|
Docker 在早期只有单机上的网络解决方案,在 1.19 版本引入了原生的 overlay 网络解决方案,但是它的性能损耗较大,可能无法适应一些生产环境的要求。除了Docker 提供的解决方案外,还有其它一些开源的解决方案。本文首先会简介各种已有的方案,然后根据公开分享的资料,总结一下部分企业在生产环境中对容器网络的选型和考量。
1. 现有的跨主机容器网络解决方案
1.1 Flannel容器网络
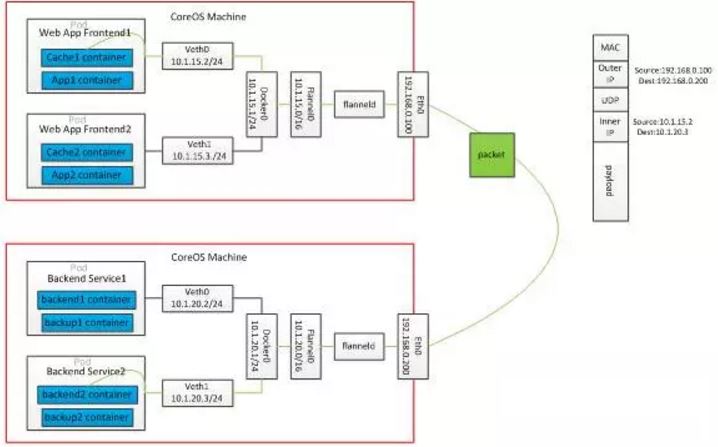
Flannel 是由 CoreOS 主导的解决方案。Flannel 为每一个主机的 Docker daemon 分配一个IP段,通过 etcd 维护一个跨主机的路由表,容器之间 IP 是可以互相连通的,当两个跨主机的容器要通信的时候,会在主机上修改数据包的 header,修改目的地址和源地址,经过路由表发送到目标主机后解包。封包的方式,可以支持udp、vxlan、host-gw等,但是如果一个容器要暴露服务,还是需要映射IP到主机侧的。
1.2 Calico 网络方案
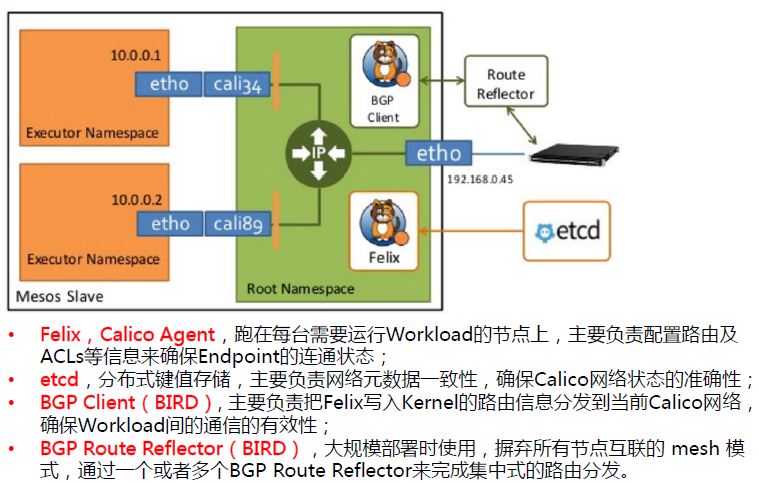
Calico 是个年轻的项目,基于BGP协议,完全通过三层路由实现。Calico 可以应用在虚机,物理机,容器环境中。在Calico运行的主机上可以看到大量由 linux 路由组成的路由表,这是calico通过自有组件动态生成和管理的。这种实现并没有使用隧道,没有NAT,导致没有性能的损耗,性能很好,从技术上来看是一种很优越的方案。这样做的好处在于,容器的IP可以直接对外部访问,可以直接分配到业务IP,而且如果网络设备支持BGP的话,可以用它实现大规模的容器网络。但BGP带给它的好处的同时也带给他的劣势,BGP协议在企业内部还很少被接受,企业网管不太愿意在跨网络的路由器上开启BGP协议。
1.3 总结
跨主机的容器网络解决方案不外乎三大类:
-
隧道方案:比如Flannel的 VxLan。特点是对底层的网络没有过高的要求,一般来说只要是三层可达就可以,只要是在一个三层可达网络里,就能构建出一个基于隧道的容器网络。问题也很明显,一个大家共识是随着节点规模的增长复杂度会提升,而且出了网络问题跟踪起来比较麻烦,大规模集群情况下这是需要考虑的一个点。
-
路由方案:路由技术从三层实现跨主机容器互通,没有NAT,效率比较高,和目前的网络能够融合在一起,每一个容器都可以像虚拟机一样分配一个业务的IP。但路由网络也有问题,路由网络对现有网络设备影响比较大,路由器的路由表应该有空间限制一般是两三万条。而容器的大部分应用场景是运行微服务,数量集很大。如果几万新的容器IP冲击到路由表里,导致下层的物理设备没办法承受;而且每一个容器都分配一个业务IP,业务IP消耗会很快。
