|
(原文地址:https://blog.goquxiao.com/posts/2015/02/17/ji-yu-zabbix-dockerkai-fa-de-jian-kong-xi-tong/) 背景团队所开发的持续监测网站/APP的产品,需要有一项监控功能,具体来说就是,对URL/域名进行周期性(小于1分钟)监测,并且能对异常事件进行实时告警。在最近这几个月,我一直将大部分时间和精力花在了设计开发这套系统上面,一共经历了两个大版本。下文就对这套监控系统进行介绍,分享给大家。 自己之前没有这类系统的开发设计经验,于是问了下周围同事。和同事讨论的结果是:既然现在人手不够(就我一个人),我之前也没开发过这类系统,时间又比较紧迫(领导给的排期是“越快越好”……),那么找一个已有的开源监控系统进行二次开发,应该是一个不错的选择。那么,选择哪种开源监控系统呢?根据同事以往的经验,可以考虑zabbix,自己也调研过一段时间zabbix,它的优点有如下几条:
另外,除了以上这样,还有一个比较重要的一个原因:团队中的同事之前也调研过zabbix。在人手不足、时间又紧的情况下,这一个因素的权重就显得相对较高。所以,最终选择了在zabbix基础上进行二次开发。 至于使用docker,是考虑到监控的对象,会因为用户的增长、以及用户的操作,有动态的变化。作为设计者,自然希望有一种机制,能够可编程地、动态地控制zabbix agent的数量。我们既不让某一个agent(具体应该是agent的端口)有过多的监控项,导致监控项无法在一个周期内完成数据采集;又不想有生成过多的agent,造成系统资源的浪费。目前势头正劲的docker,怎能不进入我的视野?社区活跃、文档完善、相对其他虚拟化技术又很轻,都成为了我选择docker的原因。 需求这个监控系统的设计目标是:希望能够提供秒级时间粒度的监控服务,实时监控用户网页的可用性指标,做到快速反馈。 具体的需求为:当用户在我们的产品中创建持续监测任务,对于用户输入的URL进行两种类型的监控,即HTTP返回码以及PING返回时间。当某一类监控的采样数据异常时——例如HTTP返回500、PING超时——就会在用户界面上返回告警事件,用以提醒用户;采样数据正常时,再返回告警事件的状态。 第一个版本架构第一个版本中,系统的设计特点为:
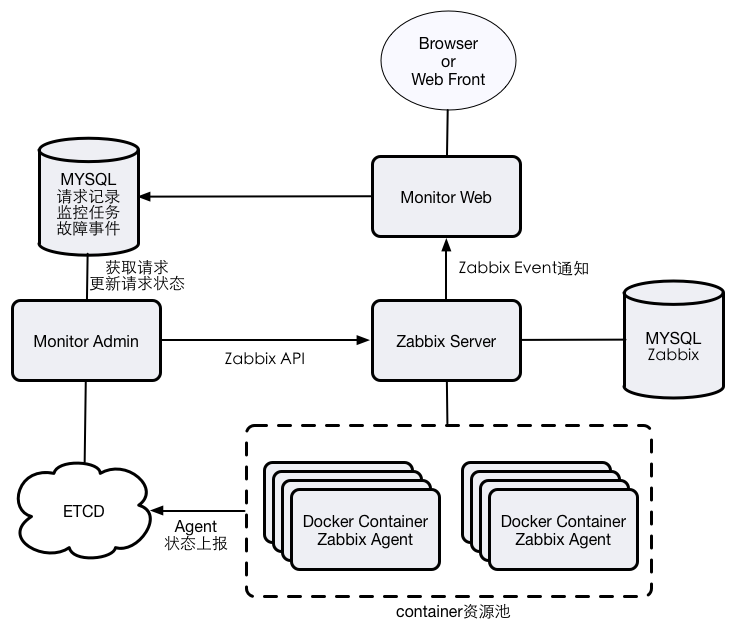
第一个版本的架构,如下图所示:
Monitor Web模块,作为后端的接口供前端来调用,主要提供监测任务添加、修改、删除,告警事件列表返回、告警事件删除等功能。 Monitor Syncer模块,用于定期检查每个监测任务对应的zabbix trigger的状态,根据trigger的状态,来生成告警事件以及告警恢复事件。 Zabbix Server和Zabbix Agent就构成了监控系统的核心服务。其中,一台物理机器中,包含了多个Docker container,每个container中运行这一个zabbix agent。 流程以创建监控任务为例,当前端发出创建监测任务时,Monitor Web模块接收到该请求,进行如下操作:
