|
本来想继续顺着数据包的处理流程分析upcall调用的,但是发现在分析upcall调用时必须先了解linux中内核和用户空间通信接口Netlink机制,所以就一直耽搁了对upcall的分析。如果对Open vSwitch有些了解的话,你会发现其实Open vSwitch是在linux系统上运行的,因为Open vSwitch中有很多的机制,模块等都是直接调用linux内核的。比如:现在要分析的RCU锁机制、upcall调用、以及一些结构体的定义都是直接从linux内核中获取的。所以如果你在查看源代码的一些结构(或者模块,机制性代码)时,发现在Open vSwitch中没有定义(我用的是Source Insight来查看和分析源码,可以很好的查看是否定义过),那么很可能就是Open vSwitch包含了linux头文件引用了linux内核的一些定义。 RCU是linux的新型锁机制(RCU是在linux 2.6内核版本中开始正式使用的),本来一直纠结要不要用篇blog来说下这个锁机制。因为在Open vSwitch中有很多的地方用到了RCU锁,我开始分析的时候都是用一种锁机制一笔带过(可以看下《Open vSwitch(OvS)源代码分析之数据结构》里面有很多地方都用到了RCU锁机制)。后来发现有很多地方还用到了该锁机制的链表插入和删除操作,而且后面分析的代码中也有RCU的出现,所以就稍微的说下这个锁机制的一些特性和操作。 RCU运行原理
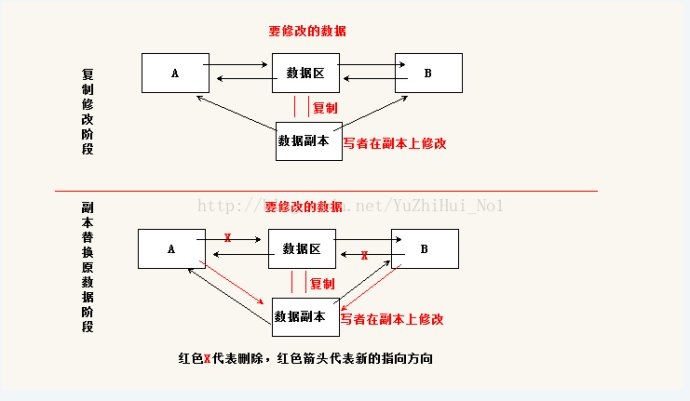
我们先来回忆下读写锁(rwlock)运行机制,这样可以分析RCU的时候可以对照着分析。读写锁分为读锁(也称共享锁),写锁(也称排他锁,或者独占锁)。分情况来分析下读写锁: 第二、要操作的数据区上了写锁;则不管是什么请求都必须等待数据区的写锁释放掉后才能上锁访问。 同理来分析下RCU锁机制:RCU是read copy udate的缩写,按照单词意思就知道这是一种针对数据的读、复制、修改的保护锁机制。锁机制原理: 第一、写数据的时候,不需要像读写锁那样等待所有锁的释放。而是会拷贝一份数据区的副本,然后在副本中修改,等待修改完后。用这个副本替换原来的数据区, 替换的时候就要像读写锁中上写锁那样,等到原数据区上所有访问者都退出后,才进行数据的替换;根据这种特性可以推断出,用RCU锁可以有多个写者,拷贝了 多份数据区数据,修改后各个写着陆续的替换掉原数据区内容。 第二、读数据的时候,不需要上任何锁,也几乎不需要什么等待(读写锁中如果数据区有写锁则要等待)就可以直接访问数据。为什么说几乎不需要等待呢?因为写数据中替换原数据时,只要修改个指针就可以,消耗的时间可以说几乎不算,所以说读数据不需要其他额外开销。 总结下RCU锁机制特性,允许多个读者和多个写者同时访问共享数据区的内容。而且这种锁对多读少写的数据来说是非常高效的,可以让CPU减少些额外的开 销。如果写得操作多了的话,这种机制就没读写锁那么好了。因为RCU写数据开销还是很大的,要拷贝数据,然后还要修改,最后还要等待替换。其实这个机制就 好比我们在一台共享服务器上放了个文件,有很多个人一起使用。如果你只是看看这个文件内容,那么直接在服务器上cat查看就可以。但如果你要修改该文件, 那么你不能直接在服务器上修改,因为你这样操作会影响到将要看这个文件或者写这个文件的人。所以你只能先拷贝到自己本机上修改,当最后确认保证正确时,然 后就替换掉服务器上的原数据。 RCU写者工作图示下面看下RCU机制下修改数据(以链表为例)。
