|
Apache SeaTunnel 2.3.8 版本现已正式发布!此次版本后,用户将可以使用期待已久的 Docker 镜像,还可以体验 Job 级别日志功能,以及其他更新优化的功能。本文将详细介绍 Apache SeaTunnel 2.3.8 版本中的关键更新内容,欢迎更多开发者和用户参与到我们的开源社区中来。
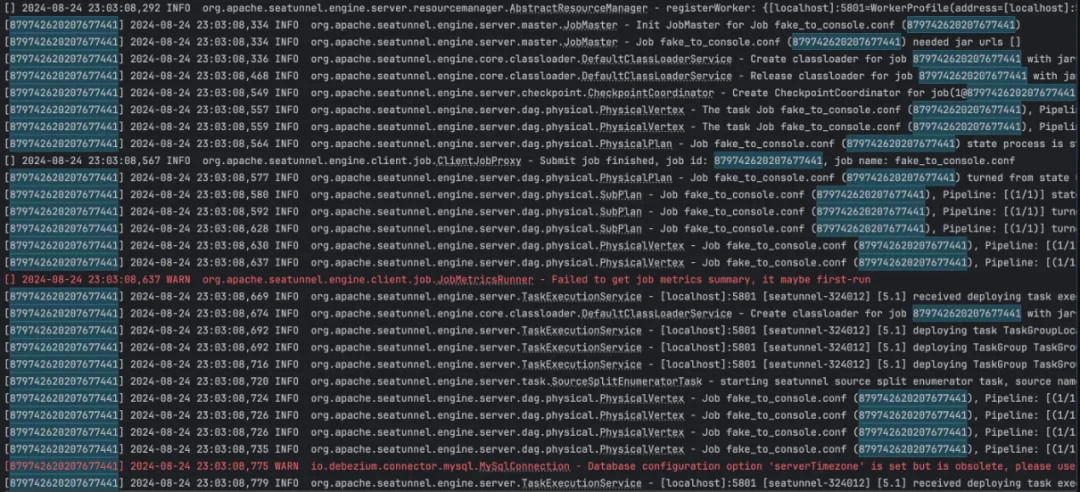
重点更新Job 级别日志此次更新中,我们对日志功能进行了优化,在之前的版本中,多个任务的日志都在一个文件中打印,当同时运行多个任务后,多个任务的日志交织在一起,不便于排查问题。 此次更新支持两种方式的配置,以实现更加高效的日志查询。 第一种是在每行日志中添加 JobId,从而可以过滤查询出每个日志单独的日志;
第二种是根据 JobId 拆分文件,只需修改日志配置文件,就可以每一个 JobId 打印单独的日志文件。
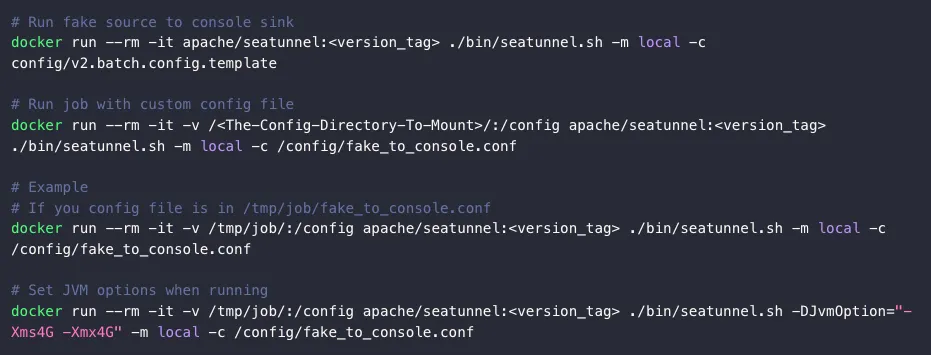
新增 Docker 镜像此次更新中,添加了官方的镜像支持,在镜像中添加了全部的连接器,用户无需下载安装包,可以直接通过拉取镜像,更加方便地运行 SeaTunnel,减小部署的复杂度,同时精简使用 K8S 部署的用户操作流程。 而对于有定制化需求,需要二次开发的用户,新版本也提供了一键式打包构建镜像的命令:
Flink/Spark 引擎支持多表之前的版本中,多表读取,写入的功能仅在 Zeta 引擎上进行了支持,此次更新后,Spark/Flink 引擎也可以进行多表读取和写入。 适配 Prometheus 进行集群监控此前,用户需要通过 API 来获取集群 / 任务的指标。现在,用户可以将指标进行导出到 Prometheus 上,Prometheus 将定期拉取 SeaTunnel 的集群任务状态,并以可视化界面展示出来,以更便利地监控集群的状态,及时发现问题。
添加 Typesense 连接器支持新增加对 Typesense 连接器的支持。 改进和优化添加 Embedding transform通过 Embedding transform,SeaTunnel 支持将机器学习模型嵌入到数据转换过程中,把原始字段转换成向量值,再存储到相应的机器学习数据库。目前,SeaTunnel 支持的机器学习模型提供商包括豆包、千帆、OpenAI,未来还将添加更多机器学习模型支持。 Kafka 支持读取 / 写入 Protobuf 类型数据增强了 Kafka 连接器对 Protobuf 数据格式的支持,在 Kafka 连接器下增加对 Protobuf 数据类型的定义,可以进行数据读取和写入。 文件支持读取压缩包增加了对压缩文件格式的读取支持,省去了解压缩的步骤。 更加细粒度的资源加载隔离支持将 ClassLoader 从任务组级别的隔离优化为任务级别,从而避免 Source/Sink 使用相同 ClassLoader 时可能造成的依赖冲突。 其他优化还包括:
关键问题修复
详细更新情况请参考 Release Note:https://github.com/apache/seatunnel/releases/tag/2.3.8 致谢贡献者感谢 @liunaijie 对本次发版工作的指导和帮助,同时感谢以下社区成员的共同努力,让本次发版工作顺利完成: hailin0, hawk9821, cl0924, sunxiaojian, dailai, corgy-w, Hisoka-X, liunaijie, chl-wxp, zhangshenghang, ISADBA, loustler, chenqianwen, FuYouJ, xxsc0529, EricJoy2048, ZhangWeike2000, jw-itq, kevinjmh, Carl-Zhou-CN, FlechazoW, PeppaPage, liugddx, Cheun99, happyboy1024, CosmosNi, Anush008, BruceWong96, zqr10159, cloud456, Gxinge, xxsc0529, luzongzhu, jiamin13579, Zuhdan, yujian225 (责任编辑:IT) |