3. IPC(Interprocess Communication)namespace容器中进程间通信采用的方法包括常见的信号量、消息队列和共享内存。然而与虚拟机不同的是,容器内部进程间通信对宿主机来说,实际上是具有相同PID namespace中的进程间通信,因此需要一个唯一的标识符来进行区别。申请IPC资源就申请了这样一个全局唯一的32位ID,所以IPC namespace中实际上包含了系统IPC标识符以及实现POSIX消息队列的文件系统。在同一个IPC namespace下的进程彼此可见,而与其他的IPC namespace下的进程则互相不可见。 IPC namespace在代码上的变化与UTS namespace相似,只是标识位有所变化,需要加上CLONE_NEWIPC参数。主要改动如下,其他部位不变,程序名称改为ipc.c。{测试方法参考自:http://crosbymichael.com/creating-containers-part-1.html}
我们首先在shell中使用ipcmk -Q命令创建一个message queue。
通过ipcs -q可以查看到已经开启的message queue,序号为32769。
然后我们可以编译运行加入了IPC namespace隔离的ipc.c,在新建的子进程中调用的shell中执行ipcs -q查看message queue。
上面的结果显示中可以发现,已经找不到原先声明的message queue,实现了IPC的隔离。
目前使用IPC namespace机制的系统不多,其中比较有名的有PostgreSQL。Docker本身通过socket或tcp进行通信。
5. Mount namespacesMount namespace通过隔离文件系统挂载点对隔离文件系统提供支持,它是历史上第一个Linux namespace,所以它的标识位比较特殊,就是CLONE_NEWNS。隔离后,不同mount namespace中的文件结构发生变化也互不影响。你可以通过/proc/[pid]/mounts查看到所有挂载在当前namespace中的文件系统,还可以通过/proc/[pid]/mountstats看到mount namespace中文件设备的统计信息,包括挂载文件的名字、文件系统类型、挂载位置等等。 进程在创建mount namespace时,会把当前的文件结构复制给新的namespace。新namespace中的所有mount操作都只影响自身的文件系统,而对外界不会产生任何影响。这样做非常严格地实现了隔离,但是某些情况可能并不适用。