|
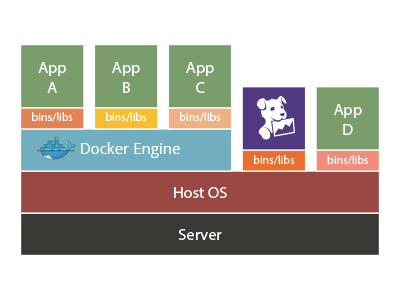
Docker 是一个构建部署应用的新兴平台,它使用被称之为轻量级虚拟机的容器。通过为开发者提供易于部署的解决方案,及对不同环境的兼容, Docker 成为在现代基础设施之上解决持续交付问题的流行方案。 与之前的虚拟机一样,这些容器需要一种新的途径来监控。幸运的是,如果你是一个 Datadog 用户,将可以利用 Datadog 对 Docker 的监控集成。 使用我们对 Docker 的监控集成,你可以运行 4.3.1 版本的 Datadog 代理 来监控容器。而这个监控配置,就如同其他基于代理的集成一样,是一个简单的 YAML 文件 。 Docker 监控是怎么工作的通过在主机上运行 Datadog 代理是监控 Docker 容器最简单的方式,在这种情况下它可以直接获取容器的数据。当你将 Docker 部署到延用已经存在应用(例如数据库)的主机上时,情况更是如此。
由于 Docker 使用了内核结构( namespaces 和 cgroups )来运行容器,因此,Datadog 代理可以直接使用 cgroup 的指标报告每十五秒收集一次 CPU 、内存、网络和 IO 数据。
使用标签有效监控多个容器凭借易于使用的轻量级容器,你可以连接数倍于底层物理机或虚拟机的容器。那如何无需为每一个容器单独花费时间就能够追踪和监控它们呢?答案就是使用标签。 标签 是不花费额外努力来监控大量容器的关键。默认情况下,代理会监控你的容器,并且将 Docker 的名字、镜像以及命令属性转换成标签。
