|
摘要 本文介绍了Docker Registry服务几个组件的构成,怎么规划定制一个私有镜像库,以及镜像服务pull/push操作性能分析、并发性能分析,帮助大家按照需求大家自己需要的镜像服务。在微信群内做了分享,后面有一些大家的讨论。
目录[-]
docker-index
docker-registry
后端存储
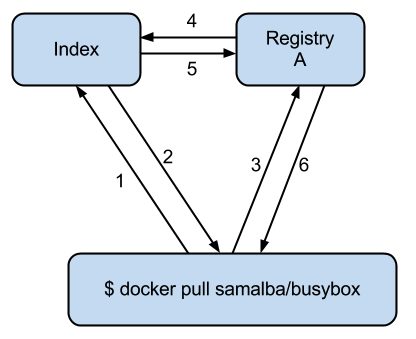
一次docker pull发生的交互
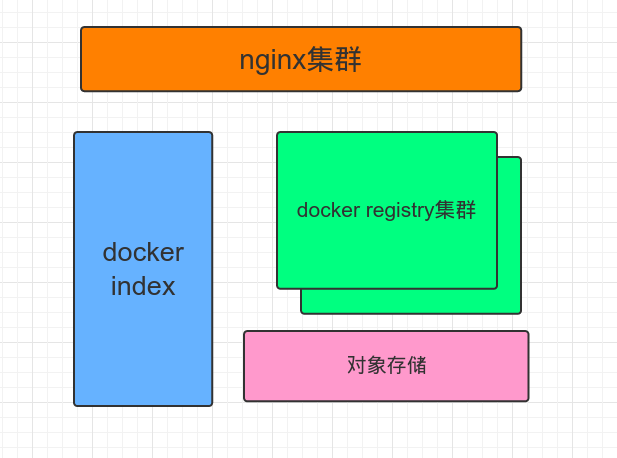
搭建私有镜像库的方案
上面的index,registry,后端存储3者都是可选的。registry分0.9的python版实现和2.0版的go实现。 认证和权限如果镜像库不直接提供给用户使用,仅仅是私有PaaS的一部分,可以不用index组件,直接上registry就行。index的开源实现包括docker-registry-web,docker-registry-frontend。支持较好的是马道长的wharf。 后端存储我们环境使用的是网易的内部的对象存储NOS,类似于S3。其他的方案没用过,如果要自己搭,可能靠谱的是ceph-s3。如果在公网环境或者已经购买了公有云服务,可以考虑自己实现一个registry-对象存储的驱动。 集群和分布式registry本身是无状态的,可以水平扩展,然后在前面做ngix的负载均衡。 性能分析v1协议 vs v2协议
客户端|push总时间|pull总时间 做了性能对比测试,同样为docker1.6,v2协议比v1协议快5-6%左右,基本可以忽略不计。 单次pull和push的性能分析
层|docker push|curl put
层|docker pull|curl get 经过对比测试,单次docker pull和push的最大耗时在客户端,也可以观察到每次做docker pull和push的时候系统CPU占用率都在100%。也就是说50%以上的时间花在本地做的压缩、计算md5等操作。 并发分析并发测试的结果是在一个2核2G内存的registry-0.9服务器,直接用文件存储,大约能负载50个docker client的并发。如果换用对象存储的后端,估计10个docker client的并发就是极限了。在这方面registry-2.0的并发能力更强,但对内存消耗更大。 Q&A
问:2.0的性能也没什么变化啊,优势在哪里?
问:服务端的并发瓶颈在哪里?
问:考虑过多机房image存储CDN没?
问:那还不如每机房加缓存?
问:你们的调度器是自己开发的吗?
问:内部的PaaS有没有做资源限制、网络隔离?
问:昨天网易好多服务断片了,据说是网络攻击,那这些服务有跑在Docker上吗?
问:有没有考虑过nova-docker?
问:为啥不考虑自己实现调度器?
问:我们准备在某公有云上跑Docker集群。 =========================== |