Nginx做cache 导致磁盘IO堵塞,这应该是个历史问题了。有些人可能流量小,遇不到;有些人,可能遇到了,上SSD去抗;还有些高帅富去改nginx源码了,使nginx的cache可以分布到多个盘里,不管怎么说我没见到他们把经验分享出来。有感于此,还是把自己的解决方法分享给需要的朋友,方法不漂亮,不过可以解决问题。
一:nginx做cache磁盘io堵塞的解决办法 a 背景
1 cache文件放在/dev/sdb这个盘里
2 网卡流量最高可以跑满1G
问题: 业务不能正常服务?
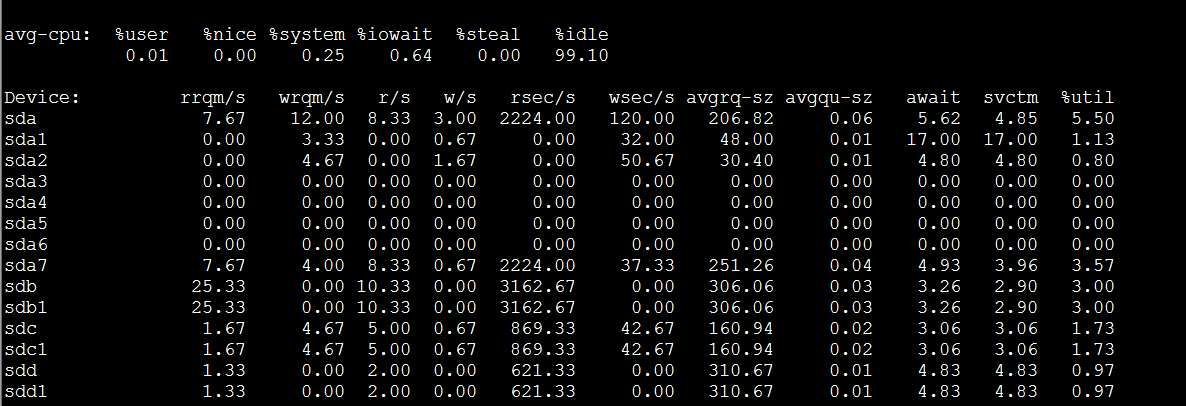
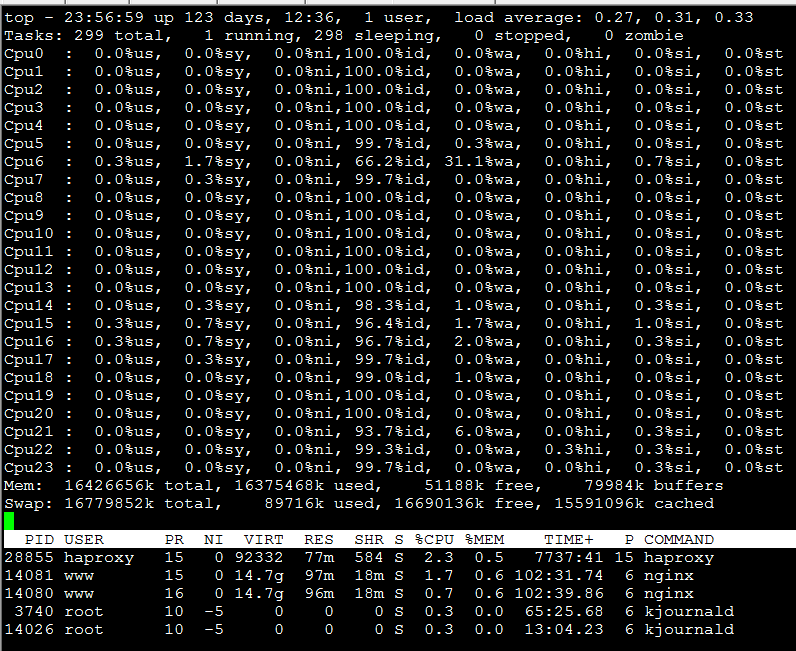
下面两张图说明一切(可以看到设备/dev/sdb磁盘利用率已经跑到100%,cpu iowait严重):


b 解决方法
分析过程:
原因-->网卡流量太大,导致磁盘IO太高,单磁盘抗不住1G的带宽读写
解决-->分散磁盘IO压力,将cache分布到多个磁盘
方案-->起多个nginx实例,一个nginx实例对应一个磁盘;haproxy uri算法将请求打到多个nginx实例上
以下为线上实例配置:
[root@budong ~]# cat /usr/local/haproxy/etc/haproxy.cfg
global
log 127.0.0.1 local0
maxconn 65535
chroot /usr/local/haproxy
user haproxy
group haproxy
daemon
nbproc 1
pidfile /var/run/haproxy.pid
defaults
log 127.0.0.1 local3
mode http
option httplog
option httpclose
option dontlognull
option forwardfor
option redispatch
retries 2
maxconn 2000
balance uri
contimeout 5000
clitimeout 50000
srvtimeout 50000
listen admin_stat
bind *:8000
stats refresh 30s
stats uri /haproxy
stats auth admin:admin
listen down_proxy
bind *:80
option httpchk HEAD / HTTP/1.0
server web1 192.168.1.162:8081 check inter 6000 rise 2 fall 1
server web2 192.168.1.162:8082 check inter 6000 rise 2 fall 1
server web3 192.168.1.162:8083 check inter 6000 rise 2 fall 1
server web4 192.168.1.162:8084 check inter 6000 rise 2 fall 1
server web5 192.168.1.162:8085 check inter 6000 rise 2 fall 1
