|
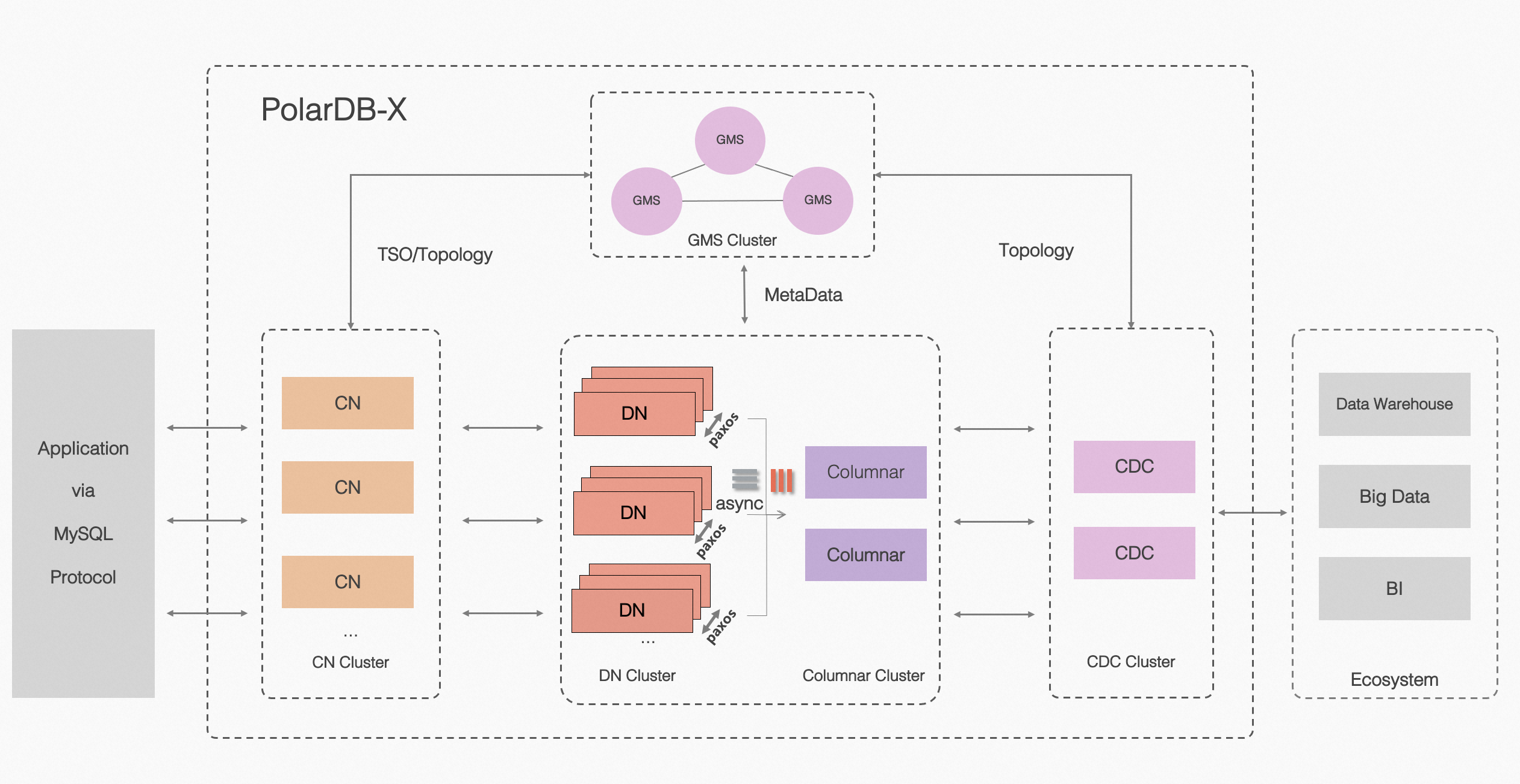
PolarDB 分布式版 (PolarDB for Xscale,以下简称 “PolarDB-X”) 是阿里云自主设计研发的高性能云原生分布式数据库产品,为用户提供高吞吐、大存储、低延时、易扩展和超高可用的云时代数据库服务。 架构简介PolarDB-X 采用 Shared-nothing 与存储分离计算架构进行设计,系统由 5 个核心组件组成。
PolarDB 分布式 架构图
开源地址:https://github.com/polardb/polardbx-sql 版本说明梳理下 PolarDB-X 开源脉络:
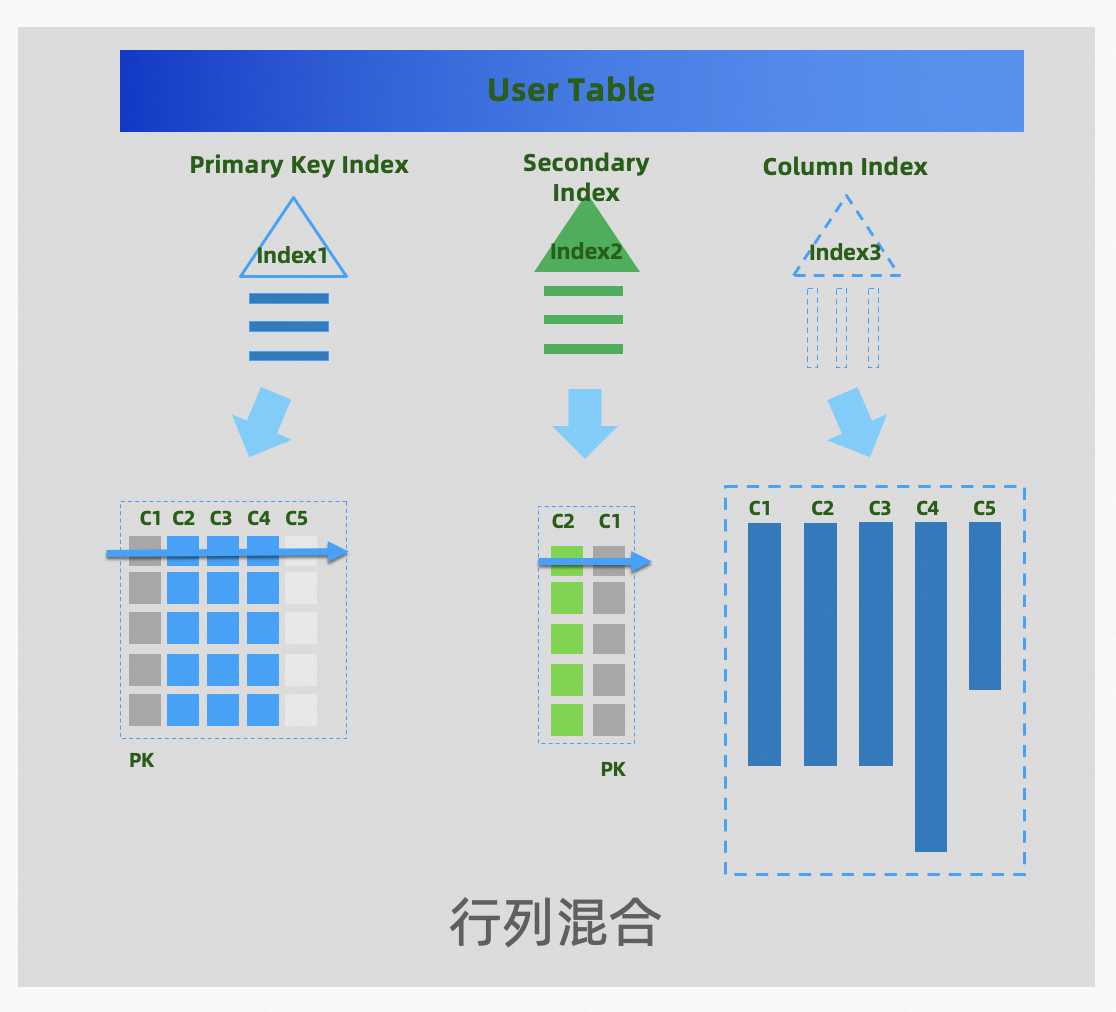
2024 年 4 月份,PolarDB-X 正式发布 2.4.0 版本,重点推出列存节点 Columnar,可以提供持久化列存索引(Clustered Columnar Index,CCI)。PolarDB-X 的行存表默认有主键索引和二级索引,列存索引是一份额外基于列式结构的二级索引(默认覆盖行存所有列),一张表可以同时具备行存和列存的数据,结合计算节点 CN 的向量化计算,可以满足分布式下的查询加速的诉求,实现 HTAP 一体化的体验和效果。 01 列存索引随着云原生技术的不断普及,以 Snowflake 为代表的新一代云原生数仓、以及数据库 HTAP 架构不断创新,可见在未来一段时间后行列混存 HTAP 会成为一个数据库的标配能力,需要在当前数据库列存设计中面相未来的低成本、易用性、高性能上有更多的思考 PolarDB-X 在 V2.4 版本正式发布列存引擎,提供列存索引的形态(Clustered Columnar Index,CCI),行存表默认有主键索引和二级索引,列存索引是一份额外基于列式结构的二级索引(覆盖行存所有列),一张表可以同时具备行存和列存的数据。
PolarDB-X 列存索引 相关语法索引创建的语法:
列存索引创建的 DDL 语法
实际例子: # 先创建表 CREATE TABLE t_order ( `id` bigint(11) NOT NULL AUTO_INCREMENT, `order_id` varchar(20) DEFAULT NULL, `buyer_id` varchar(20) DEFAULT NULL, `seller_id` varchar(20) DEFAULT NULL, `order_snapshot` longtext DEFAULT NULL, `order_detail` longtext DEFAULT