Monitor Syncer每隔一个周期(30s),扫描一遍目前所有监测任务,再从zabbix数据库中查找到对应trigger的状态。如果trigger状态为PROBLEM的超过了半数,那么该监控任务就处于了告警状态,最后再根据该任务目前是否处于告警状态,来决定是否需要添加告警事件;那么对应的,如果trigger状态均为OK,并且目前任务处于告警状态,那么则需要为告警事件添加对应的恢复状态。 这样,就完成了添加任务 -> 告警 -> 恢复的整个监控系统的典型流程。 性能对第一个版本进行了性能测试,得到了以下性能指标: (3台服务器,1台部署Zabbix Server,2台部署Docker + Zabbix Agent。服务器配置:Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz X 24,128G 内存,千兆网卡)
存在的不足因为开发时间所限,以及对于新技术的调研不够深入,第一个版本有不少不足,主要体现如下:
第二个版本升级点针对第一版本发现的问题,在设计上做了一些升级,具体升级点和设计上面的特点如下:
第二版的架构变成了这样:
上图中,Monitor Web一方面接收前端的请求,它收到请求做的唯一的事情就是将请求数据写入数据库进行持久化;另一方面,它还会接收来自Zabbix Server的事件请求,这里的事件表示trigger状态的改变。 Monitor Admin有两个职责:1)定期检测未完成的请求(添加/删除监控任务),拿到请求之后通过Zabbix API在对应的Zabbix Agent中添加/删除监控项(item + trigger);2)侦听ETCD中的key状态变化,进行相应地Zabbix Host创建/删除,以及监控项的迁移。 每当启动一个Docker container,就会将物理机的IDC、ETCD Server地址、Zabbix Server地址等参数传递至container,然后在内部启动zabbix_agentd,并且定期检查zabbix_agentd是否存活,如果存活的话,则生成一个唯一的key,向ETCD发起key创建/更新请求;如果不存活,则key会自然的过期。这样,Monitor Admin就通过ETCD得知了各个zabbix_agentd的健康状况,并且在内存中存储一份agent的拓扑结构。 启动了多个container,在Zabbix Server中就对应了多个Zabbix Host,如下图所示:
其他方面调优除了整体架构的升级,还在了许多方面(主要是Zabbix)进行了调优,比如: 尽量增加agent的超时时间 因为我们的监控采集项,都是需要对URL或者域名进行网络操作,这些操作往往都会比较耗时,而且这是正常的现象。因此,我们需要增加在Zabbix agent的采集超时,避免正常的网络操作还没完成,就被判断为超时,影响Server的数据获取。 ### Option: Timeout # Spend no more than Timeout seconds on processing # # Mandatory: no # Range: 1-30 # Default: # Timeout=3 Timeout=30 不要在采集脚本中加上超时 既然Zabbix agent中已经配置了采集超时时间,就不需要在采集脚本中添加超时了。一方面增加了维护成本,另一方面如果配置不当,还会造成Zabbix agent中的超时配置失效。