[root@budong ~]# netstat -tlunp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:8000 0.0.0.0:* LISTEN 28855/haproxy
tcp 0 0 192.168.1.162:5666 0.0.0.0:* LISTEN 18767/nrpe
tcp 0 0 127.0.0.1:199 0.0.0.0:* LISTEN 4300/snmpd
tcp 0 0 0.0.0.0:2222 0.0.0.0:* LISTEN 4319/sshd
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 28855/haproxy
tcp 0 0 0.0.0.0:8081 0.0.0.0:* LISTEN 14077/nginx
tcp 0 0 0.0.0.0:8082 0.0.0.0:* LISTEN 14077/nginx
tcp 0 0 0.0.0.0:8083 0.0.0.0:* LISTEN 14077/nginx
tcp 0 0 0.0.0.0:8084 0.0.0.0:* LISTEN 14077/nginx
tcp 0 0 0.0.0.0:8085 0.0.0.0:* LISTEN 14077/nginx
udp 0 0 0.0.0.0:161 0.0.0.0:* 4300/snmpd
udp 0 0 0.0.0.0:36678 0.0.0.0:* 28855/haproxy
[root@budong ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 30G 6.9G 21G 25% /
/dev/sda6 9.7G 151M 9.1G 2% /tmp
/dev/sda3 30G 6.5G 22G 24% /usr
/dev/sda2 30G 9.9G 18G 36% /var
tmpfs 15G 0 15G 0% /dev/shm
/dev/sda7 160G 104G 49G 69% /mnt/cache1
/dev/sdb1 275G 201G 61G 77% /mnt/cache2
/dev/sdc1 275G 202G 59G 78% /mnt/cache3
/dev/sdd1 275G 207G 54G 80% /mnt/cache4
/dev/sde1 1.8T 202G 1.6T 12% /mnt/cache5
c 问题解决
二:是时候结束了
自言自语:
这个问题当初困惑了我有两周的时间,那时也是年少无知,想当然认为nginx配置好了,就应该是正常的,既然没有考虑磁盘能不能抗的住,可见自己的思维太有局限性了。木桶短板理论用在运维比较合适,很多时间我们都需要清楚的知道系统的短板在哪里,只有知己知彼,才能保证系统稳定运行。当然,nginx和专业的cache软件相比,优势不大,做cache还是用专业的软件,过几天将会讲解下ATS这个功能强大的cache软件。今天这是我写的第四篇博客了,感觉大脑真的要混沌了。哈哈,赶紧洗洗睡吧,走袅了。
(责任编辑:IT) |