|
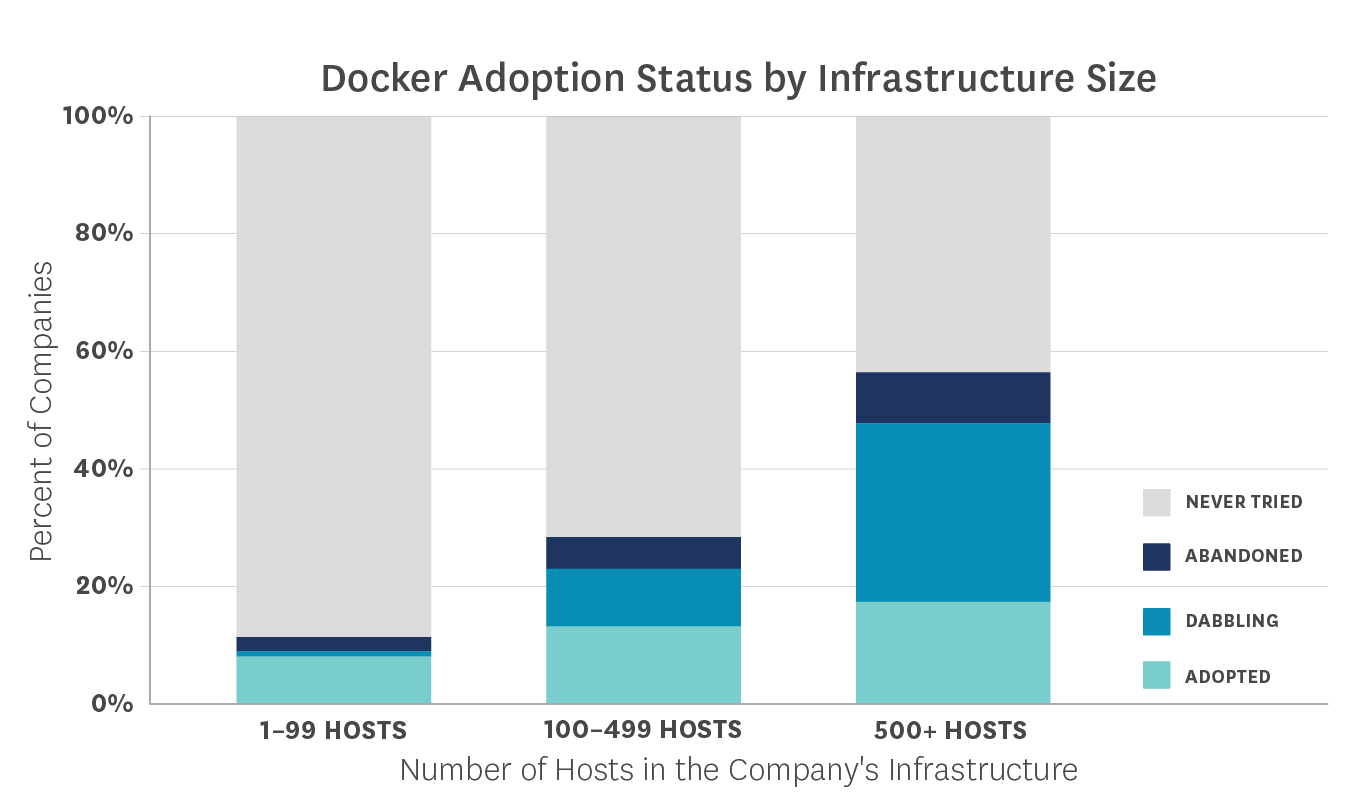
如今,越来越多的公司开始使用 Docker 了,现在来给大家看几组数据:
也就是说 Docker 的转化率达到了 67%,而转化时长也控制在 60 天内。
Docker 监控实战
研究发现主机数量越多的公司,越早开始使用 Docker。而主机数量多,在这个研究里就默认等同于是大型公司了。
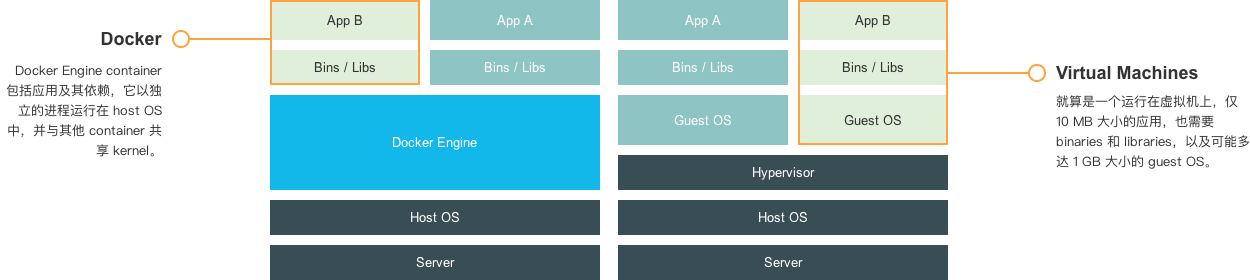
Docker 监控实战 Docker 优势那为什么 Docker 越来越火呢?一谈起 Docker 总是会跟着让人联想到轻量这个词,甚至会有一种通过 Docker 启动一个服务会节省很多资源的错觉。然而 Docker 的「轻」也只是相对于传统虚拟机而已。 传统虚拟机和 Docker 的对比如图:
Docker 监控实战 从图中可以看出 Docker 和 虚拟机的差异,虚拟机的 Guest OS 和 Hypervisor 层在 Docker 中被 Docker Engine 层所替代,Docker 有着比虚拟机更少的抽象层。 由于 Docker 不需要通过 Hypervisor 层实现硬件资源虚拟化,运行在 Docker 容器上的程序直接使用实际物理机的硬件资源。因此在 CPU、内存利用率上 Docker 略胜一筹。 