paddle-lite.readthedocs.io/zh/latest/benchmark/benchmark.html 简化模型优化工具操作流程,支持一键操作,用户上手更容易 对于第三方来源(Tensorflow、Caffe、ONNX)模型,一般需要经过两次转化才能获得Paddle Lite的优化模型。先使用x2paddle工具将第三方模型转化为PaddlePaddle格式,再使用模型优化工具转换为Padde Lite支持的模型。同时,转换后的Paddle Lite模型,通常包括模型结构和参数两个文件。操作繁琐,用户体验不太好。 针对上述问题,Paddle Lite v2.3对原模型优化工具model_optimize_tool 进行了升级,推出版模型优化工具——opt。opt包括以下三个亮点:
图7 日志信息 关于opt的更详细介绍,请参见GitHub的opt工具介绍与使用: https://paddle-lite.readthedocs.io/zh/latest/user_guides/model_optimize_tool.html 其他升级 1. 文档官网升级 为了提高文档可读性、改善文档的视觉效果、方便用户快速查找文档并轻松上手使用Paddle Lite,对Paddle Lite文档进行了全面升级。文档目录清晰可见,搜索功能更强大、为用户提供了更好的阅读体验。
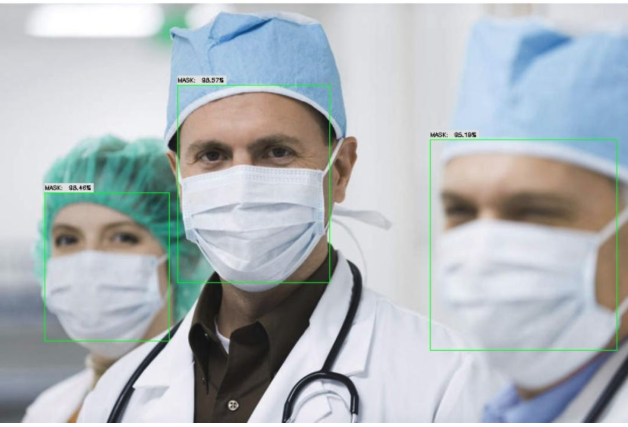
图8 新文档界面示意图 同时,Paddle Lite v2.3完善了部分文档内容,并新增一些使用文档,如“有校准数据的训练后量化方法”、“无校准数据的训练后量化方法”使用文档等。 2. Paddle Lite Demo仓库的案例升级 对现有Paddle Lite Demo仓库的案例进行了内容升级,并新增了Demo。例如在Android Demo中,新增人脸检测(face-detection)Demo、YOLOv3目标检测Demo和人像分割(Human-Segment)Demo。用户可以方便地根据Demo进行实验并参考实现新应用的开发。另外,在Paddle Lite仓库下的CXX Demo库,新增了口罩识别案例,为此次疫情做些力所能及的贡献。感兴趣的小伙伴们可以在Paddle Lite仓库下载口罩识别Demo,进行实验。
图9 口罩识别展示 同时,为了提高API接口易用性,升级了C++ API接口和Java API接口。在Java API接口,新增设置和返回数据类型,以支持不同类型的输入。 了解更多内容,查看PaddlePaddle官网、更新说明。 (责任编辑:IT) |