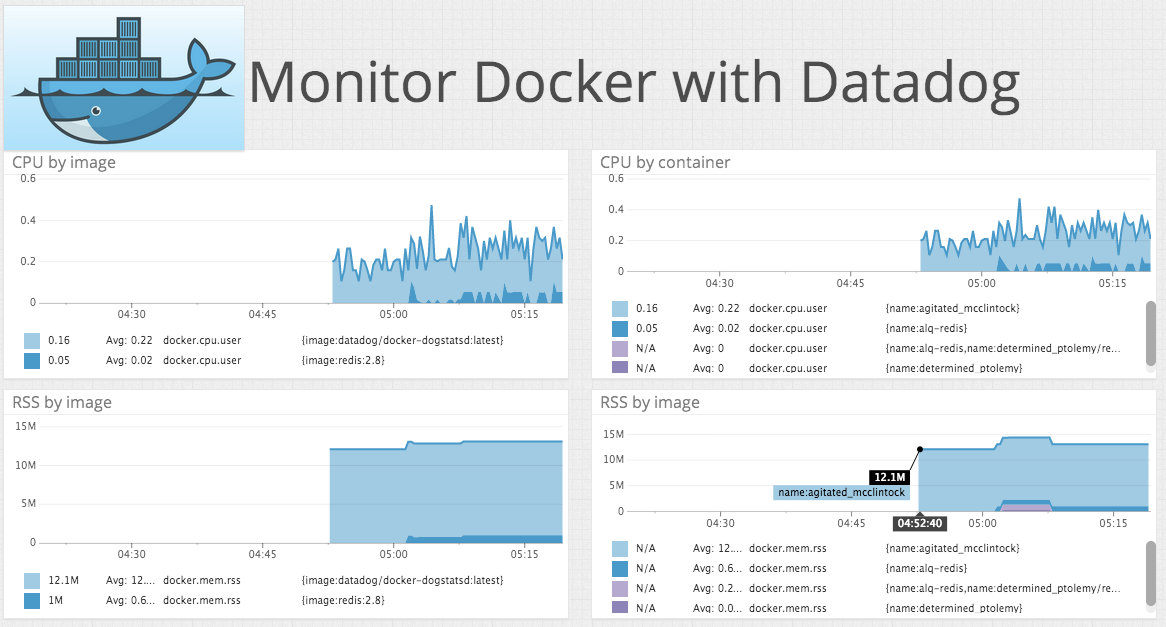
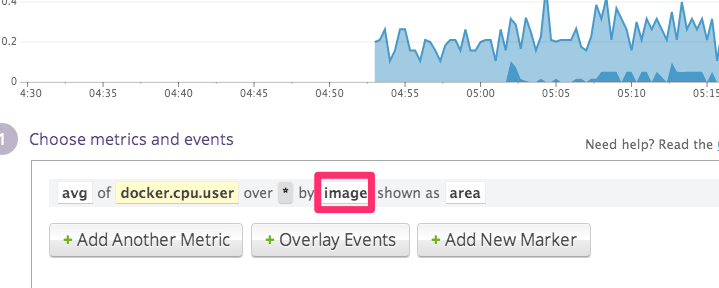
带标签的图像化指标在 Datadog 中,你可以基于一个或多个标签来定义显示在仪表盘和图上的指标。这允许你可以全局上追踪众多容器的特定指标。使用标签,可以很轻松地创建一个运行着指定镜像的所有容器的指标图。 在下面的例子中,我们根据镜像划分,显示 CPU 的使用量。
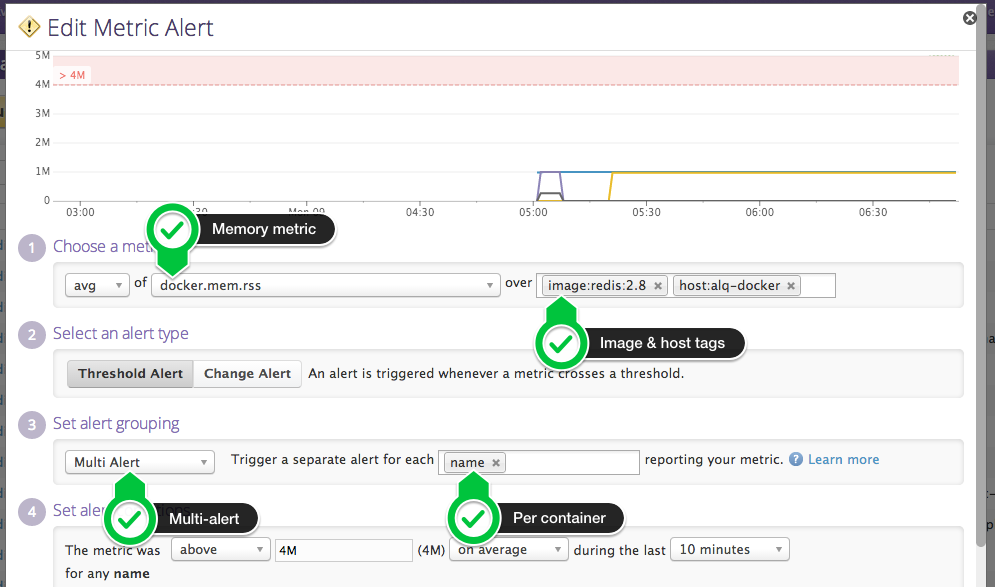
警报标签在定义跨容器集群的警报时非常有用。例如,你在运行着 Redis 的容器集群,而你想要当其中有一个容器发生内存溢出时接收到警报。 免去每个容器单独定义警报,你只需要在 docker.mem.re 指标上创建一个多重警报,这样 Datadog 就能在任何一个容器产生不正常行为时触发警报。 你也可以混合匹配多个标签来表达更复杂的条件。例如,你可以使用一个简单标签选择监控所有在 alq-docker 主机上运行 redis2.8 镜像的容器。
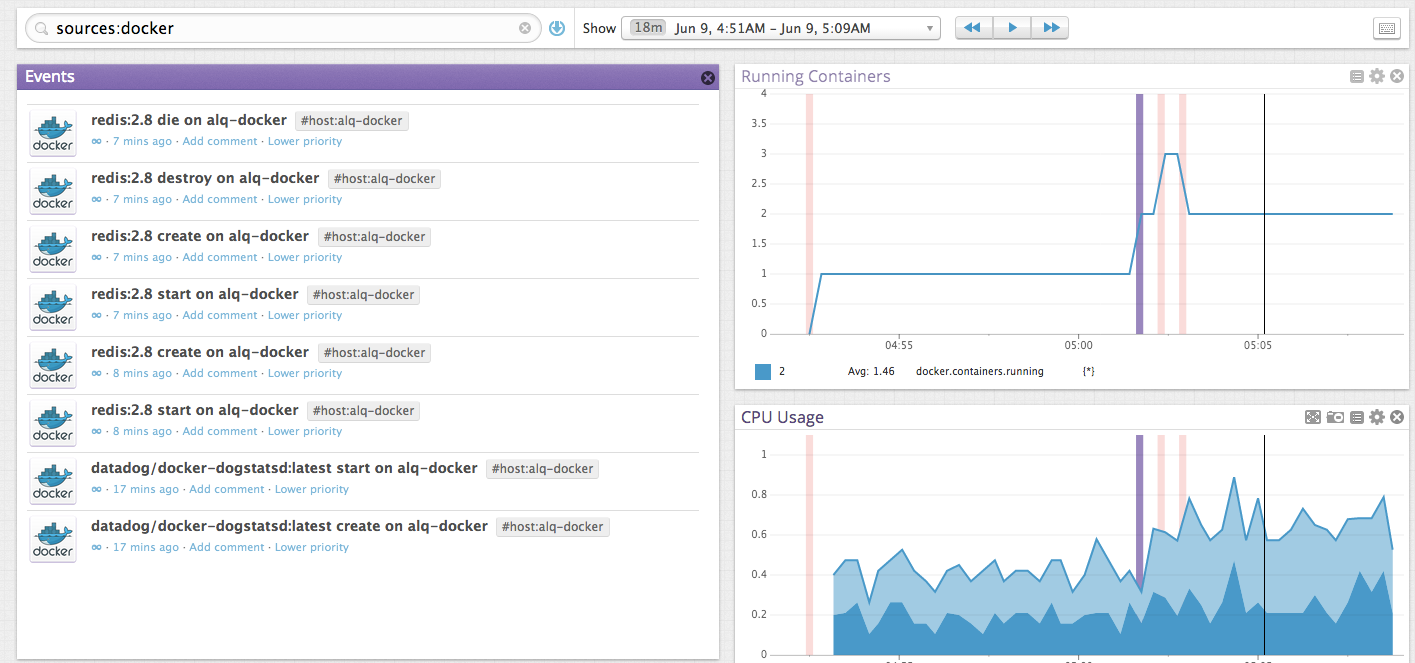