Docker利用的是宿主机的内核,而不需要 Guest OS,因此,当新建一个容器时,Docker 不需要和虚拟机一样重新加载一个操作系统内核,因此新建一个 Docker 容器只需要几秒钟。 总结一下 Docker 容器相对于 VM 有以下几个优势:启动速度快、资源利用率高、性能开销小。 Docker 监控方案那么,Docker 如何监控呢?可能具体问题要具体分析。但是似乎大家都在使用开源的监控方案,来解决 Docker监控的问题。 就拿腾讯游戏来说吧,我们看看尹烨(腾讯互娱运营部高级工程师)怎么说:
Docker 监控实战
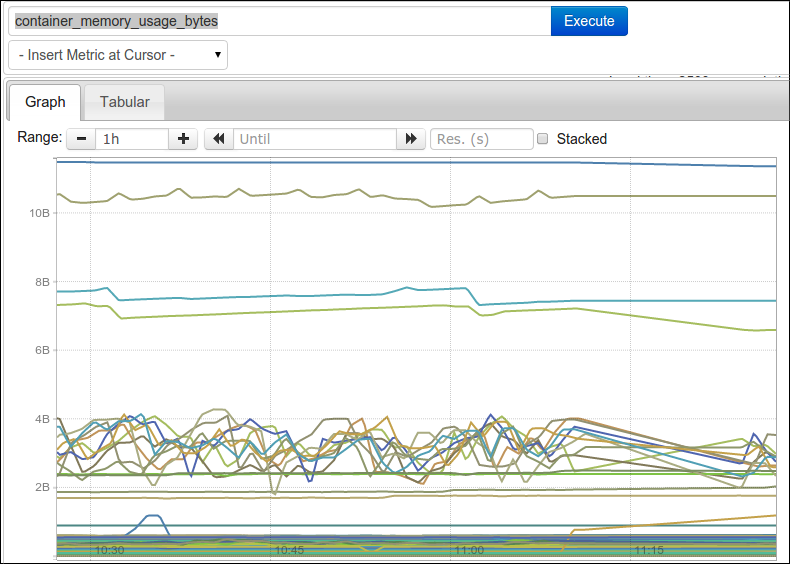
在没有专业运维团队来监控 Docker 的情况下,并且还想加快 Docker 监控的日程,怎么办呢? 为了能够更精确的分配每个容器能使用的资源,我们想要实时获取容器运行时使用资源的情况,怎样对 Docker 上的应用进行监控呢?Docker 的结构会不会加大监控难度? 我们都了解, container 相当于小型 host,可以说存在于 hosts 与应用之间的监控盲区,无论是传统的基础组件监控还是应用性能监控的方式,都很难有效地监控 Docker。了解了一下现有的 Docker 相关监测 App 和服务,包括简单的开源工具和复杂的企业整体解决方案,下面列举其中的几种作为参考: 1. cAdvisor谷歌的 container introspection 解决方案是 cAdvisor,这是一个 Docker 容器内封装的实用工具,能够搜集、集料、处理和导出运行中的容器的信息。