比如父节点namespace中的进程挂载了一张CD-ROM,这时子节点namespace拷贝的目录结构就无法自动挂载上这张CD-ROM,因为这种操作会影响到父节点的文件系统。 2006 年引入的挂载传播(mount propagation)解决了这个问题,挂载传播定义了挂载对象(mount object)之间的关系,系统用这些关系决定任何挂载对象中的挂载事件如何传播到其他挂载对象{![参考自:http://www.ibm.com/developerworks/library/l-mount-namespaces/]}。所谓传播事件,是指由一个挂载对象的状态变化导致的其它挂载对象的挂载与解除挂载动作的事件。
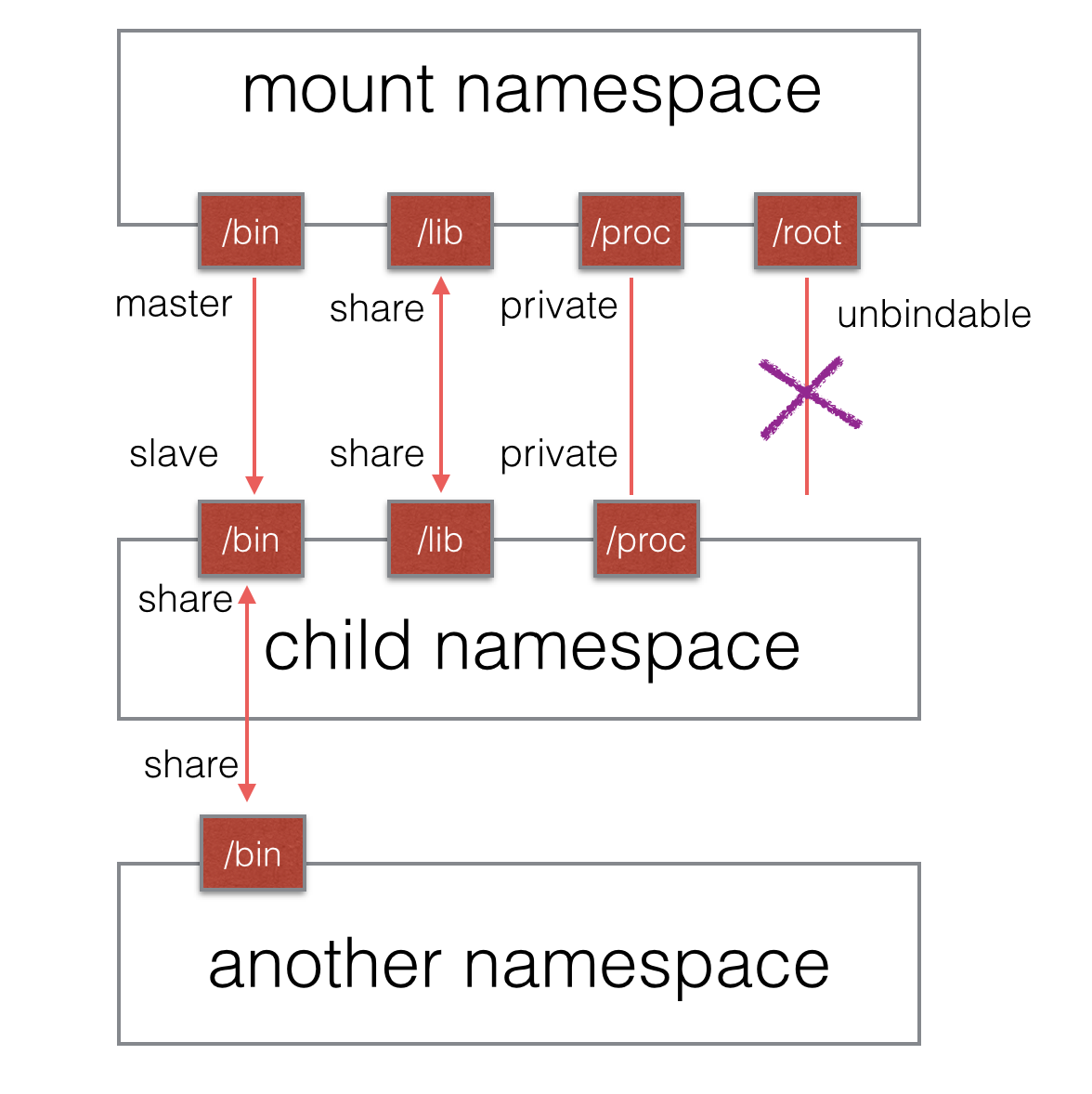
一个挂载状态可能为如下的其中一种:
传播事件的挂载对象称为共享挂载(shared mount);接收传播事件的挂载对象称为从属挂载(slave mount)。既不传播也不接收传播事件的挂载对象称为私有挂载(private mount)。另一种特殊的挂载对象称为不可绑定的挂载(unbindable mount),它们与私有挂载相似,但是不允许执行绑定挂载,即创建mount namespace时这块文件对象不可被复制。
图1 mount各类挂载状态示意图 共享挂载的应用场景非常明显,就是为了文件数据的共享所必须存在的一种挂载方式;从属挂载更大的意义在于某些“只读”场景;私有挂载其实就是纯粹的隔离,作为一个独立的个体而存在;不可绑定挂载则有助于防止没有必要的文件拷贝,如某个用户数据目录,当根目录被递归式的复制时,用户目录无论从隐私还是实际用途考虑都需要有一个不可被复制的选项。 默认情况下,所有挂载都是私有的。设置为共享挂载的命令如下。
从共享挂载克隆的挂载对象也是共享的挂载;它们相互传播挂载事件。 设置为从属挂载的命令如下。
从从属挂载克隆的挂载对象也是从属的挂载,它也从属于原来的从属挂载的主挂载对象。 将一个从属挂载对象设置为共享/从属挂载,可以执行如下命令或者将其移动到一个共享挂载对象下。
如果你想把修改过的挂载对象重新标记为私有的,可以执行如下命令。
通过执行以下命令,可以将挂载对象标记为不可绑定的。
这些设置都可以递归式地应用到所有子目录中,如果读者感兴趣可以搜索到相关的命令。 在代码中实现mount namespace隔离与其他namespace类似,加上CLONE_NEWNS标识位即可。让我们再次修改代码,并且另存为mount.c进行编译运行。
执行的效果就如同PID namespace一节中“挂载proc文件系统”的执行结果,区别就是退出mount namespace以后,root namespace的文件系统不会被破坏,此处就不再演示了。 (责任编辑:IT) |