监控你的容器生命周期由于容器时被设计成与传统 OS 进程一般短期存活(或长期存活),那么代理可以用在整个生命周期中追踪特定的容器。 就如同在你的基础设施中其他有意义的事件,你可以使用 Events Stream (事件流)来搜索 Docker 容器创建/启动/停止/销毁事件。只需要使用 “source:docker" 作为 搜索过滤器 。
You can also apply the same search to any TimeBoard to visualize Docker container events in the context of Docker and non-Docker metrics. In the following example, we overlay continers starting and stopping over memory and CPU metrics.
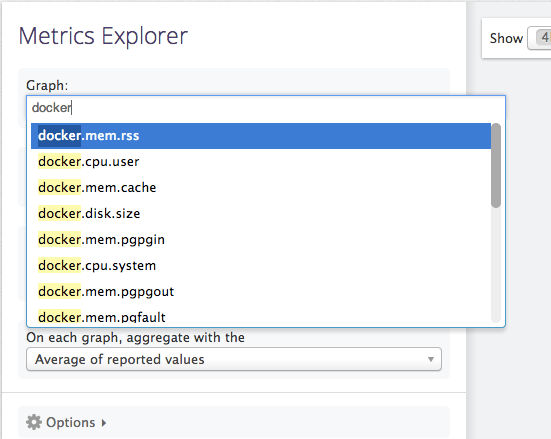
浏览 Docker 指标想浏览可用的 Docker 指标,你可以使用 Datadog 中的 Metrics Explorer(指标浏览器),在第一个下拉框中输入“ docker ” 。
你可以在 Docker's Runtime Metrics guide 中找到所有指标的详细描述。 如果你想获得更容易可视化的 Docker 指标、接收到相关警报,可以获取 Datadog 14 天免费试用 。在你安装完 Datadog 代理后,你马上可以获得 Docker 引擎、容器以及主机。 (责任编辑:IT) |