-
VLAN:所有容器和物理机在同一个 VLAN 中。
1.4 一个网友的性能测试报告
来源:https://www.douban.com/note/530365327/
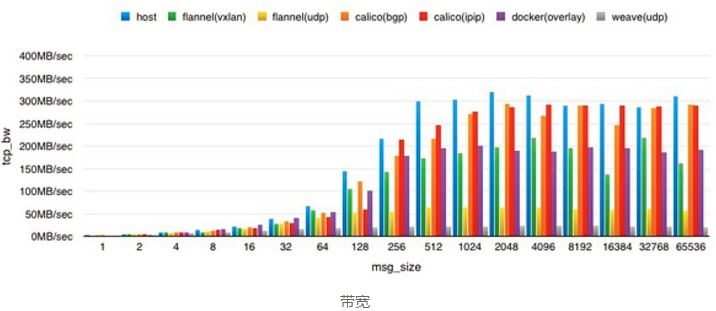
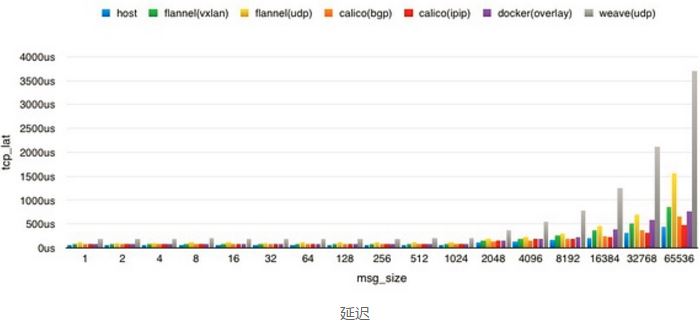
结论:
|
方案 |
结论 |
优势 |
劣势 |
|
weave(udp) |
真是惨,生产环境就别考虑了。看了下他们的架构,觉得即便是 fast-data-path 也没多大意义。 |
无 |
就是个渣渣,概念好毛用都没 |
|
calico |
calico 的 2 个方案都有不错的表现,其中 ipip 的方案在 big msg size 上表现更好,但蹊跷是在 128 字节的时候表现异常,多次测试如此。bgp 方案比较稳定,CPU 消耗并没有 ipip 的大,当然带宽表现也稍微差点。不过整体上来说,无论是 bgp 还是 ipip tunnel,calico 这套 overlay sdn 的解决方案成熟度和可用度都相当不错,为云上第一选择。 |
性能衰减少,可控性高,隔离性棒 |
操作起来还是比较复杂,比如对 iptables 的依赖什么的 |
|
flannel |
flannel 的 2 个方案表现也凑合,其中 vxlan 方案是因为没法开 udp offload 导致性能偏低,其他的测试报告来看,一旦让网卡自行解 udp 包拿到 mac 地址什么的,性能基本上可以达到无损,同时 cpu 占用率相当漂亮。udp 方案受限于 user space 的解包,仅仅比 weave(udp) 要好一点点。好的这一点就是在实现方面更加高效。 |
部署简单,性能还行,可以兼容老版本 docker 的启动分配行为,避免 launcher |
没法实现固定 IP 的容器漂移,没法多子网隔离,对上层设计依赖度高,没有 IPAM,对 docker 启动方法有绑定 |
|
docker 原生 overlay 方案 |
其实也是基于 vxlan 实现的。受限于 cloud 上不一定会开的网卡 udp offload,vxlan 方案的性能上限就是裸机的 55% 左右了。大体表现上与 flannel vxlan 方案几乎一致。 |
docker 原生,性能凑合 |
