|
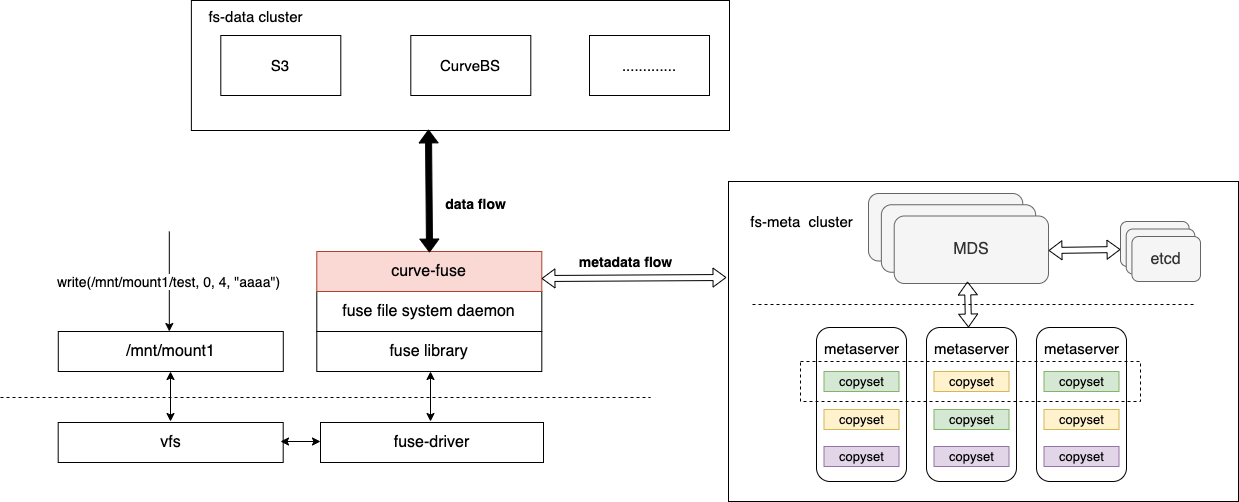
近日,Curve 开源存储社区发布了 CurveFS 的第一个 beta 版本,旨在解决 CephFS 在云原生场景下存在的一系列性能及功能问题,并提供了全新的部署工具 CurveAdm ,以简化用户对 Curve 集群的部署和管理。 Curve 是由网易数帆发起的一款开源存储系统,定位于高性能、易运维、支持广泛场景的开源云原生软件定义存储系统。项目包括 CurveFS 和 CurveBS,其中 CurveBS 此前已经开源。 CurveFS beta 版地址: https://github.com/opencurve/curve/releases/tag/v0.1.0-beta 架构设计CurveFS的架构如下图所示:
CurveFS由三个部分组成:
核心特性当前版本CurveFS主要具有如下特性:
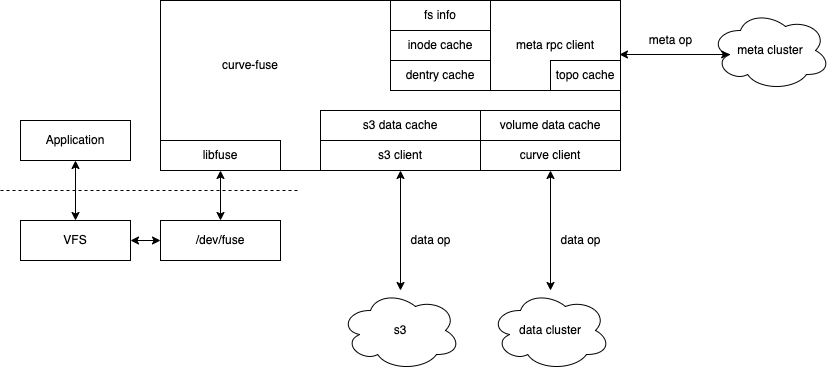
ClientCurveFS的client通过对接fuse,实现完整的文件系统功能,称之为curve-fuse。curve-fuse支持数据存储在两种后端,分别是S3兼容的对象存储和Curve块存储中(其他块存储的支持也在计划中),目前已支持S3存储后端,存储到CurveBS后端尚在完善中,后续还可能支持S3和Curve块混合存储,让数据根据冷热程度在S3与Curve块之间流动。curve-fuse的架构图如下:
curve-fuse架构图 curve-fuse包含几个主要模块:
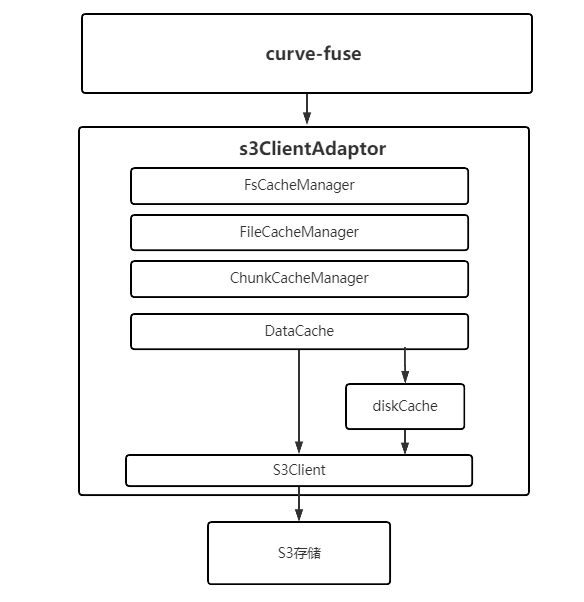
curve-fuse现已对接完整的fuse模块,基本实现POSIX的兼容,目前pjdtest测试通过率100%。 S3存储引擎支持 S3 client负责将文件的读写语义转换成S3存储的数据读写(upload,download)语义。考虑到S3存储性能较差,我们在这一层对数据做了级缓存:内存缓存(dataCache)和磁盘缓存(diskCache),整体架构如下:
S3ClientAdaptor主要包含以下几个模块:
MDSMDS是指元数据管理服务,CurveFS的MDS类似于CurveBS的MDS(CurveBS的MDS介绍:https://zhuanlan.zhihu.com/p/333878236),提供中心化的元数据管理服务。 CurveFS的MDS有以下功能:
作为一个中心化的元数据管理服务,其性能、可靠性、可用性也十分重要。
MetaServerMetaServer是分布式元数据管理系统,为客户端提供元数据服务。文件系统元数据进行分片管理,每个元数据分片以三副本的形式提供一致性保证,三个副本统称为Copyset,内部采用Raft一致性协议。同时,一个Copyset可以管理多个元数据分片。所以,整个文件系统的元数据管理如下所示:
图中共有两个Copyset,三个副本放置在三台机器上。P1/P2/P3/P4表示文件系统的元数据分片,其中P1/P3属于一个文件系统,P2/P4属于一个文件系统。 元数据管理 文件系统的元数据进行分片管理,每个分片称为Partition,Partition提供了对dentry和inode的增删改查接口,同时Partition管理的元数据全部缓存在内存中。 Inode对应文件系统中的一个文件或目录,记录相应的元数据信息,比如atime/ctime/mtime。当inode表示一个文件时,还会记录文件的数据寻址信息。每个Parition管理固定范围内的inode,根据inodeid进行划分,比如inodeid [1-200] 由Partition 1管理,inodeid [201-400] 由Partition 2管理,依次类推。 Dentry是文件系统中的目录项,记录文件名到inode的映射关系。一个父目录下所有文件/目录的dentry信息由父目录inode所在的Partition进行管理。 一致性 文件系统元数据分片以三副本形式存储,利用raft算法保证三副本数据的一致性,客户端的元数据请求都由raft leader进行处理。