通过它可以看到 CPU 的使用率、内存使用率、网络吞吐量以及磁盘空间利用率。然后,你可以通过点击在网页顶部的 Docker Containers 链接,然后选择某个容器来详细了解它的使用情况。cAdvisor 部署和使用简单,但它只可以监视在同一个 host 上运行的容器,对多节点部署不是太管用。 2. Cloud Insight在我们列举的几个监控 Docker 的服务或平台中,这是唯一一款国内产品。Cloud Insight 支持多种操作系统、云主机、数据库和中间件的监控,原理是在平台服务仪表盘和自定义仪表盘中,采集并处理 Metric,对数据进行聚合与分组等计算,提供曲线图、柱状图等多样化的展现形式。优点是监控的指标很全,简单易用,但目前正式版还未上线,可以期待一下。 3. ScoutScout 是一款监视服务,并不是一个独立的开源项目。它有大量的插件,除了 Docker 信息还可以吸收其他有关部署的数据。因此 Scout 算是一站式监控系统,无需对系统的各种资源来安装各种不同的监控系统。 Scout 的一个缺点是,它不显示有关每个主机上单独容器的详细信息。此外,每个监控的主机十美元这样略微昂贵的价格也是是否选择 Scout 作为监控服务的一个考虑因素,如果运行一个有多台主机的超大部署,成本会比较高。 