(之前在脚本中使用了timeout命令,由于设置不正确,导致采集项总是不连续,调试了好久才查明原因。) 增加Zabbix Server的Poller实例 默认情况,用于接收Zabbix agent采集数据的Poller实例只有5个。对于周期在1分钟内、数量会达到千级别的采集项来说,Poller实例显然是不够的,需要增大实例数,充分利用好服务器资源。例如: ### Option: StartPollers # Number of pre-forked instances of pollers. # # Mandatory: no # Range: 0-1000 # Default: # StartPollers=5 StartPollers=100 利用好Zabbix trigger expression 如果只把trigger expression理解为“判断某个item value大于/小于某个阈值”,那就太低估Zabbix的trigger expression了,它其实可以支持很多复杂的逻辑。比如,为了防止网络抖动,需要当最近的连续两个采集项异常时,才改变trigger的状态,表达式可以写成:(假设item_key<0为异常)
{host:item_key.last(#1)}<0&{host:item_key.last(#2)}<0
再举个例子,同样是为了防止采集的服务不稳定,我们可以规定,当目前trigger的状态为PROBLEM,并且最近5分钟的采集数据均正常的时候,才可以将trigger状态改为OK,表达式可以这样写:
({TRIGGER.VALUE}=0&{host:item_key.last(#1)}<0&{host:item_key.last(#2)}<0) | ({TRIGGER.VALUE}=1&{host:item_key.min(5m)}<0)
具体可以参考Trigger expression 性能测试环境: 3台服务器,硬件参数与之前保持一致
性能指标:
部分性能指标的监测图如下:
Zabbix Server每秒处理监控项数目
Zabbix Server网卡入口流量
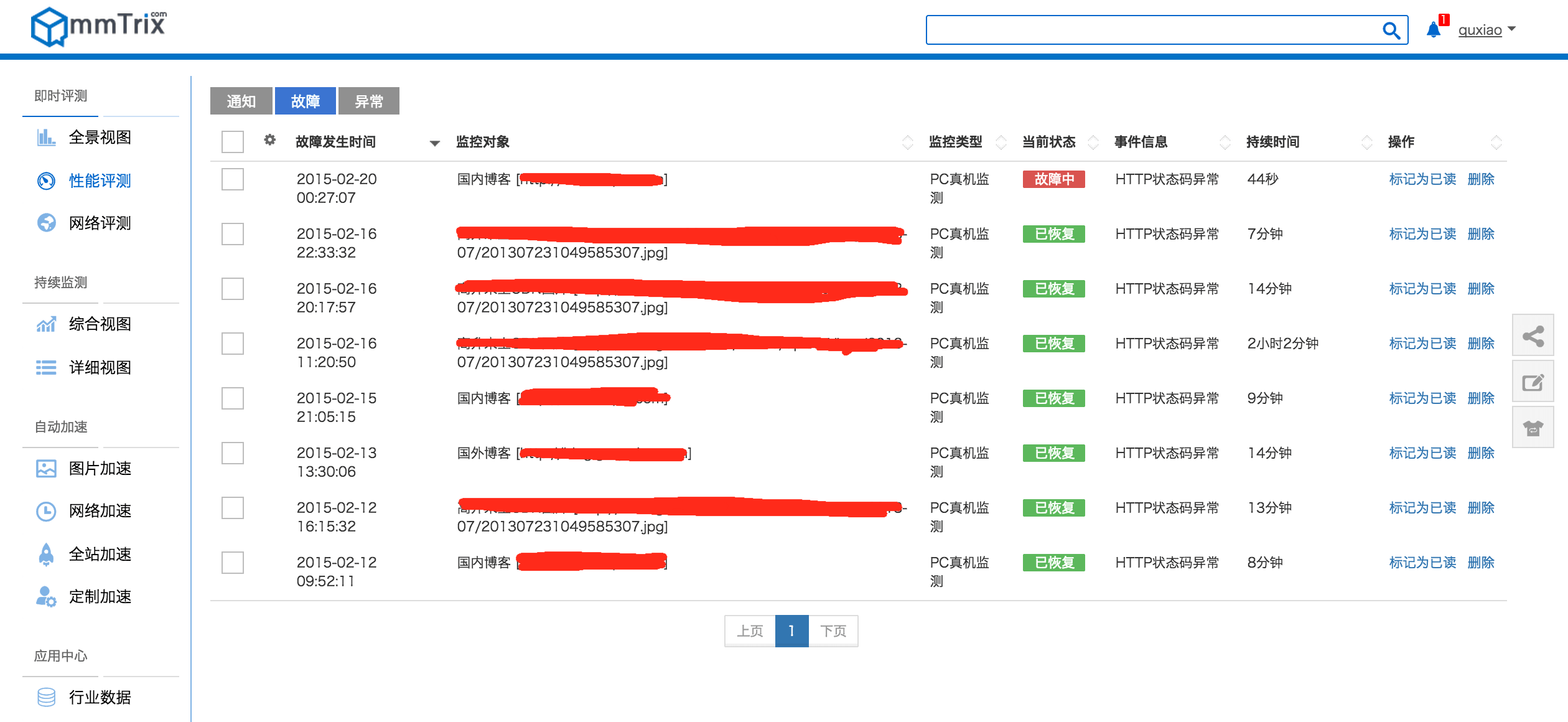
Zabbix Server网卡出口流量 可以看出,跟第一版相比,最大可采集的数据量是原来的近7倍,Zabbix Server的进出口流量有明显的提升,监控项的处理吞吐率也和采集项数量有了一致的提高,是原来的6.8倍,并且没有出现监控项在一个周期内无法采集到的情况(如果再增加监控项,则会不定期出现采样不连续的情况),性能提升还是比较明显的。 系统截屏故障事件列表
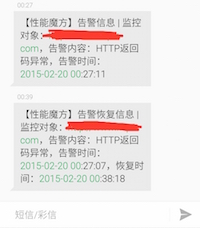
短信报警
总结本文从架构上介绍了如果基于Zabbix以及Docker,构建一个监控系统。 (广告时间,感兴趣的朋友可以登录我们的官网进行注册,使用我们的评测/监测/加速等服务,并且通过添加PC持续监测任务来对网站进行实时监控。) 当然,目前的版本仍然不够完美,目前“抗住”了,然后需要考虑“优化”,年后预计会有较大改动,架构上以及技术上,自己已经在考量中。 (又是广告时间,团队急需后端小伙伴,可以通过我们的官网了解到我们的产品,也过年了,年终奖也发了,感兴趣的、有想法的朋友,欢迎将简历发送至hr@mmtrix.com,谢谢!) (责任编辑:IT) |