对内核要求高(>3.16),对 docker daemon 有依赖需求 ( consul / etcd ),本身驱动实现还是略差点,可以看到对 cpu 利用率和带宽比同样基于 vxlan 的 flannel 要差一些,虽然有 api 但对 network 以及多子网隔离局部交叉这种需求还是比较麻烦,IPAM 就是个渣 |
综上,云上能用 BGP 就果断上 calico bgp 方案,不能用 BGP 也可以考虑 calico ipip tunnel 方案,如果是 coreos 系又能开 udp offload,flannel 是不错的选择。Docker overlay network 还有很长一段路要走,weave 就不用考虑了。
2. 若干企业生产环境中的容器网络方案
2.1 PPTV Docker网络解决方案 - 基于 linux bridge
(0)PPTV 容器云架构

(1)网络需求
-
网络组人力不足以维护一个Overlay网络,Overlay网络出问题排查复杂,会出现失控的状态。
-
隧道技术影响性能,不能满足生产环境对网络性能的要求。
-
开启bgp对现有网络改动太大,无法接受。
-
运维组同学希望能通过网络桥接的方案解决容器网络。
(2)选中的方案
最终 PPTV 选中基于docker的bridge模式,将默认的docker bridge网桥替换为 linuxbridge,把 linuxbridge 网段的 ip 加入到容器里,实现容器与传统环境应用的互通。
-
首先会在该主机上添加一个linux bridge,把主机网卡,可以是物理机的,也可以是虚拟机的,把这个网卡加入bridge里面,bridge配上网卡原本的管理IP。
-
创建一个新的docker bridge网络,指定bridge子网,并将该网络的网桥绑定到上一步创建的网桥上。
docker network create --gateway10.199.45.200 --subnet 10.199.45.0/24 -o com.docker.network.bridge.name=br-oak--aux-address"DefaultGatewayIPv4=10.199.45.1" oak-net
-
容器启动时候,指定容器网络为第二步中创建的bridge网络,同时为容器指定一个该网络子网内的IP。容器启动后网络IP默认即可与外界互通。
(3)问题及解决方案
通过网桥的方式解决容器网络有两个问题:
-
容器跨主机漂移要求宿主机在同一个VLAN 中:linux bridge 只能添加跟 slavehost 同一个vlan的IP,也就是说容器IP必须要和宿主机在同一vlan下,这在一定程度上就限制了容器跨宿主机漂移的范围。不过这个问题在PPTV 的生产环境中天然不存在,因为我们的生产环境中,每个数据中心的主机都在一个很大的子网内,基本能满足容器在整个数据中心的任意节点下漂移。