NULL, PRIMARY KEY (`id`), KEY `l_i_order` (`order_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 partition by hash(`order_id`) partitions 16; # 再创建列存索引 CREATE CLUSTERED COLUMNAR INDEX `cc_i_seller` ON t_order (`seller_id`) partition by hash(`order_id`) partitions 16;
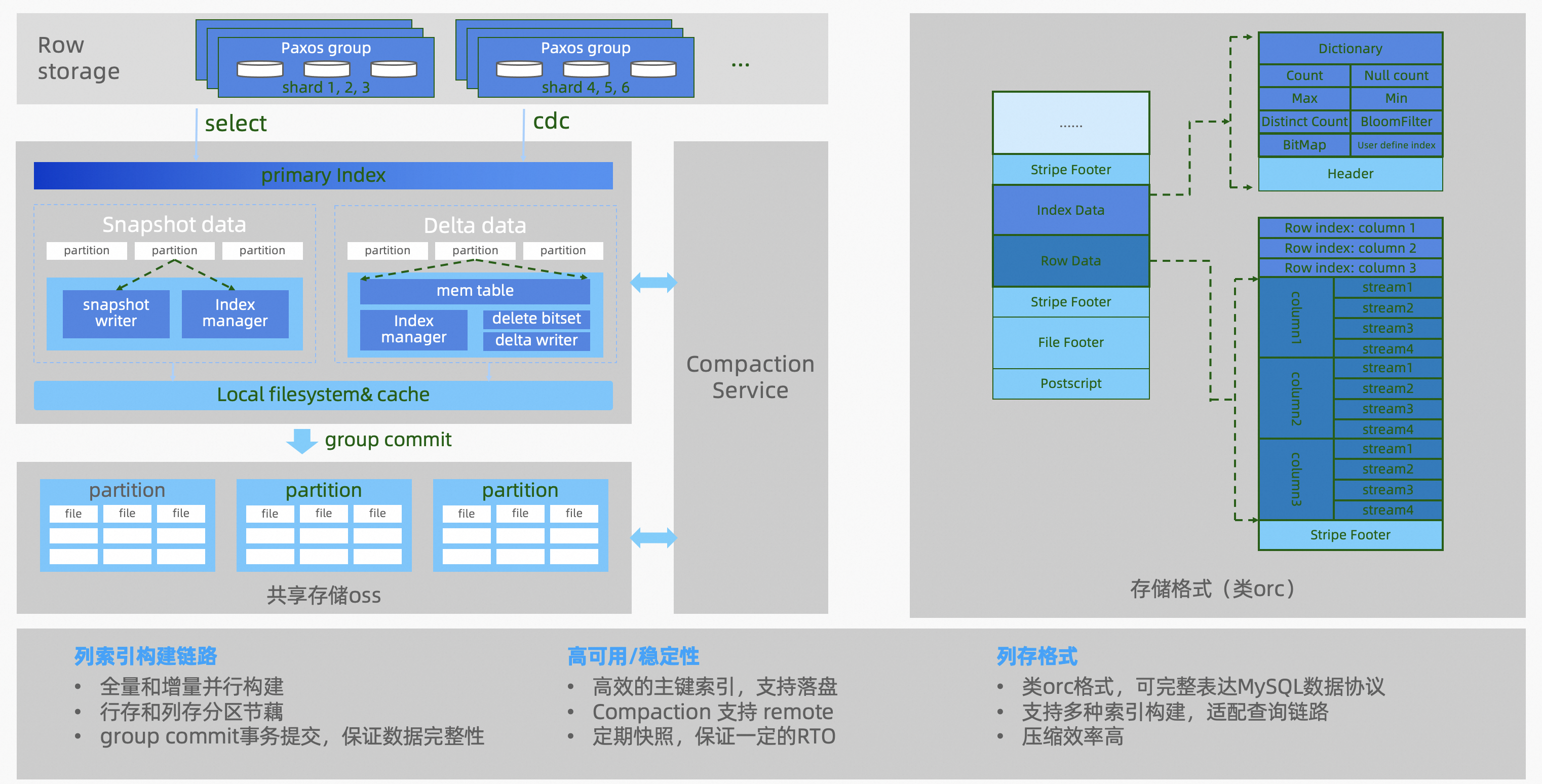
原理简介列存索引的数据结构:
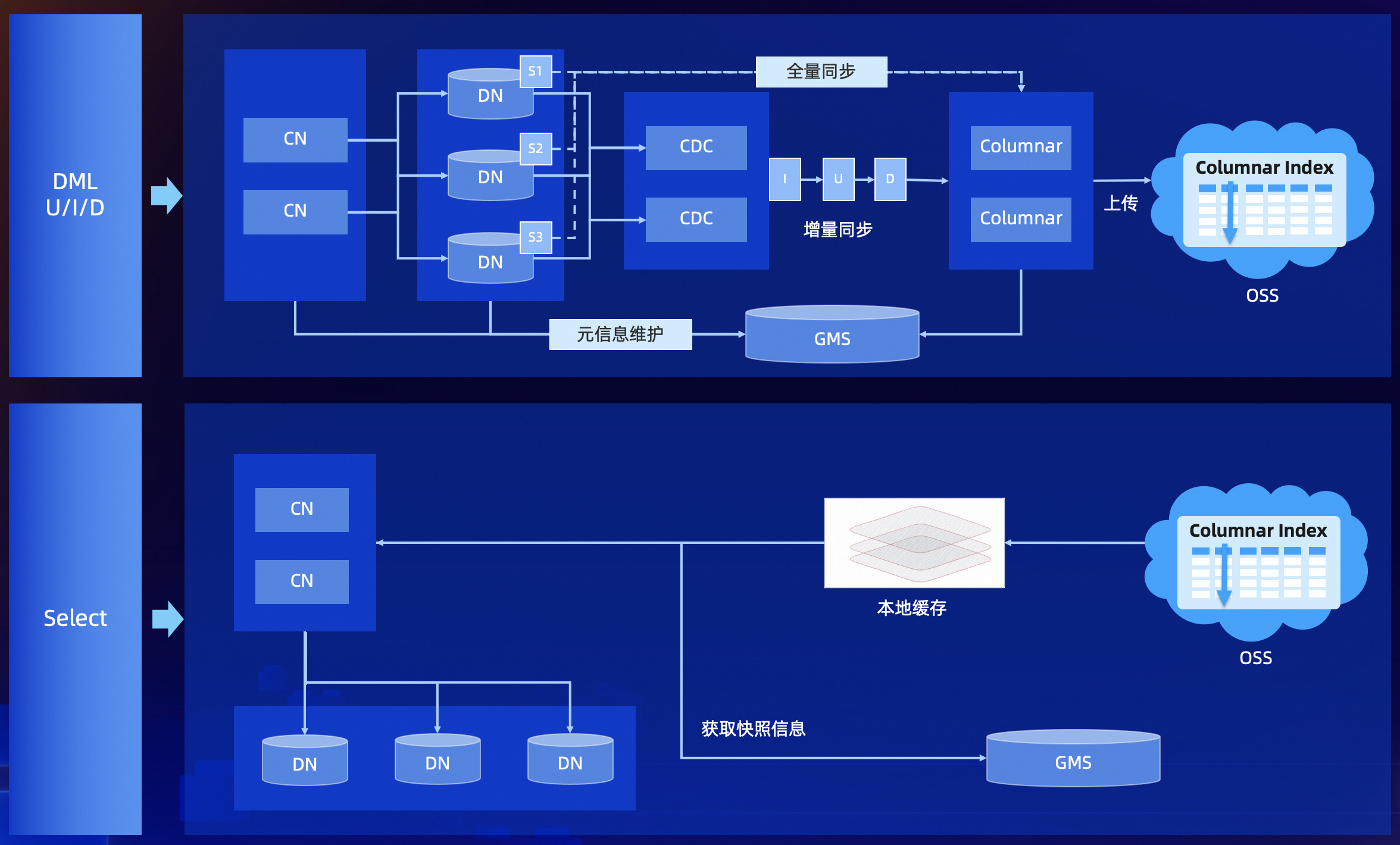
列存数据结构 列存索引是由列存引擎(Columnar)节点来构造的,数据结构基于 Delta+Main (类 LSM 结构) 二层模型,实时更新采用了标记删除的技术 (update 转化为 delete 标记 + insert),确保了行存和列存之间实现低延时的数据同步,可以保证秒级的实时更新。数据实时写入到 MemTable,在一个 group commit 的周期内,会将数据存储到一个本地 csv 文件,并追加到 OSS 上对应 csv 文件的尾部,这个文件称为 delta 文件。OSS 对象存储上的.csv 文件不会长期存在,而是由 compaction 线程不定期地转换成.orc 文件。 列存索引的数据流转:
数据流转 列存索引,构建流程:
列存索引,查询流程:
tips. 更多列存引擎相关的技术原理文章,后续会逐步发布,欢迎大家持续关注。 性能体验测试集:TPC-H 100GB 硬件环境:
按照正常导入 TPC-H 100GB 数据后,执行 SQL 创建列存索引: create clustered columnar index `nation_col_index` on nation(`n_nationkey`) partition by hash(`n_nationkey`) partitions 1; create clustered columnar index `region_col_index` on region(`r_regionkey`) partition by hash(`r_regionkey`) partitions 1; create clustered columnar index `customer_col_index` on customer(`c_custkey`) partition