4. SematextSematext 也是一款付费监控解决方案,计划收费方案是3.5美分/小时。同样也支持 Docker 监控,还包括对容器级事件的监测(停止、开始等等)和管理容器产生的日志。 Docker 监控实践Prometheus我们先来说说一套开源的 Docker 监控方案:Prometheus;而此篇文字的原文地址:Monitor Docker Containers with Prometheus。 Prometheus 由 SoundCloud 发明,适合于监控基于容器的基础架构。Prometheus 特点是高维度数据模型,时间序列是通过一个度量值名字和一套键值对识别。灵活的查询语言允许查询和绘制数据。它采用了先进的度量标准类型像汇总,从指定时间跨度的总数构建比率或者是在任何异常的时候报警并且没有任何依赖,中断期间使它成为一个可靠的系统进行调试。 Prometheus 支持维度数据,你可以拥有全局和简单的指标名像 container_memory_usage_bytes ,使用多个维度来标识你服务的指定实例。 我已经创建了一个简单的 container-exporter 来收集 Docker 容器的指标以及输出给 Prometheus 来消费。这个输出器使用容器的名字,id 和 镜像作为维度。额外的 per-exporter 维度可以在 prometheus.conf 中设置。 如果你使用指标名字直接作为一个查询表达式,它将返回有这个使用这个指标名字作为标签的所有时间序列。