-
跨主机的 IP 地址分配需要避免地址冲突:要让容器 IP 在不同的宿主机上漂移,宿主机的 docker 网络需要使用同一个CIDR,也就是各宿主机的容器使用同一个网段。而不同宿主机的使用同一个容器网段就会涉及到IPAM的问题,因为宿主机的docker daemon只知道他本机上的容器使用了哪些IP,而这些IP在其他宿主机上有没有被使用,是不知道的。在默认的docker bridge中,因为这些ip不会直接与外部通信,所以容器使用相同IP也不会有问题,但是当容器网络通过linux bridge打通以后,所有容器都是2层互通的,也就是会出现IP冲突的问题。为了解决上边提到的问题,实现全局的IP管控,我们开发了IP池管理平台,实现对容器IP的分配管理。
-
需要更新服务自动注册、自动发现:因为原先的方案是基于NAT的模式做的,而现在实现了独立IP的功能。我们需要将现有的平台与PPTV内部的DNS做自动化对接,每当有容器创建和生成时,都会自动对容器的IP做DNS解析。
-
负载均衡:PPTV的负载均衡基本都是通过LVS + nginx实现的,但对于后台的容器应用来说,每次扩容和缩容、或者创建新的应用,负载均衡的后端配置也是需要自动更新的。
2.2 宜信的容器网络解决方案 - 基于 Calico
(1)网络需求
-
让每个容器拥有自己的网络栈,特别是独立的 IP 地址
-
能够进行跨服务器的容器间通讯,同时不依赖特定的网络设备
-
有访问控制机制,不同应用之间互相隔离,有调用关系的能够通讯
(2)调研过程和最终的选择
调研了几个主流的网络模型:
-
Docker 原生的 Bridge 模型:NAT 机制导致无法使用容器 IP 进行跨服务器通讯(后来发现自定义网桥可以解决通讯问题,但是觉得方案比较复杂)
-
Docker 原生的 Host 模型:大家都使用和服务器相同的 IP,端口冲突问题很麻烦
-
Weave OVS 等基于隧道的模型:由于是基于隧道的技术,在用户态进行封包解包,性能折损比较大,同时出现问题时网络抓包调试会很蛋疼
-
Project Calico 是纯三层的 SDN 实现,它基于 BPG 协议和 Linux 自己的路由转发机制,不依赖特殊硬件,没有使用 NAT 或 Tunnel 等技术。能够方便的部署在物理服务器,虚拟机(如 OpenStack)或者容器环境下。同时它自带的基于 Iptables 的 ACL 管理组件非常灵活,能够满足比较复杂的安全隔离需求。
各种方案的限制:
(3)Calico 使用总结
-
Calico 的应用场景主要是IDC内部,推荐部署在二层网络上,这样所有路由器之间是互通的。这种场景是大二层的解决方案,所有服务器都在里面。但大二层主要的问题是弹性伸缩的问题。频繁开关机的时候,容器启停虽然不影响交换机,但容易产生广播风暴。网络规模太大的时候,一旦出现了这样的问题,整个网络都会有故障,这个问题还没有解决的特别好。
-
Calico作为一个纯二层的应用问题不大。我们可以把集群分成了很多网段,对外是三层网络的结构。集群内部分成多个自制域,比如一个机柜是一个自制域,之间通过交换路由的方式实现在三层容器到容器的互通。瓶颈在于容器的路由信息容量。所以说本质上它不是一个应对互联网规模的解决方案,但对宜信场景是够用的。
-
我们实施的时候遇到一些坑,比如容器在启动时没有网络、操作ETCD的时候BGP配置频繁加载,等等,最后我们多一一解决了。我们也发现了driver方案功能方面的弱点,现在还继续使用劫持API的方法。如果要在云上使用,如果支持BGP,直接可以用;如果不支持BGP可以用IPIP。现在英特尔的网卡支持两个协议,一个是GRE、一个是VxLAN。如果真的把它放在云上,我们可以考虑一下把VxLAN引进来,性能上的差别不是很大。
2.3 京东和魅族都是采用 OVS + VLAN 方案
根据 2016 北京容器大会 《魅族云容器化建设》 文档的一些总结:
(1)使用 OVS port 替代 OVS veth 可以带来较大的性能提升
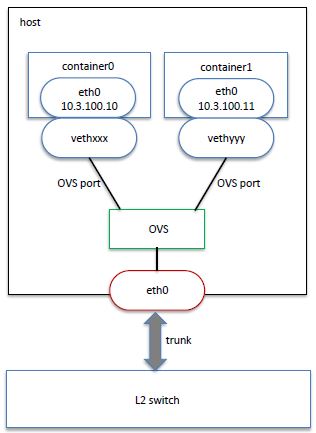 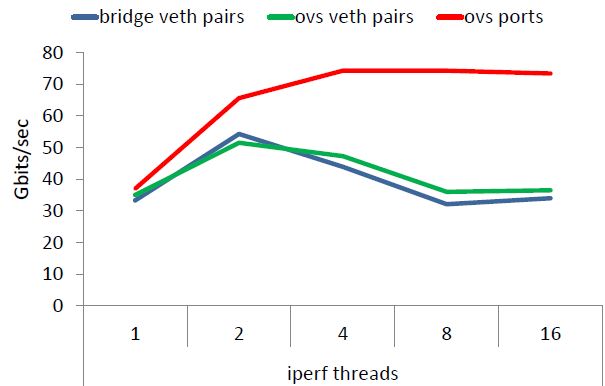
(2)使用 SR-IOV
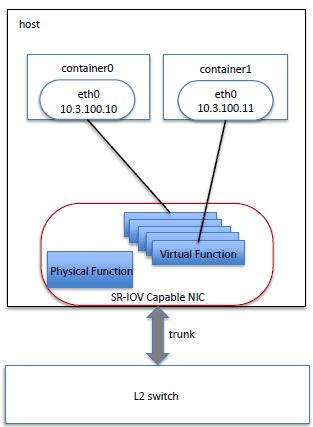 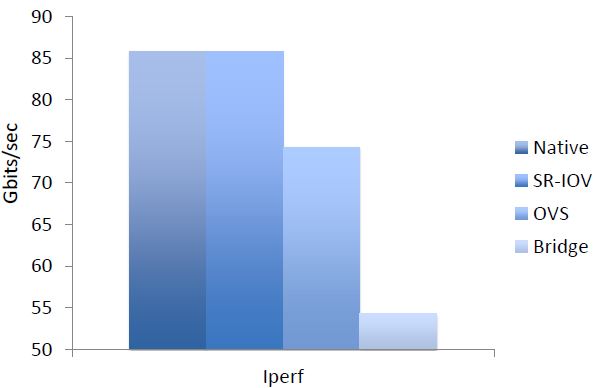
(3)使用 DPDK
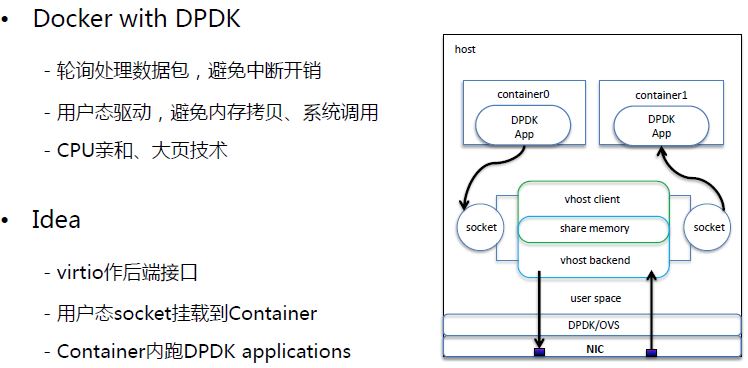
3. 小结
上面的几个生产环境中的网络解决方案,它们的目的都是为了把容器当作虚机用,因此都有共同的需求,比如:
-
每个容器有独立的 IP,这样运维就可以象通过 ssh 连接到虚机一样连接进容器
-
需要跨服务器之间的容器通信
-
安全性,包括访问控制和隔离性
-
性能保证和优化
-
对现有物理网络改动和影响较小
-
使用和调试都比较方便
要满足以上要求,可能 OVS/Linux-bridge + VLAN 方案应用的比较多,同时看起来 Calico 方案看起来前景不错。
参考链接:
(责任编辑:IT) |