by hash(`c_custkey`) partitions 96; create clustered columnar index `part_col_index` on part(`p_size`) partition by hash(`p_partkey`) partitions 96; create clustered columnar index `partsupp_col_index` on partsupp(`ps_partkey`) partition by hash(`ps_partkey`) partitions 96; create clustered columnar index `supplier_col_index` on supplier(`s_suppkey`) partition by hash(`s_suppkey`) partitions 96; create clustered columnar index `orders_col_index` on orders(`o_orderdate`,`o_orderkey`) partition by hash(`o_orderkey`) partitions 96; create clustered columnar index `lineitem_col_index` on lineitem(`l_shipdate`,`l_orderkey`) partition by hash(`l_orderkey`) partitions 96; 场景 1:单表聚合场景 (count 、 groupby)
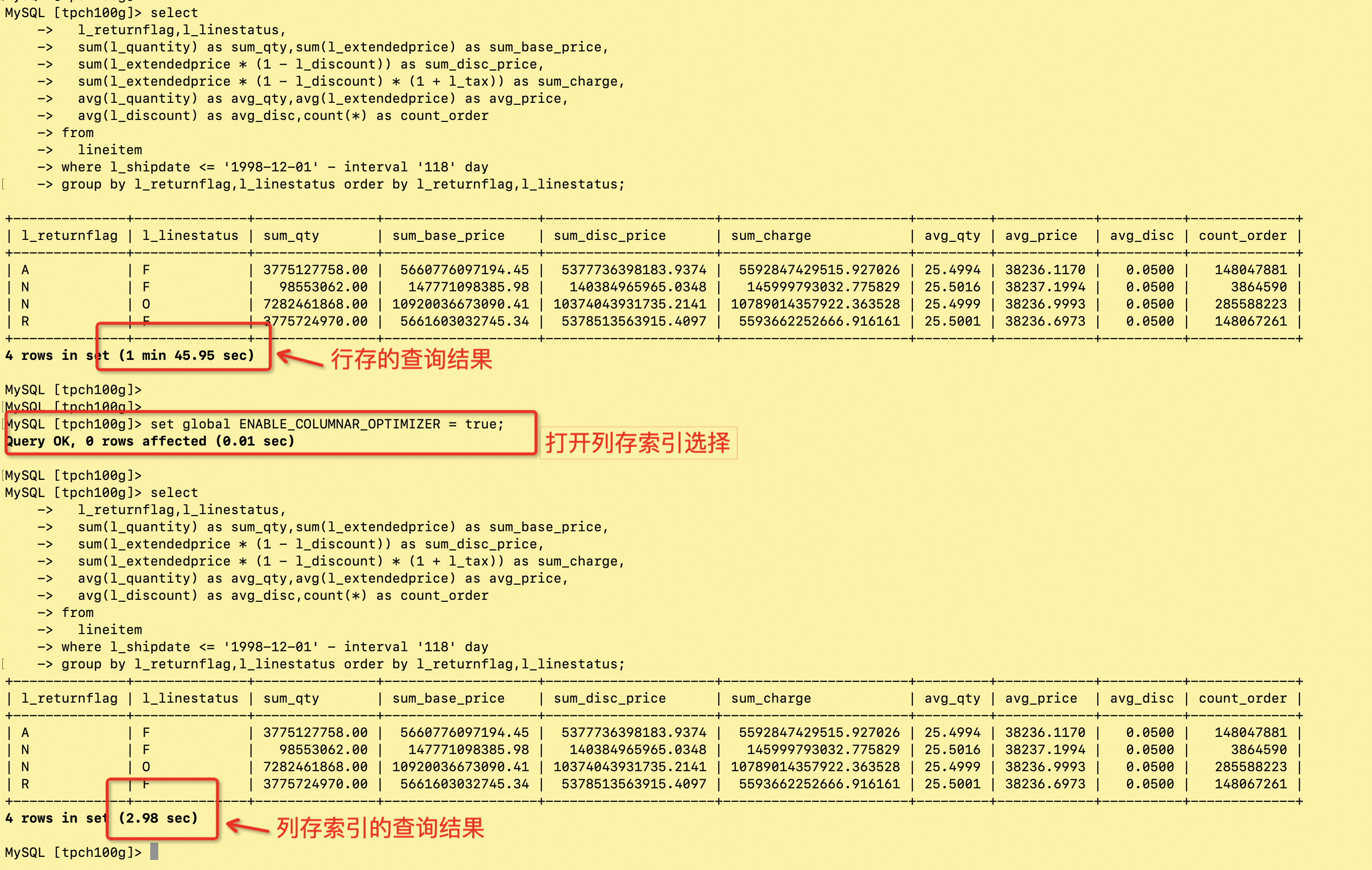
tpch-Q1 的行存和列存的效果对比图:
tpch-Q1 select count 的行存和列存的效果对比图:
count 查询 场景 2:TPC-H 22 条 query 基于列存索引的性能白皮书,开源版本可以参考:TPC-H 测试报告 TPC-H 100GB,22 条 query 总计 25.76 秒 详细数据如下:
02 兼容 MySQL 8.0.32PolarDB-X V2.3 版本,推出了集中式和分布式一体化架构(简称集分一体),在 2023 年 10 月公共云和开源同时新增集中式形态,将分布式中的 DN 多副本单独提供服务,支持 Paxos 多副本、lizard 分布式事务引擎,可以 100% 兼容 MySQL。 所谓集分一体化,就是兼具分布式数据库的扩展性和集中式数据库的功能和单机性能,两种形态可以无缝切换。