如果你运行了许多容器,这个看起来像这样:
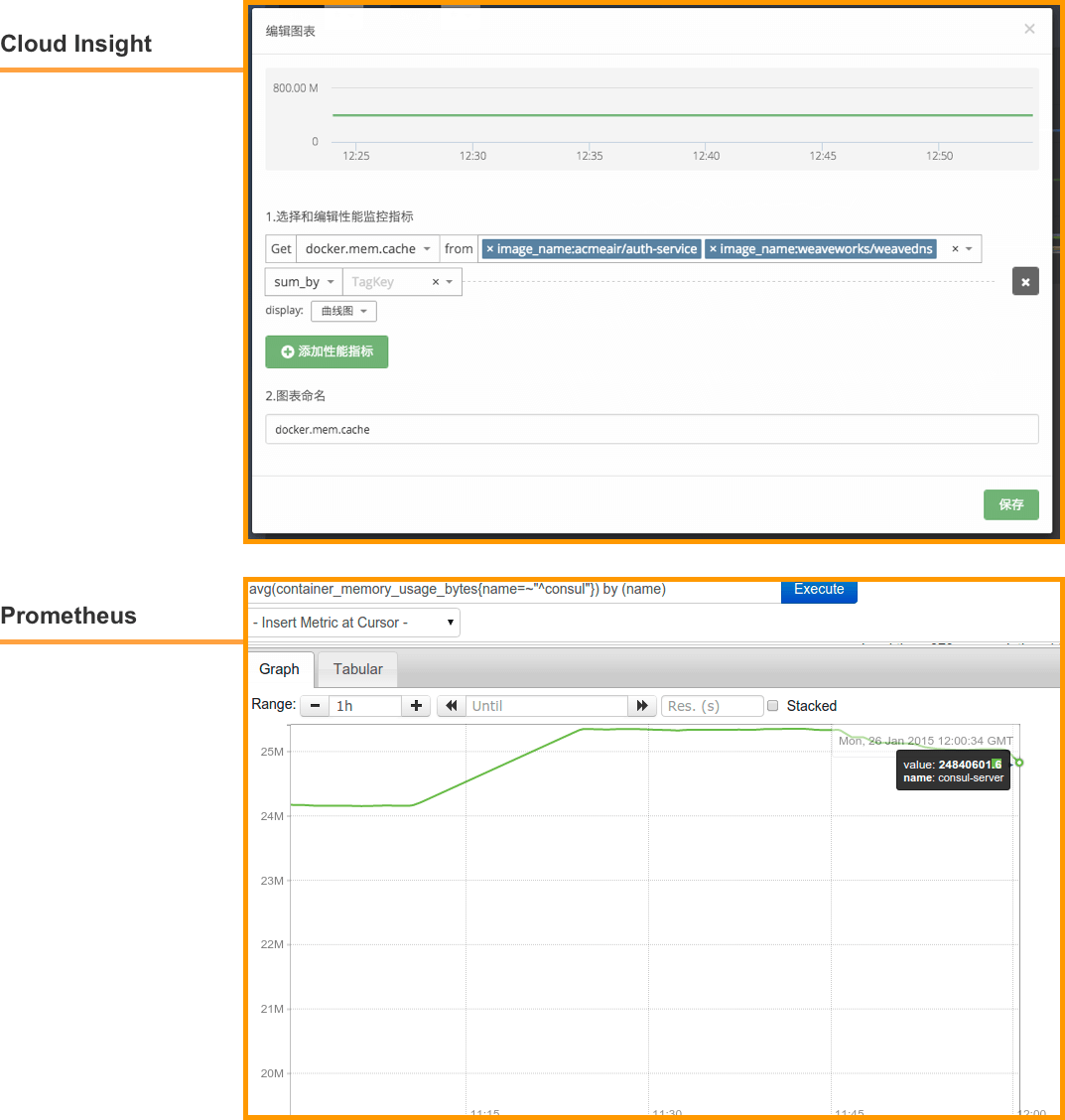
Docker 监控实战 为了帮助你使得这数据更有意义,你可以过滤 and/or 聚合 这些指标。 使用 Prometheus 的查询语言,你可以对你想的任何维度的数据切片和切块。如果你对一个给定名字的所有容器感兴趣,你可以使用一个表达式像 container_memory_usage_bytes{name="consul-server"},这个将仅仅显示 name == "consul-server" 的时间序列。 像多维度的数据模型,来实现数据聚合、分组、过滤,不单单是 Prometheus。OpenTSDB 和 InfluxDB 这些时间序列数据库和系统监控工具的结合,让系统监控这件事情变得更加的多元。 接下来,我们为大家介绍国内一家同样提供该功能的监控方案:Cloud Insight。有关其数据聚合的功能可以阅读:数据聚合 & 分组:新一代系统监控的核心功能。 现在我们来对比 Prometheus 和 Cloud Insight 在数据聚合、分组(切片)上的展现效果和功能。 数据聚合 根据不同的 Container Name 或 Image Name 对内存使用量或 Memeory Cache 进行聚合。
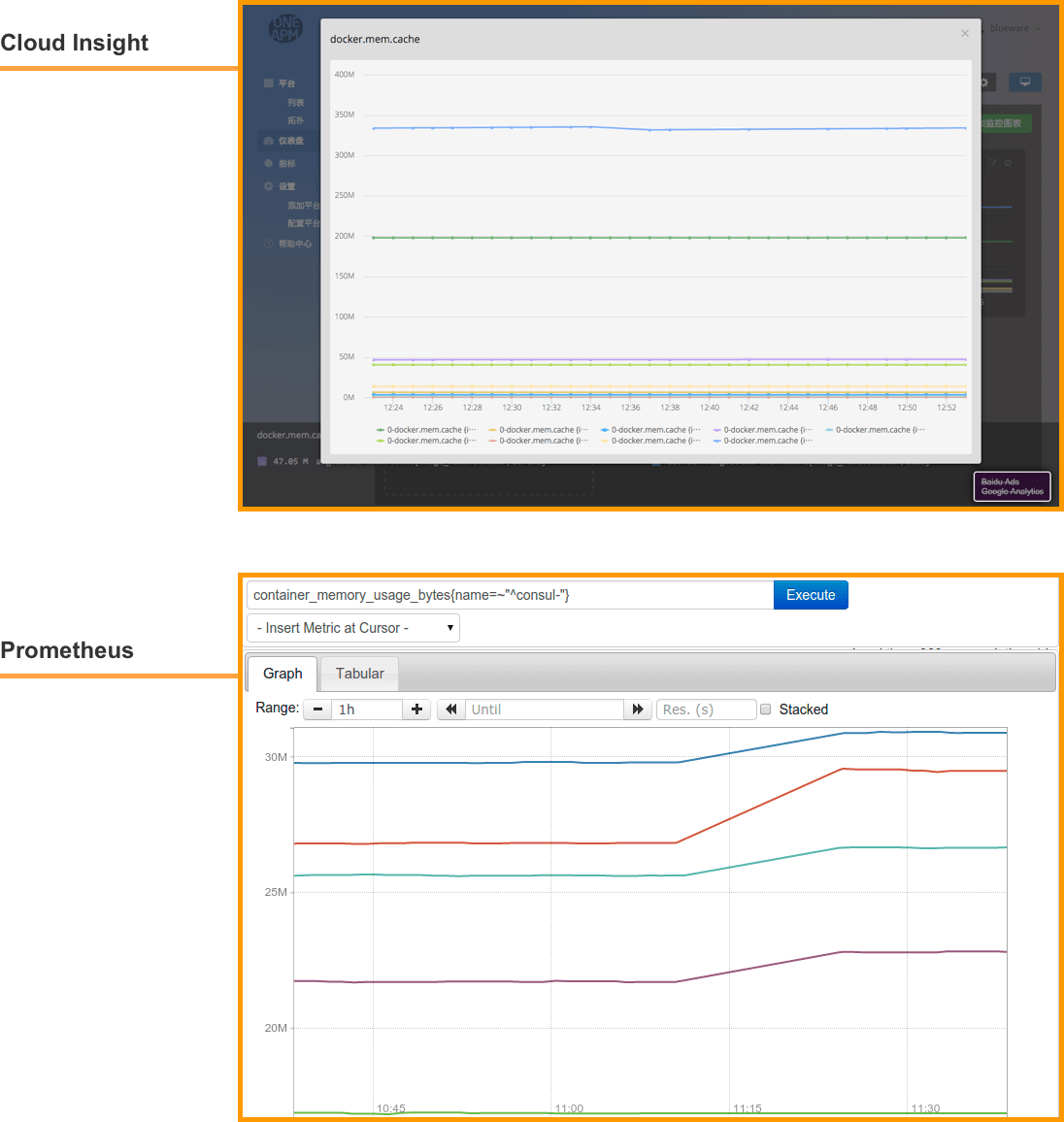
