前言
大语言模型(以下简称大模型或 LLM) 真正意义上火出圈,应该算是 OpenAI 发布 ChatGPT 后(22 年底)。从这个时间开始,到现在为止,已经过了很长一段时间了,市面上也出现了一些编程工具,比如 MarsCode、Copilot 或者 Cursor 等比较火的结合 IDE 的插件和工具。而实际上:经过了这么长时间的 LLM 产品发展,大家的编程方式真的被改变了吗?
近一年多以来,我们在 LLM 编程领域做了比较多的落地尝试,有一些成果,也发现了一些问题,可以把它们简单归纳为三个方面:
ABCoder Show
基于此,我们围绕 LLM 解决编程问题做了一些探索,将这个过程中的思考和实践沉淀成了 ABCoder 这个项目,也是我们今天分享的主角。尝试通过 ABCoder 来弥补或者解决前言中提到的一些问题,提升 LLM 在编程领域的表现能力。接下来我将会通过一个实机演示来具体说明。( 可通过文末视频链接观看 demo 内容)

这条链路是从需求沟通到对应的 IDL 生成,到项目生成,这几个标高亮的部分都是通过 ABCoder 进行辅助增强的一个流程。
当项目正式部署起来之后,继续根据新的需求进行调整,我们通过 ABCoder 理解存量项目,更新它,然后部署新的更新后的项目。可以看到,最后的项目也跑起来了。之后,我们将这个项目通过 ABCoder 进行项目的拆解。使用 ABCoder 对其进行理解和压缩,对应生成了高质量项目文档。
ABCoder 简介ABCoder 背景
ABCoder 出现的背景来自于我们对大模型在语义化场景下的一些能力涌现的观察,大模型在一定程度上具备理解问题、解答问题的能力。这为我们开启了一条充满希望的道路,我们期望借助大模型的能力,在这条道路上实现一些与编程领域相关的应用。

但实际上,在我们落地的过程中也发现了一些问题,包括大模型在处理多层次逻辑,或者涉及到复杂的一些算法设计,亦或是在大型的系统架构时,大模型的表现都没有达到我们最初的预期。时间线回到去年年底,为了尝试优化、解决我们遇到的问题,我们发起了 ABCoder 项目。
什么是 ABCoder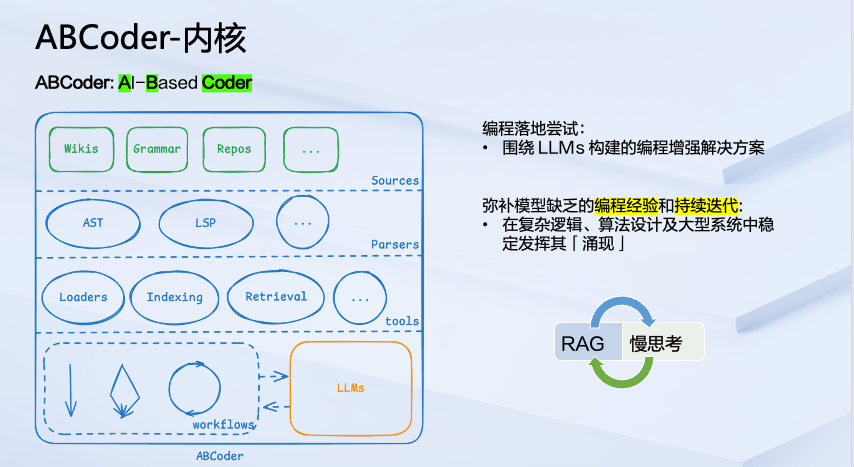
ABCoder 的命名来源于 AI-Based Coder 的缩写。核心是围绕 LLMs 构建一套 编程增强的解决方案。它能够通过弥补模型缺乏的 编程经验和 复杂逻辑思维能力,在编程和算法设计以及大型系统构建中稳定发挥 LLM 的涌现能力。
从左边的架构图可以看到,它一共分了四层:
回到真正内核的部分,整个 ABCoder 没有太多复杂的概念,主要是两个词, RAG 和 慢思考。这套系统就是为了去弥补模型在处理编程任务时缺乏的一些编程经验,我们通过 RAG 的方式去弥补编程经验的缺失,通过 workflows 弥补多级流转,让模型的生成慢下来,也就是经过多轮的迭代来尝试逼近一个更为准确的答案。
ABCoder 的实现
为了更好地让大家快速地理解 ABCoder 的本质,我们随着核心的实现来进一步阐述。熟悉 RAG 架构的同学其实很清楚了,为了实现 RAG,我们有两条具体的实现路径。
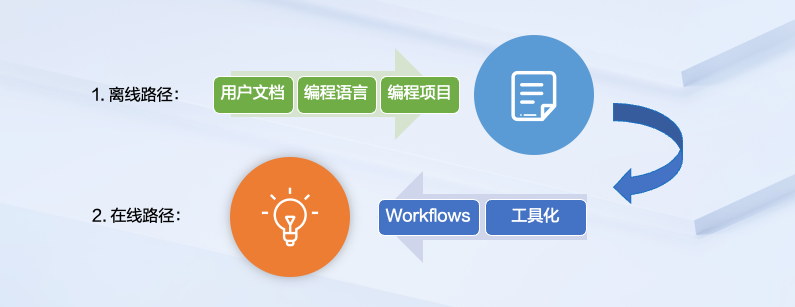
第一条是离线路径,是对于存量知识(绿框)的处理,包括用户文档、编程语言,以及编程项目都是我们核心需要处理的单位。我们将它们在离线路径上进行一些处理,转化为蓝色部分离线知识库的内容。
第二条是在线路径,我们运用知识进行工具化以及 Workflows 的封装,实现在线路径上的问答或者插件封装,以及 IDE 上的辅助能力。
离线路径
在离线实现侧,核心是上图中的第三点,即 编程项目离线 知识 的制作,对应的是我们开发的 LLM 原生解析器,负责处理编程项目。凭借这个能力,我们将编程项目自身作为一个知识来源,结合 LLM 来主动生成和丰富用户文档,作为用户文档的补充。