在集分一体化数据库中,数据节点被独立出来作为集中式形态,完全兼容单机数据库形态。当业务增长到需要分布式扩展的时候,架构会原地升级成分布式形态,分布式组件无缝对接到原有的数据节点上进行扩展,不需要数据迁移,也不需要应用侧做改造。 回顾下 MySQL 8.0 的官方开源,8.0.11 版本在 2018 年正式 GA,历经 5 年左右的不断演进,修复和优化了众多稳定性和安全相关的问题,2023 年后的 8.0.3x 版本后逐步进入稳态。 PolarDB-X 在 V2.4 版本,跟进 MySQL 8.0 的官方演进,分布式的 DN 多副本中全面兼容 MySQL 8.0.32,快速继承了官方 MySQL 的众多代码优化:
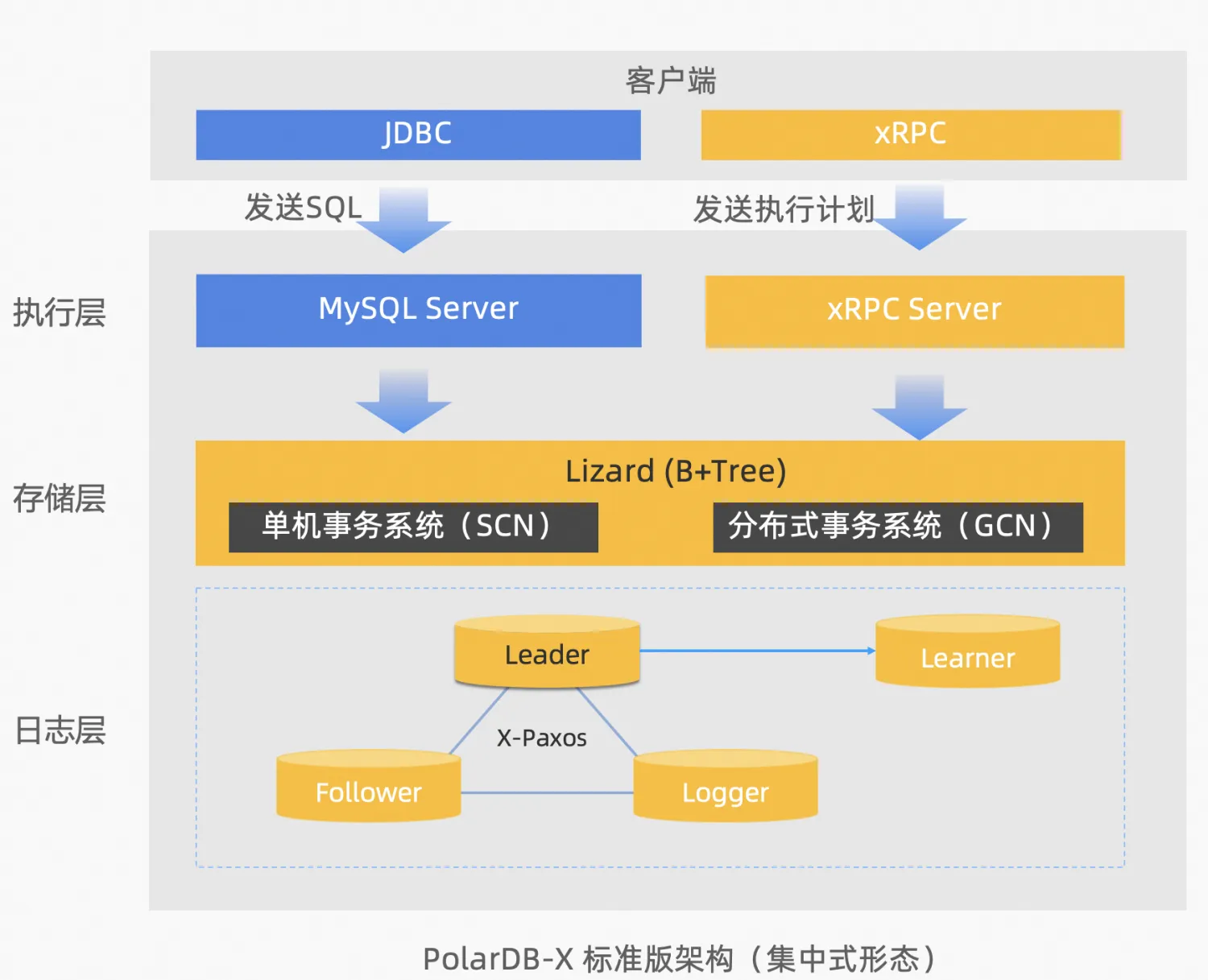
标准版架构
PolarDB-X 标准版,采用分层架构:
性能体验硬件环境:
TPCC 场景:对比开源 MySQL(采用相同的主机硬件部署)
03 全球数据库 GDN数据库容灾架构设计是确保企业关键数据安全和业务连续性的核心。随着数据成为企业运营的命脉,任何数据丢失或服务中断都可能导致重大的财务损失。在规划容灾架构时,企业需要考虑数据的恢复时间目标(RTO)和数据恢复点目标(RPO),以及相关的成本和技术实现的复杂性。 03 全球数据库 GDN数据库容灾架构设计是确保企业关键数据安全和业务连续性的核心。随着数据成为企业运营的命脉,任何数据丢失或服务中断都可能导致重大的财务损失。在规划容灾架构时,企业需要考虑数据的恢复时间目标(RTO)和数据恢复点目标(RPO),以及相关的成本和技术实现的复杂性。 常见容灾架构异地多活,主要指跨地域的容灾能力,可以同时在多地域提供读写能力。金融行业下典型的两地三中心架构,更多的是提供异地容灾,日常情况下异地并不会直接提供写流量。但随着数字化形式的发展,越来越多的行业都面临着容灾需求。比如,运营商、互联网、游戏等行业,都对异地多活的容灾架构有比较强的诉求。 目前数据库业界常见的容灾架构:
总结一下容灾架构的优劣势:
PolarDB-X 的容灾能力PolarDB-X 采用数据多副本架构(比如 3 副本、5 副本),为了保证副本间的强一致性(RPO=0),采用 Paxos 的多数派复制协议,每次写入都要获得超过半数节点的确认,即便其中 1 个节点宕机,集群也仍然能正常提供服务。Paxos 算法能够保证副本间的强一致性,彻底解决副本不一致问题。 PolarDB-X V2.4 版本以前,主要提供的容灾形态:
阿里集团的淘宝电商业务,在 2017 年左右开始建设异地多活的架构,构建了三地多中心的多活能力,因此在 PolarDB-X V2.4 我们推出了异地多活的容灾架构,我们称之为全球数据库(Global Database Network,简称 GDN)。 PolarDB-X GDN 是由分布在同一个国家内多个地域的多个 PolarDB-X 集群组成的网络,类似于传统 MySQL 跨地域的容灾(比如,两个地域的数据库采用单向复制、双向复制 , 或者多个地域组成一个中心 + 单元的双向复制等)。 常见的业务场景:
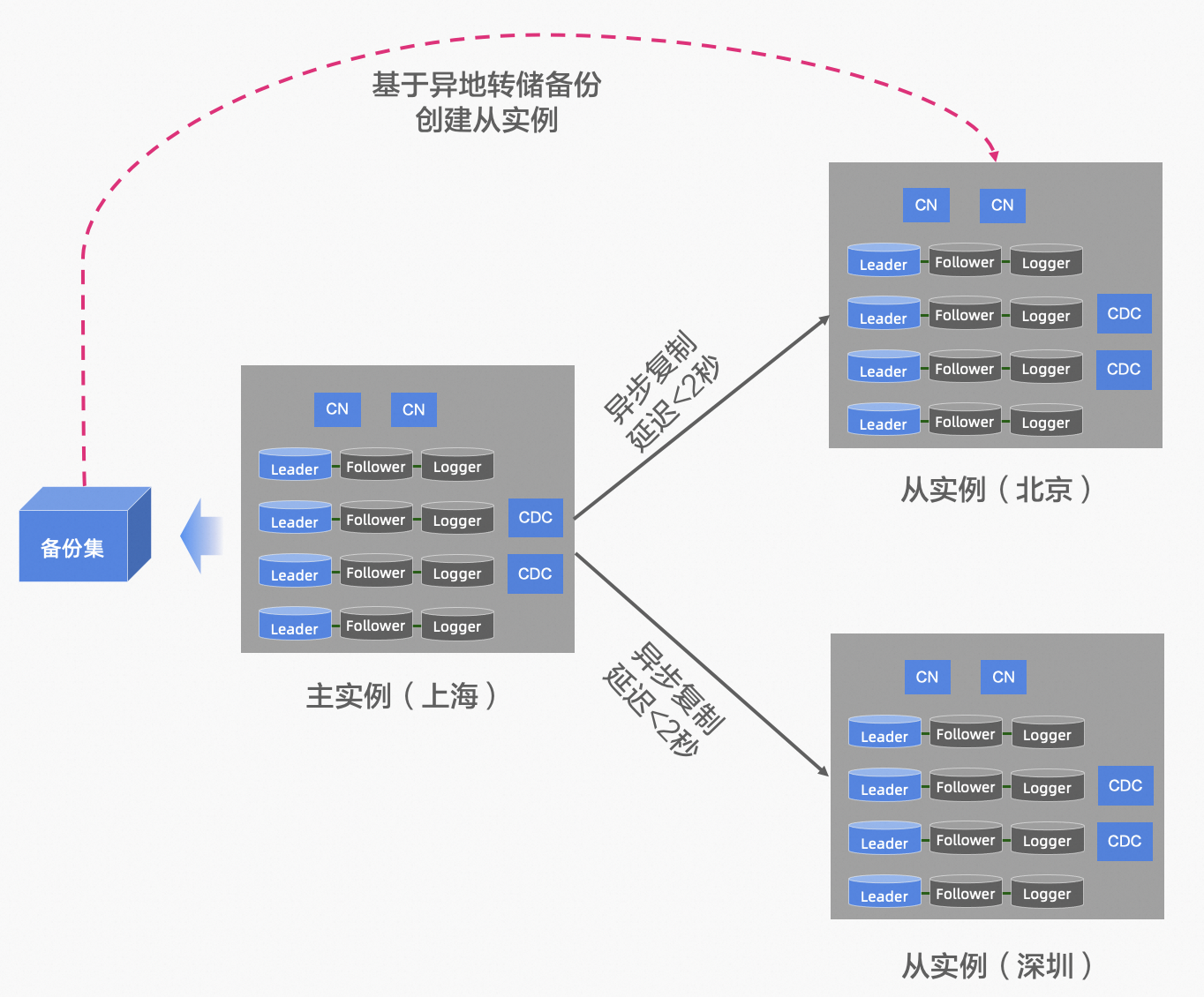
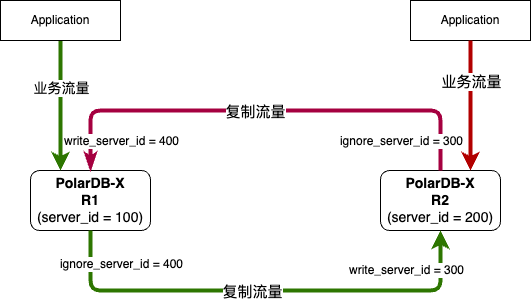
异地容灾 业务默认的流量,读写都集中在中心的主实例,异地的从实例作为灾备节点,提供就近读的服务能力 PolarDB-X 主实例 和 从实例,采用双向复制的能力,复制延迟小于 2 秒,通过备份集的异地备份可以快速创建一个异地从实例。 当 PolarDB-X 中心的主实例出现地域级别的故障时,可以手动进行容灾切换,将读写流量切换到从实例 2. 基于 GDN 的异地多活
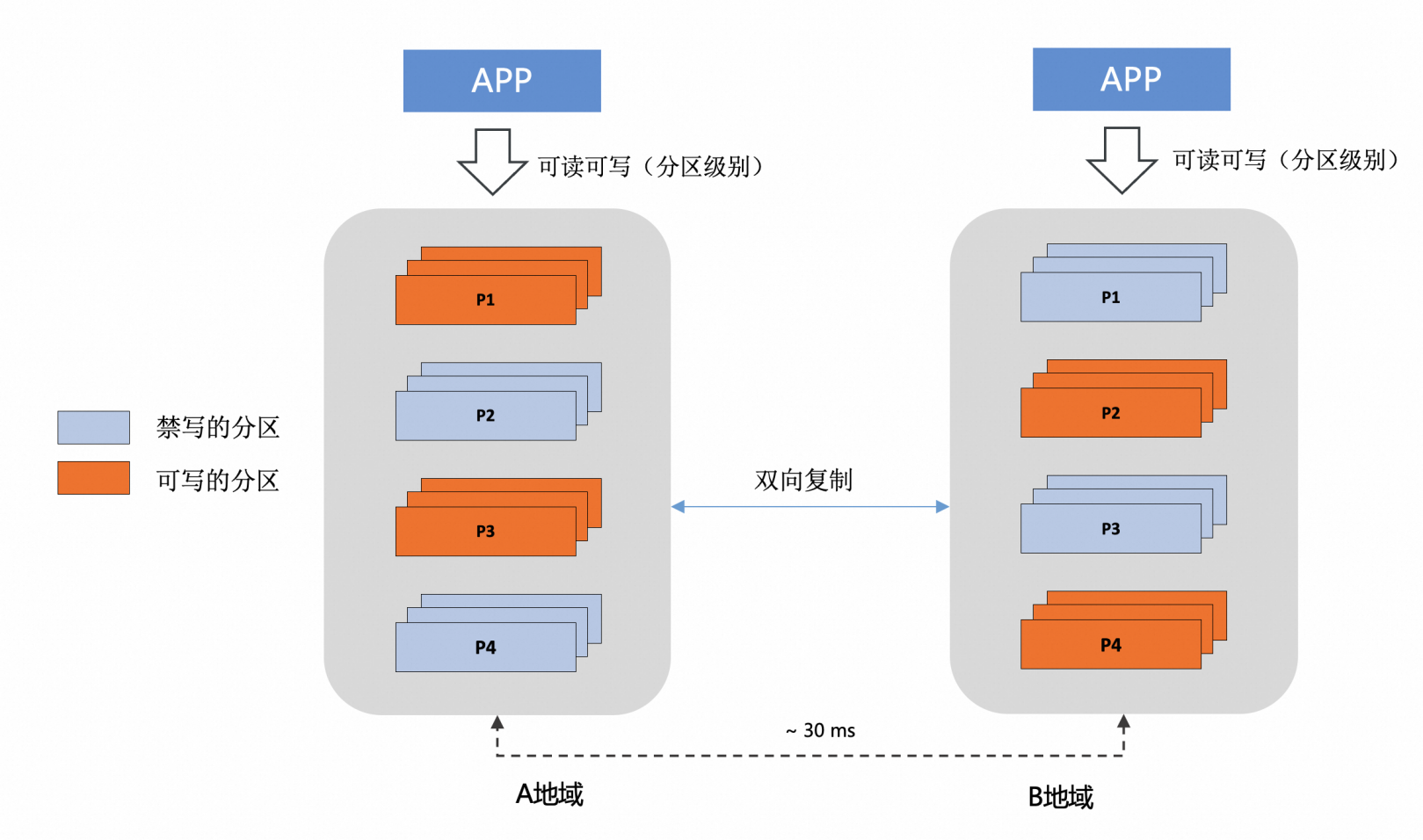
异地多活 业务适配单元化分片,按照数据分片的粒度的就近读和写,此时主实例和从实例,均承担读写流量 PolarDB-X 主实例 和 从实例,采用双向复制的能力,复制延迟小于 2 秒 当 PolarDB-X 中心的主实例出现地域级别的故障时,可以手动进行容灾切换,将读写流量切换到从实例 使用体验PolarDB-X V2.4 版本,暂时仅提供基于 GDN 的异地容灾,支持跨地域的主备复制能力(异地多活形态会在后续版本中发布)。GDN 是一个产品形态,其基础和本质是数据复制,PolarDB-X 提供了高度兼容 MySQL Replica 的 SQL 命令来管理 GDN,简单来说,会配置 MySQL 主从同步,就能快速的配置 PolarDB-X GDN。 1. 可以使用兼容 MySQL 的 CHANGE MASTER 命令,搭建 GDN 复制链路
CHANGE MASTER TO option [, option] ... [ channel_option ]
option: {
MASTER_HOST = 'host_name'
| MASTER_USER = 'user_name'
| MASTER_PASSWORD = 'password'
| MASTER_PORT = port_num
| MASTER_LOG_FILE = 'source_log_name'
| MASTER_LOG_POS = source_log_pos