Docker 监控实战 数据分组(切片) 根据不同的 Container Name 或 Image Name 对内存使用量或 Memeory Cache进行分组(切片)。
Docker 监控实战 Docker 监控实战单方面监控 Docker 可能并不太适合与业务挂钩的应用,当业务量上涨,不单单是 Docker 的负载上升,其他 JVM 指标也能也会出现上升的趋势。 我们尝试使用一个支持比较多中间件、数据库、操作系统、容器的 Cloud Insight 来说明这个实际的场景。 Cloud InsightCloud Insight 由于是一个 SaaS 监控方案,相对来说它的安装和部署都比较简单。在这次监控实战中,我们以 AcmeAir 为实验对象:一个可以模拟压力的电子商务类应用。 AcmeAir 是一款由原 IBM 新技术架构部资深工程师 Andrew Spyker,利用 Netflix 开源的 Netflix OSS 打造的开源电子商务应用。此应用具有如下特性:
Docker 监控实战 首先,我们要打开 Cloud Insight 监控,还好 Cloud Insight 安装简单,一条命令即可。接着,我们新建一个用于此次监控的仪表盘,依次将想要获取的指标统统添加进去。比如,选中 jvm.non_heap_memory 这个指标,选择按照 instance 分组。 我们添加以下指标:
添加后,由自定义仪表盘中的显示效果如图:
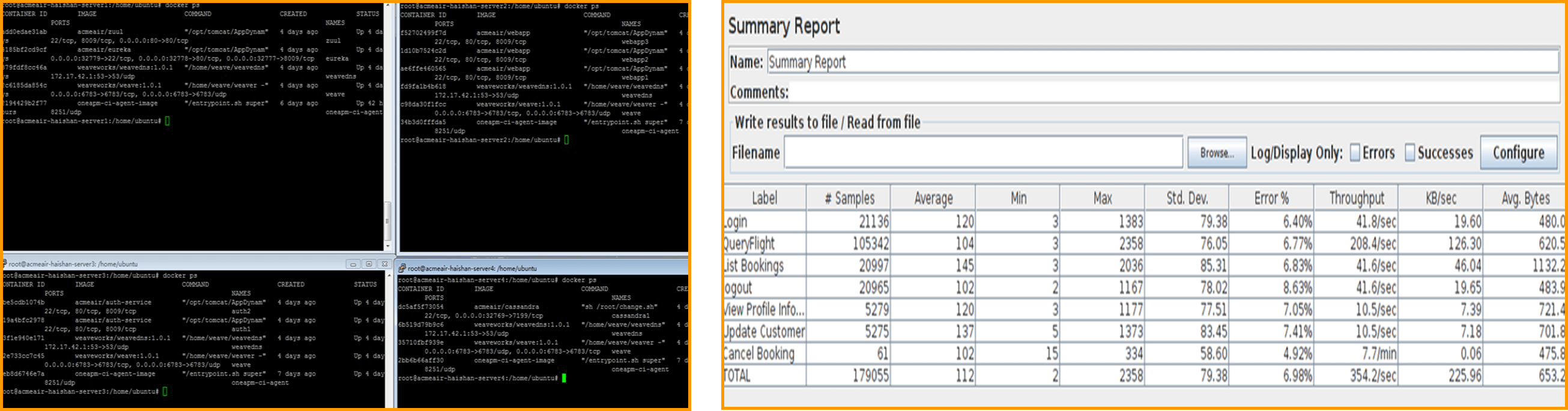
Docker 监控实战 应用 Acme 部署在四台 servers 上,我们开启四台 servers, 然后用 JMeter 给应用加压。
Docker 监控实战 随着时间 JMeter 不断给应用加压,当 users 人数达到 188 时,我们再来看一下仪表盘的视图。
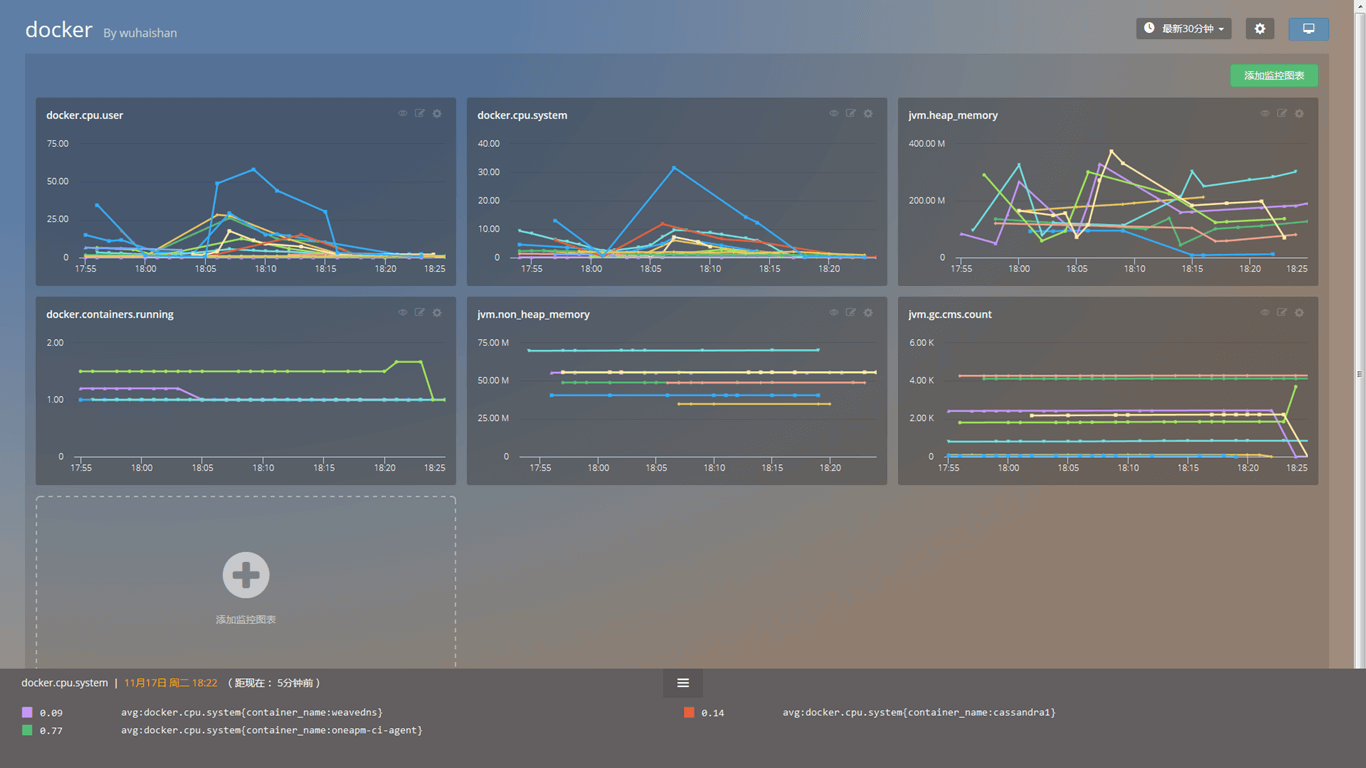
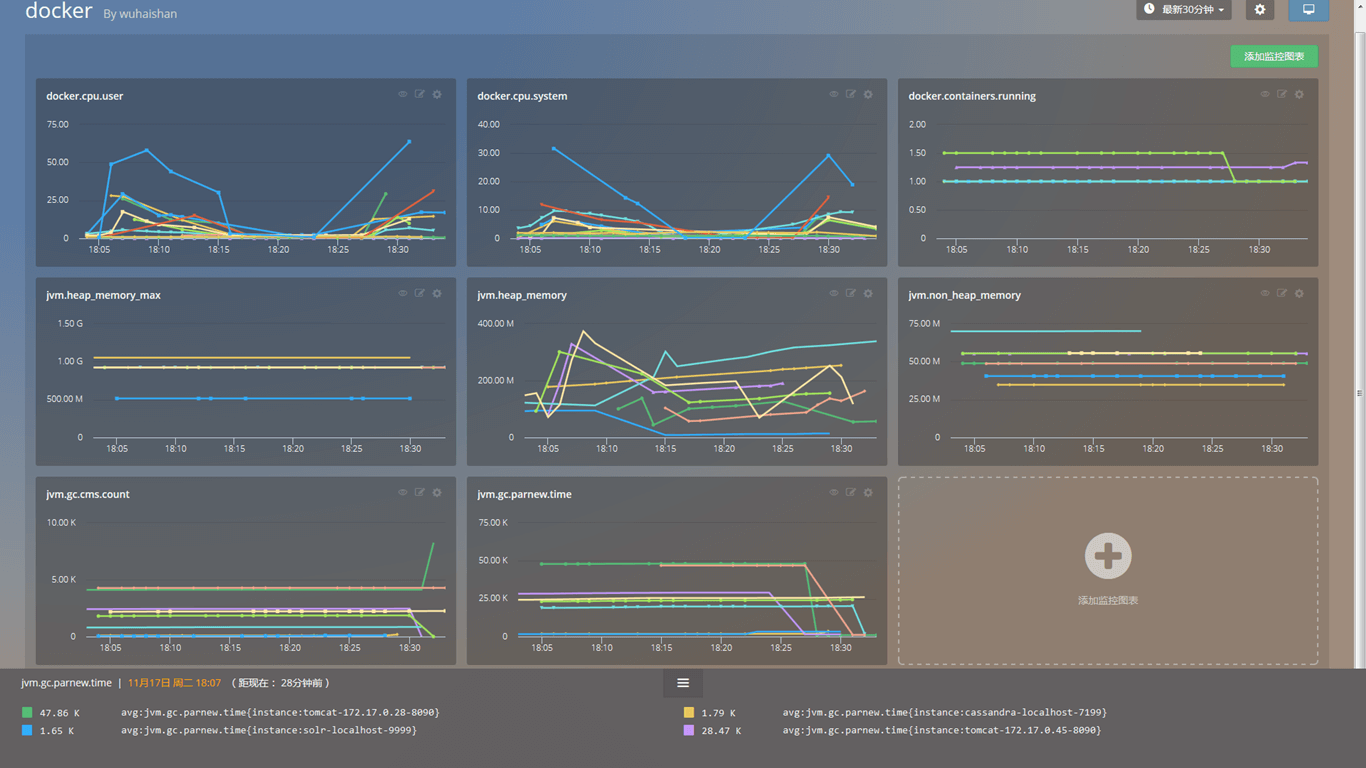
Docker 监控实战 如图,性能数据发生了变化,根据 JMeter 里的数据,CPU 占用和错误率都有所提升;与此同时,根据 Cloud Insight 里的曲线显示,在指标 docker.cpu.user 这幅图中,蓝色的线所代表的 Container CPU 占用率已经超过 50%,逐渐接近 75%,系统剩余的 CPU 资源逐渐下降。 而指标 docker.cpu.system 图中同样可以看到蓝色的那条数据在 18:29 左右出现了一个波峰,代表系统 CPU 资源消耗突然增大。通过这两幅图,我们可以定位到 CPU 占用率过高的 Container ,及时而主动地去了解性能瓶颈,从而优化性能,合理分配资源。 