举例说明,图中左侧列出来的是一个典型的 Hertz 项目的 Layout。我们现在要将这个项目输入到 LLM 里,如果单纯地去输入这个项目本身,那将有若干个文件;如果将这些文件一股脑灌给 LLM,它也并不能很好地去理解这些文件集合。但实际上我们的编程项目有一个内在的关联性,这个关联性是什么呢?可以看到这里有一个例子,我们通过解析 - 压缩 - 结构化,得到了上图右侧部分看起来像是一棵树的结构,这个树的结构就是我们在项目里函数调用的一棵树。main 对应的是 main 函数,它同时依赖 r egister 以及 server.Default 这两个函数节点,它们可能也有额外的子依赖。这个树状的依赖关系其实就是项目中函数调用的关系的呈现。

上图左下侧可以看到,在这棵树下列出了五个函数和它的描述所对应的列表。这里有一个小细节,就是 1、2、3、4、5 的顺序是从这棵树叶子节点开始反向往上去理解,直到最上层的 main 函数。原因非常简单,我们在做 ABCoder 理解时,就是按照这样的顺序一步一步将整个项目进行拆解,最终达到 main。因此,每一个函数只需要关注自己所调用的函数以及本身内在的逻辑就够了,这样可以一定程度减少我们在理解函数节点时模型本身的上下文发散,或者说避免一股脑输入的信息超过了我们希望让它生成或者联想的上下文限制的问题,来保证信息准确、聚焦,达到很好的理解和压缩的效果。
以上是我们用函数作为一个示例。在处理编程项目时,除了函数以外,同时还包括对类型以及变量的处理。通过这套语言无关的 Schema 抽象,最终得到的就是将编程语言或源代码作为最后在线路径上用到的 knowledge,整个过程概括为一句话,即图中红色框所示 —— Source code as knowledge。
在线路径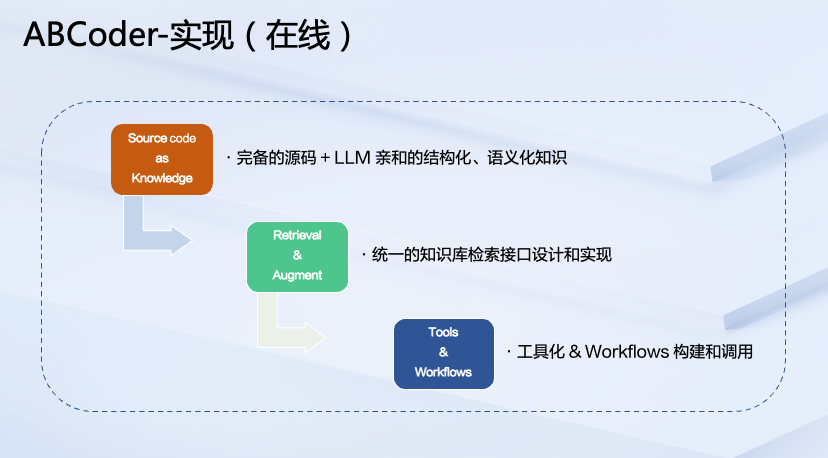
相对离线路径,在线路径方面的实现非常简单。我们将经过 ABCoder 处理并消化后的知识,结合 Retrieval & Augment(检索 & 增强)来实现工具化以及 Workflows 的构建和调用,最终在在线链路上就能够很好地去用到刚刚在离线阶段处理的这些源码知识了。
应用落地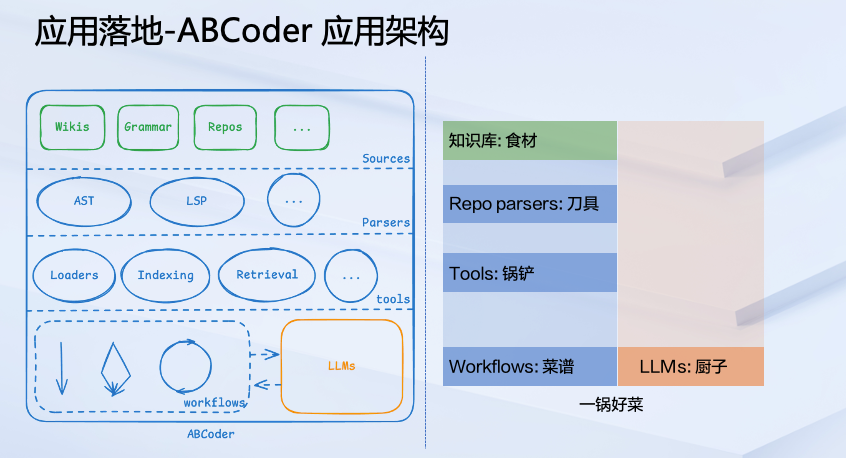
接下面我们来看看在应用侧是怎样的状态。回到整体架构图。有人说过这么一句话:不会做饭的厨子不是好的程序员,我觉得这句话很有意思,顺着这个逻辑,我尝试将我们的架构做了一个形象的拆解,左边是我们的架构,右边映射到的是如果将做饭这个过程映射到这套架构中,看看每一层究竟对应的是什么样的角色?
首先,最上面绿色的部分对应的是知识库,它就是我们做饭的食材。Repo parsers 对应的是刀具,我们需要将食材通过 Repo parsers 进行一些拆解、分割,把它做到适合去炒、蒸或者煮的形态。之后,结合大量的 Tools,对应的就是锅铲类似的烹饪工具,帮助我们去处理不同形态的食材,或者在不同的阶段去处理食材。最下面这层就是 Workflows 菜谱加上 LLMs 厨子,有了菜谱,加上厨子,结合上面的烹饪工具就能够做出一锅好菜了。回过头来看 ABCoder 的这套架构,聪明的小伙伴可能已经发现,ABCoder 对应的并不是具体的某一个应用,而是一系列的应用,或者说其实是孵化应用的基座。

