-

二、Ubuntu14.04下安装Hadoop2.4.0 (伪分布模式)
日期:在Ubuntu14.04下安装Hadoop2.4.0(单机模式)基础上配置 一、配置core-site.xml /usr/local/hadoop/etc/hadoop/core-site.xml 包含了hadoop启动时的配置信息。 编辑器中打开此文件 sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml 在该文件的configu...
-

ubuntu + hadoop2.5.2分布式环境配置
日期:我之前有详细写过hadoop-0.20.203.0rc1版本的环境搭建 hadoop学习笔记环境搭建 http://www.cnblogs.com/huligong1234/p/3533382.html 本篇部分细节就不多说。 一、基础环境准备 系统:(VirtualBox) ubuntu-12.04.2-desktop-i386.iso hadoop版本:hadoop-2.5....
-

LVS+Keepalived实现高可用负载均衡分发
日期:一、概念理解 负载均衡 集群即将相同服务部署在多台服务器上构成一个集群整体对外提供服务。在应用中,内容服务器之前总会有一台负载均衡服务器,负载均衡器的任务就是作为web服务器的流量入口,将客户端的请求分发到后端集群真实服务器,实现客户端到服务端...
-
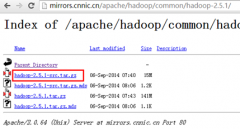
CentOS 6.4 编译 Hadoop 2.5.1
日期:1 前提准备 建议关闭编译机器上的防火墙与SELinux。 需要保证编译机器可以访问互联网。 卸载机器上的OpenJDK,并安装上64位的Oracle JDK。此处选用JDK7。 注意:经过实践,直到Hadoop 2.6.3使用JDK8进行编译依然存在出现各种问题。理论上应该可以解决,可是...
-
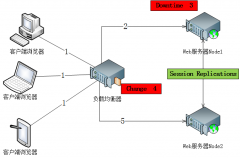
Apache httpd和JBoss构建高可用集群环境
日期:1、 前言 集群是指把不同的服务器集中在一起,组成一个服务器集合,这个集合给客户端提供一个虚拟的平台,使客户端在不知道服务器集合结构的情况下对这一服务器集合进行部署应用、获取服务等操作。集群是企业应用的主要特点,它可以提供: 高扩展性:可以根...
-
haproxy部署脚本
日期:最近为了测试haproxy的负载均衡,打算搭建几台haproxy测试机,但我又懒想直接用脚本搭建起就可以使用,以后要测试的时候,也可以直接就用脚本搞定.下面来看脚本吧. cat /root/soft_shell/haproxy_install.sh #!/bin/bash #install haproxy #20160224 by rocdk890...
-
Hadoop CDH5 Impala部署
日期:Cloudera发布了实时查询开源项目Impala!多款产品实测表明,比原来基于MapReduce的Hive SQL查询速度提升3~90倍。Impala是Google Dremel的模仿,但在SQL功能上青出于蓝胜于蓝。 CDH5 Impala 安装 1impala由四部分组成: impalad - Impala的守护进程. 计划执...
-
Hadoop CDH5 Spark部署
日期:Spark是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速,Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分...
-
Nginx/LVS/HAProxy负载均衡软件比较分析
日期:一般对负载均衡的使用是随着网站规模的提升根据不同的阶段来使用不同的技术。具体的应用需求还得具体分析,如果是中小型的Web应用,比如日 PV小于1000万,用Nginx就完全可以了;如果机器不少,可以用DNS轮询,LVS所耗费的机器还是比较多的;大型网站或重要的...
-
Nginx、LVS、HAProxy负载均衡软件的优缺点
日期:Nginx/LVS/HAProxy是目前使用最广泛的三种负载均衡软件,本人都在多个项目中实施过,参考了一些资料,结合自己的一些使用经验,总结一下。 一般对负载均衡的使用是随着网站规模的提升根据不同的阶段来使用不同的技术。具体的应用需求还得具体分析,如果是中小...