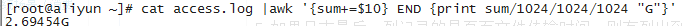|
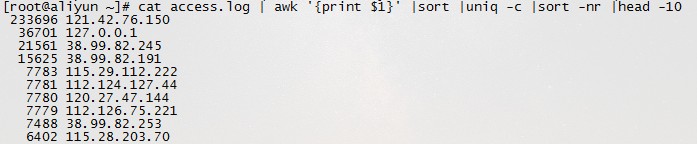
1.获得访问前10位的ip地址 cat access.log|awk '{print $1}'|sort|uniq -c|sort -nr|head -10
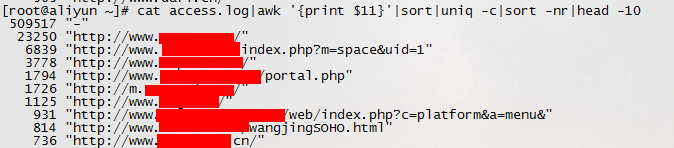
2.访问次数最多的文件或页面,取前10 cat access.log|awk '{print $11}'|sort|uniq -c|sort -nr|head -10
cat access.log|awk '{counts[$(11)]+=1}; END {for(url in counts) print counts[url], url}'
3.统计此日志文件中所有的流量 cat access.log |awk '{sum+=$10} END {print sum/1024/1024/1024 "G"}'
4.列出输出大于200000byte(约200kb)的exe文件以及对应文件发生次数 cat access.log |awk '($10 > 200000 && $7~/\.exe/){print $7}'|sort -n|uniq -c|sort -nr|head -100
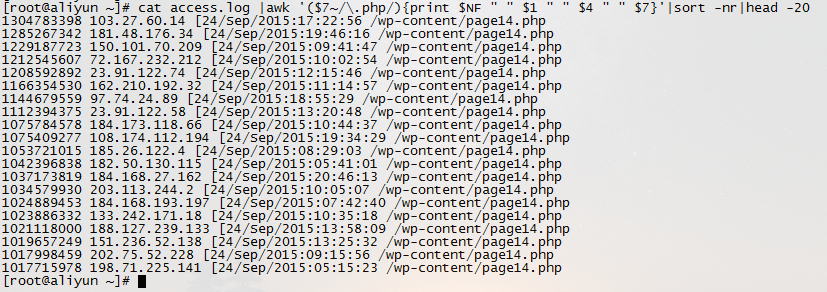
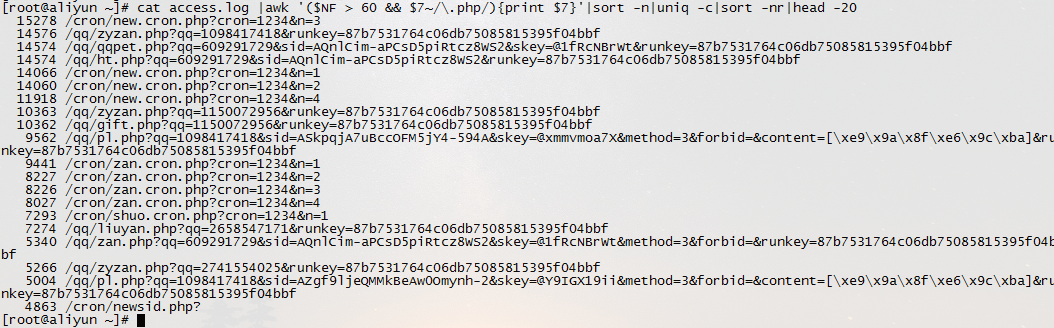
5.如果日志最后一列记录的是页面文件传输时间,则有列出到客户端最耗时的页面 cat access.log |awk '($7~/\.php/){print $NF " " $1 " " $4 " " $7}'|sort -nr|head -20
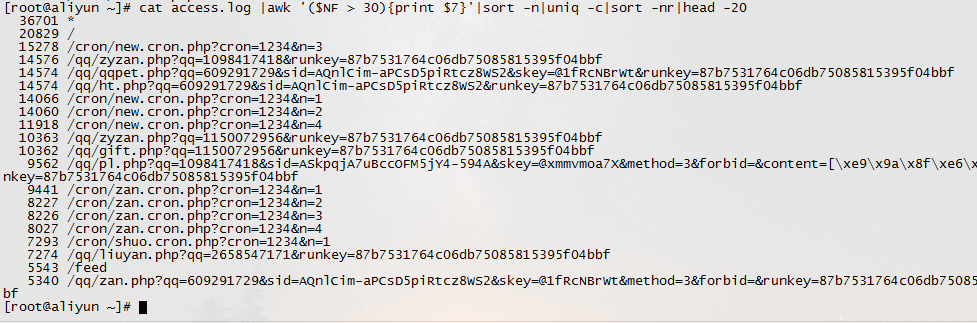
6.列出最最耗时的页面(超过60秒的)的以及对应页面发生次数 cat access.log |awk '($NF > 60 && $7~/\.php/){print $7}'|sort -n|uniq -c|sort -nr|head -20
7.列出传输时间超过 30 秒的文件 cat access.log |awk '($NF > 30){print $7}'|sort -n|uniq -c|sort -nr|head -20
8.统计404的连接 awk '($9 ~/404/)' access.log | awk '{print $9,$7}' | sort |uniq -c 结果太多就看一下前10 awk '($9 ~/404/)' access.log | awk '{print $9,$7}' | sort |uniq -c |sort -nr | head -10
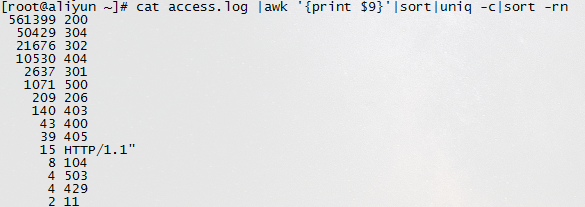
9. 统计http status. cat access.log |awk '{print $9}'|sort|uniq -c|sort -rn
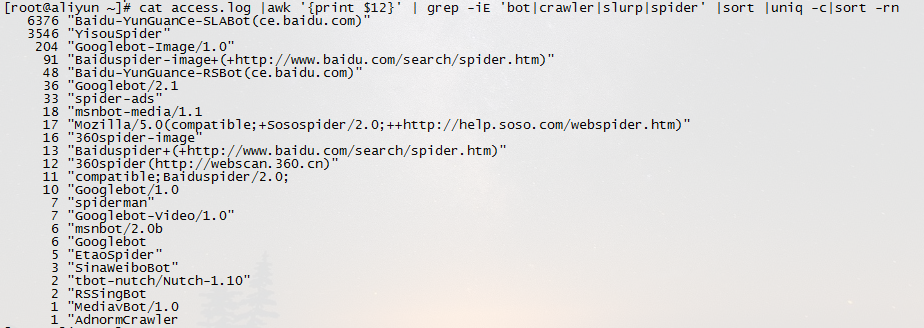
10.蜘蛛分析查看是哪些蜘蛛来访问过。 cat access.log |awk '{print $12}' | grep -iE 'bot|crawler|slurp|spider' |sort |uniq -c
查看正在来访的蜘蛛 /usr/sbin/tcpdump -i eth1 -l -s 0 -w - dst port 80 | strings | grep -i user-agent | grep -iE 'bot|crawler|slurp|spider' (责任编辑:IT) |