通过 Tools、Workflows 以及知识库进行有机组合我们就能够尝试构建出一系列的应用。上图是我们内部目前正在尝试的三大应用落地方向。
第一个方向是 SmartComment,它也是 ABCoder 能力最直接的应用尝试,它的目标是产出高质量的注释以及相关的用户文档,核心的 workflows 以及 Tools 如图表中所示,对应的知识库就是 ABCoder 解析完之后的仓库语料。其他几个方向也可以在图表中看到。
应用落地的里程碑
以上提到的三大应用制定了近期和远期的里程碑。当前,三大应用方向近期的里程碑已经陆陆续续达成。在远期上,SmartComment 将在半年到一年的时间内,探索出一套文档工程相对应的实现,即 Code2Wiki,就是通过源码的方式去补充用户文档的数量以及质量。在 Wiseman 侧,远期是希望实现从需求沟通到 全自动化研发流程的构建。语言翻译侧,不仅仅要做到项目本身的翻译,远期将实现的是一套渐进式的翻译流,包括 项目以及研发人力 的 A2B 转换,共同成长。
未来规划与展望关于开源
在开源方面,ABCoder 将会以围绕 CloudWeGo 构建 AI 驱动的微服务生态体系作为我们的核心目标。
在关键路径上,我们后续将对 CloudWeGo 所有的组件进行 ABCoder 索引化,刚刚在 demo 里看到的处理 Hertz 的这套流程,将会无缝应用到 CloudWeGo 下的所有组件。之后,ABCoder 的应用将走进 CloudWeGo 社区,包括在研发行为以及社区生态上,为研发社区赋能。最后,当应用成熟度打磨到一定阶段,将在 CloudWeGo 上完成正式开源,之后以社区的方式进行持续迭代和演进。
关于展望
在内部,ABCoder 提供的是编程语言结合 LLM 的一套解决方案,其终极理想形态被称为「 空」。「空」是一套语言中立的编程范式,它是完全 LLM 原生的一套编程模式,期望能够为整个生产流程以及后面的发布流程,打通整个相关生态。
在外部,ABCoder 的表现在一定程度上依赖模型本身的能力。外部陆续发布的一些模型,也让我们看到了一些眼前一亮的突破,包括模型本身在深度和广度上的突破。近期一个叫做 OpenAI O1 的模型发布是一个比较好的例子。它通过引入类似强化学习的方式,在模型中内置一条思维链,主动将模型的生成降速,结合多轮思考和评估能够有效解决更加复杂的问题,其表现出的能力也是之前其他的模型未曾带来的。结合这类模型,或许在未来也会持续突破目前 LLM 在编程领域的一些能力边界。
|