| MASTER_LOG_TIME_SECOND = source_log_time
| SOURCE_HOST_TYPE = {RDS|POLARDBX|MYSQL}
| STREAM_GROUP = 'stream_group_name'
| WRITE_SERVER_ID = write_server_id
| TRIGGER_AUTO_POSITION = {FALSE|TRUE}
| WRITE_TYPE = {SPLIT|SERIAL|TRANSACTION}
| MODE = {INCREMENTAL|IMAGE}
| CONFLICT_STRATEGY = {OVERWRITE|INTERRUPT|IGNORE|DIRECT_OVERWRITE}
| IGNORE_SERVER_IDS = (server_id_list)
}
channel_option:
FOR CHANNEL channel
server_id_list:
[server_id [, server_id] ... ]
2. 可以使用兼容 MySQL 的 SHOW SLAVE STATUS 命令,监控 GDN 复制链路
SHOW SLAVE STATUS [ channel_option ]
channel_option:
FOR CHANNEL channel
3. 可以使用兼容 MySQL 的 CHANGE REPLICATION FILTER 命令,配置数据复制策略
CHANGE REPLICATION FILTER option [, option] ... [ channel_option ]
option: {
REPLICATE_DO_DB = (do_db_list)
| REPLICATE_IGNORE_DB = (ignore_db_list)
| REPLICATE_DO_TABLE = (do_table_list)
| REPLICATE_IGNORE_TABLE = (ignore_table_list)
| REPLICATE_WILD_DO_TABLE = (wild_do_table_list)
| REPLICATE_WILD_IGNORE_TABLE = (wile_ignore_table_list)
| REPLICATE_SKIP_TSO = 'tso_num'
| REPLICATE_SKIP_UNTIL_TSO = 'tso_num'
| REPLICATE_ENABLE_DDL = {TRUE|FALSE}
}
channel_option:
FOR CHANNEL channel