在具体实现层面,我们使用了开源的braft(https://github.com/baidu/braft),并且一台server上可以放置多个复制组,即multi-raft。 高可靠 高可用的保证主要来自两个方面。首先,raft算法保证了数据的一致性,同时raft心跳机制也可以做到在raft leader异常的情况下,复制组内的其余副本可以快速竞选leader,并对外提供服务。 其次,Raft基于Quorum的一致性协议,在三副本的情况下,只需要两副本存活即可 。但是长时间的两副本运行,对可用性也是一个考验。所以,我们在Metaserver与MDS之间加入了定时心跳,Metaserver会定期向MDS发送自身的统计信息,比如:内存使用率,磁盘容量,复制组信息等。当某个Metaserver进程退出后,复制组信息不再上报给MDS,此时MDS会发现一些复制组只有两副本存活,因此会通过心跳下发Raft配置变更请求,尝试将复制组恢复到正常三副本的状态。 CurveAdm此外,为了提升 Curve 的运维便利性,Curve 社区设计开发了 CurveAdm 项目,其主要用于部署和管理 Curve 集群,目前已支持部署 CurveFS(CurveBS 的支持正在开发中)。 与之前的 Ansible 部署工具相比较,CurveAdm 带来了如下优势:
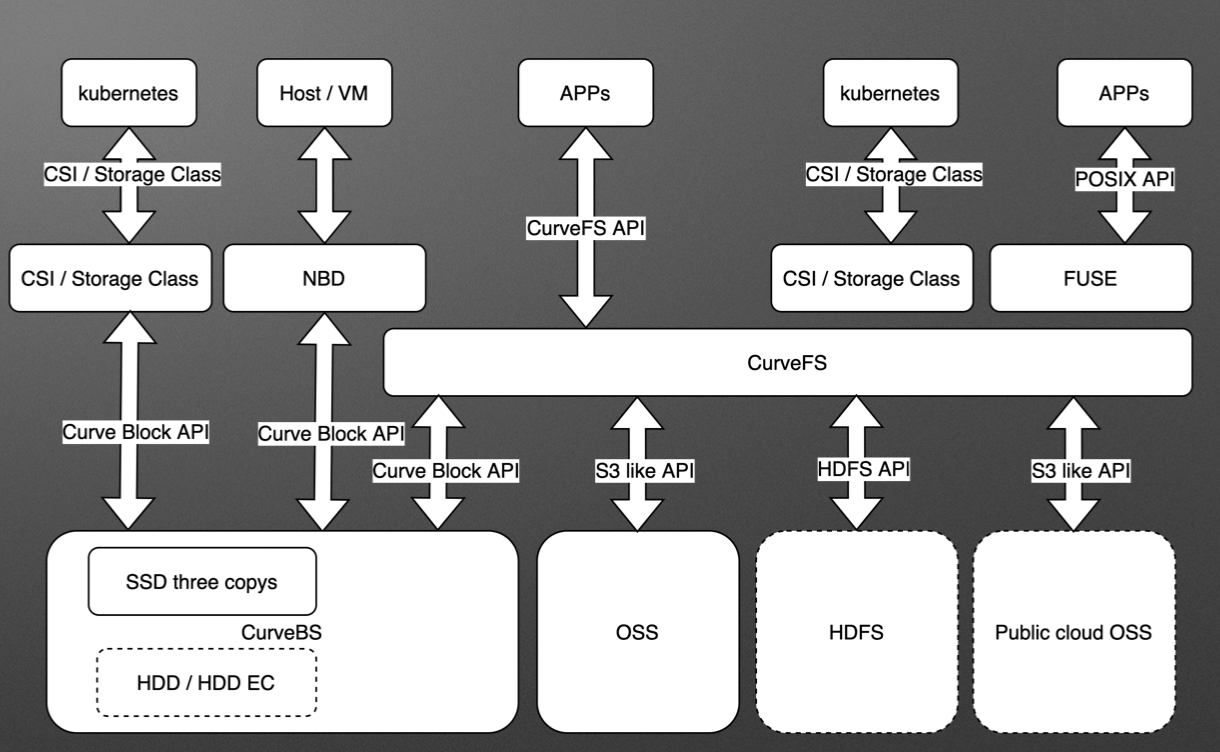
当前版本是CurveFS的第一个beta版本,不建议在生产环境使用,但读者可以抢先体验,并在GitHub上提交issue和bug,或者添加微信号opencurve邀请您入群交流。 未来规划按照 Curve 社区的规划,Curve 将作为多种存储系统(如 HDFS、S3 兼容对象存储等)的统一存储层,接管并加速各系统访问。后续将支持接管多种存储系统,并进行统一的cache加速。
CurveFS 下个大版本的主要开发目标为(可能会根据实际需求进行部分调整):
(责任编辑:IT) |