再看 jvm.heap_memory 指标,图中几条曲线在 18:20 之后逐渐升高,黄色曲线在 18:28 左右出现波峰,浅蓝色曲线数值较高,用 jvm.heap_memory 的值去比左图 jvm.heap_memory_max 的值,将能更清楚的反映 JVM 堆内存的消耗情况。 而 jvm.gc.parnew.time 图中显示了新生代并行 GC 的时间数据。GC 是需要时间和资源的,不好的 GC 会严重影响系统的系能,良好的 GC 是 JVM 高性能的保证。 无法被监控的软件是很危险的,通过解读这张 Docker 仪表盘总览图,我们可以了解到 Docker 实时性能状况,精准定位到性能薄弱的环节,从而优化我们的应用。 总结Docker 兼容相比其他的数据库、系统、中间件监控,要复杂一些。由于需要表征不同 Container 的性能消耗,来了解不同应用的运行情况,所以数据的聚合、切片(分组)和过滤,在 Docker 监控中成为了必备功能。 所以我们推荐使用了时间序列数据库,或者类似设计逻辑的监控方案,如:Prometheus 和 Cloud Insight。 而 Docker 单方面的监控,可能不太满足一些大型公司的需求,如果一个工具在监控 Docker 同时能够监控其他组件,那就更好了。 国外出现了 Graphite、Grafana 和 Host Graphite,能够让用户将不同数据来源都集中在同一个地方进行展现;而国内 Cloud Insight 似乎也是这样的思路。 (责任编辑:IT) |