4. 可以使用兼容 MySQL 的 START SLAVE 和 STOP SLAVE 命令,启动和停止 GDN 复制链路
START SLAVE [ channel_option ]
channel_option:
FOR CHANNEL channel
STOP SLAVE [ channel_option ]
channel_option:
FOR CHANNEL channel
5. 可以使用兼容 MySQL 的 RESET SLAVE,删除 GDN 复制链路
RESET SLAVE ALL [ channel_option ]
channel_option:
FOR CHANNEL channel
拥抱生态,提供兼容 MySQL 的使用方式,可以大大降低使用门槛,但 PolarDB-X 也需要做最好的自己,我们在兼容 MySQL 的基础上,还提供了很多定制化的功能特性。
原生的轻量级双向复制能力,举例来说:
GDN 场景下,保证主从实例之间的数据一致性是最为关键的因素,提供便捷的数据校验能力则显得尤为关键,V2.4 版本不仅提供了完善的主从复制能力,还提供了原生的数据校验能力,在从实例上执行相关 SQL 命令,即可实现在线数据校验。V2.4 版本暂时只支持直接校验模式 (校验结果存在误报的可能),基于 sync point 的快照校验能力 (校验结果不会出现误报),会在下个版本进行开源。
#开启校验
CHECK REPLICA TABLE {`test_db`.`test_tb`} | {`test_db`}
[MODE='direct' | 'tso']
FOR CHANNEL xxx;
#查看校验进度
CHECK REPLICA TABLE [`test_db`.`test_tb`] | [`test_db`] SHOW PROGRESS;
#查看差异数据
CHECK REPLICA TABLE {`test_db`.`test_tb`} | {`test_db`} SHOW DIFFERENCE;
此外,数据的一致性不仅体现在数据内容的一致性上,还体现在 schema 的一致性上,只有二者都保证一致,才是真正的一致,比如即使丢失一个索引,当发生主从切换后,也可能引发严重的性能问题。PolarDB-X GDN 支持各种类型的 DDL 复制,基本覆盖了其所支持的全部 DDL 类型,尤其是针对 PolarDB-X 特有 schema 的 DDL 操作,更是实现了充分的支持,典型的例子如:sequenc、tablegroup 等 DDL 的同步。 