根据上面的图会发现其实替换的时候只要修改下指针就可以,原数据区内容在被替换后,默认会被垃圾回收机制回收掉。 Linux内核RCU机制API了解了RCU的这些机制原理,下面来看下linux内核中常使用的一些和RCU锁有关的操作。注意,本blog并不会过多的去深究RCU最底层的实现机制,因为分享RCU工作机制的目的只是为了更好的了解Open vSwitch中使用到的那部分代码的理解,而不是为了分析linux内核源代码,不要本末倒置。如果遇到个知识点就拼命的深挖,那么你看一份源代码估计得几个月。
看到这里有人可能会觉得和上面有矛盾,不是说好的读者不需要锁吗?其实这不是和上读写锁的那种上锁,这仅仅只是标识了临界区的开始位置。表明在临界区内不能阻塞和休眠,也不能让写者进行数据的替换(其实这功能远不止这些)。rcu _read_unlock()则是和上面rcu_read_lock()对应的,用来界定一个临界区(就是要用锁保护起来的数据区)。
当该函数被一个CPU调用时(一般是有写者替换数据时调用),而其他的CPU都在RCU保护的临界区读数据,那么synchronize_rcu()将会 保证阻塞写者,直到所有其它读数据的CPU都退出临界区时,才中止阻塞,让写着开始替换数据。该函数作用就是保证在替换数据前,所有读数据的CPU能够安 全的退出临界区。同样,还有个call_rcu()函数功能也是类似的。如果call_rcu()被一个CPU调用,而其他的CPU都在RCU保护的临界 区内读数据,相应的RCU回调的调用将被推迟到其他读临界区数据的CPU全部安全退出后才执行(可以看linux内核源文件的注释,在 Rcupdate.h文件中rcu_read_look()函数前面的注释)。
获取在一个RCU保护的指针,指向RCU读端临界区。他的指针以后可能会被安全地解除引用。说到底就是一个RCU保护指针。
往RCU保护的数据结构中添加一个数据节点进去。这个和一般的往链表中增加一个节点操作是类似的,唯一不同的是多了这条代 码:rcu_assign_pointer(prev->next, new); 代码大概含义:分配指向一个新初始化的结构指针,将由RCU读端临界区被解除引用,返回指定的值。(说实话我也不太懂这个注释是什么意思)大概的解释下: 就是让插入点的前一个节点的next指向新增加的new节点,为什么要单独用一条这个语句来实现,而不是用 prev->next = new;直接实现呢?这是因为prev->next本来是指向其他值得,有可能有CPU通过prev->next去访问其他RCU保护的数据 了,所以如果你要插入一个RCU保护的数据结构中必要要调用这个语句,它里面会帮你处理好一些细节(比如有其他CPU使用后面的数据,直接使用 prev->next可能会使读数据的CPU断开,产生问题),并且让刚加入的新节点也受到RCU的保护。这类的插入有很多,比如从头部插入,从尾 部插入等,实现都差不多,这里不一一细讲。
这是个遍历RCU链表的操作,和一般的链表遍历差不多。不同点就是必须要进入RCU保护的CPU(即:调用了rcu_read_lock()函数的 CPU)才能调用这个操作,可以和其他CPU共同遍历这个RCU链表。以此相同的还有其他变相的遍历及哈希链表的遍历,不细讲。
如果在Open vSwitch源代码分析中发现了有关RCU的分析和这里的矛盾,可以以这里为准,当然我也会校对下。 (责任编辑:IT) |