除了数据一致性,考量 GDN 能力的另外两个核心指标为 RPO 和 RTO,复制延迟越低则 RPO 越小,同时也间接影响了 RTO,本次 V2.4 版本提供了 RPO <= 2s、RTO 分钟级的恢复能力,以 Sysbench 和 TPCC 场景为例,GDN 单条复制链路在不同网络延迟条件 (0.1ms ~ 20ms 之间) 下可以达到的最大 RPS 分布在 2w/s 到 5w/s 之间。当业务流量未触达单条复制链路的 RPS 瓶颈时,用单流 binlog + GDN 的组合来实现容灾即可,而当触达瓶颈后,则可以选择多流 binlog + GDN 的组合来提升扩展性,理论上只要网络带宽没有瓶颈,不管多大的业务流量,都可实现线性扩展,PolarDB-X GDN 具备高度的灵活性和扩展性,以及在此基础之上的高性能表现。 04 开源生态完善快速运维部署能力PolarDB-X 支持多种形态的快速部署能力,可以结合各自需求尽心选择
polardbx-operator 是基于 k8s operator 架构,正式发布 1.6.0 版本,提供了 polardb-x 数据库的部署和运维能力,生产环境优先推荐,可参考 polardbx-operator 运维指南。 polardbx-operator 1.6.0 新版本,围绕数据安全、HTAP、可观测性等方面完善集中式与分布式形态的运维能力,支持标准版的备份恢复,透明加密(TDE),列存只读(HTAP)、一键诊断工具、CPU 绑核等功能。同时兼容了 8.0.32 新版本内核,优化了备份恢复功能的稳定性。详见:Release Note。 pxd 是基于开源用户物理机裸机部署的需求,提供快速部署和运维的能力,可参考 pxd 运维。 发布 pxd 0.7 新版本,围绕版本升级、备库重搭,以及兼容 8.0.32 新版本内核。 标准版生态V2.3 版本开始,为方便用户进行快速体验,提供 rpm 包的下载和部署能力,可以一键完成标准版的安装,参考链接:
PolarDB-X 标准版,基于 Paxos 协议实现多副本,基于 Paxos 的选举心跳机制,MySQL 自动完成节点探活和 HA 切换,可以替换传统 MySQL 的 HA 机制。如果 PolarDB-X 替换 MySQL,作为生产部署使用,需要解决生产链路的 HA 切换适配问题,开发者们也有自己的一些尝试(比如 HAProxy 或 自定义 proxy)。 在 V2.4 版本,我们正式适配了一款开源 Proxy 组件。
ProxySQL 作为一款成熟的 MySQL 中间件,能够无缝对接 MySQL 协议支持 PolarDB-X,并且支持故障切换,动态路由等高可用保障,为我们提供了一个既可用又好用的代理选项,更多信息可参考文档:使用开源 ProxySQL 构建 PolarDB-X 标准版高可用路由服务 |