-

CentOS7下安装MySQL5.7安装与配置(YUM)
日期:安装环境:CentOS7 64位 MINI版,安装MySQL5.7 1、配置YUM源 在MySQL官网中下载YUM源rpm安装包:http://dev.mysql.com/downloads/repo/yum/ # 下载mysql源安装包shell wget http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm# 安装mysql...
-

CentOS下查看修改mysql编码方式
日期:MySQL的默认编码是Latin1,不支持中文,要支持中文需要把数据库的默认编码修改为gbk或者utf8。1、需要以root用户身份登陆才可以查看数据库编码方式(以root用户身份登陆的命令为:mysql-u root p,之后两次输入root用户的密码),查看数据库的编码方式命令为:sho...
-

怎样将 MySQL 迁移到 MariaDB 上
日期:自从甲骨文收购 MySQL 后,由于甲骨文对 MySQL 的开发和维护更多倾向于闭门的立场,很多 MySQL 的开发者和用户放弃了它。在社区驱动下,促使更多人移到 MySQL 的另一个叫 MariaDB 的分支,在原有 MySQL 开发人员的带领下,MariaDB 的开发遵循开源的理念,并...
-
linux环境下mysql 大小写敏感解决办法
日期:1、Linux下MySQL安装完后是默认:区分表名的大小写,不区分列名的大小写; 2、用root帐号登录后,在/etc/my.cnf中的[mysqld]后添加添加lower_case_table_names=1,重启MYSQL服务,这时已设置成功:不区分表名的大小写; lower_case_table_names参数详解: lo...
-
mysql 存储过程
日期:一、存储过程介绍 我们常用的操作数据库语言SQL语句在执行的时候需要要 先编译 , 然后执行 ,而存储过程(Stored Procedure)是一组为了完成特定功能的SQL语句集, 经编译后存储在数据库中 ,用户通过指定存储过程的名字并给定参数(如果该存储过程带有参数...
-
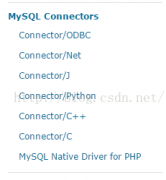
Ensemble(Cache)通过ODBC连接Mysql数据库并调用其存储过程
日期:有同事问到如何用cach数据库连到MySQL数据,并且调用Mysql数据库中的存储过程,开始认为mysql不可能为m语言单独写驱动所以不能调用存储过程。 在mysql官网可以看到mysql提供了以下几种方式连接它,见下图. (ODBC,NET,JDBC,Python,C++,C,PHP) 确实没有M语言的...
-
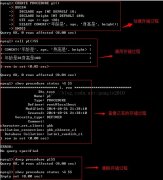
初识MySQL存储过程
日期:存储过程(Stored Procedure)是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给定参数(如果该存储过程带有参数)来调用执行它。 MySQL 存储过程是从MySQL 5.0开始增加的新功能。大大提高数据库的处理速度,同时...
-
mysql 储存过程的一些问题
日期:DELIMITER // drop procedure if exists queryMonthData; create procedure queryMonthData(IN time varchar(20)) begin select * from bsmu_powerandconfig_info where SaveTime like concat(time, %) order by SaveTime desc limit 1; select * from bsmu_p...
-
Spring mvc调用mysql储存过程
日期:mysql use modbus; Database changed mysql DELIMITER $ mysql drop procedure if exists p4; - create procedure p4() - begin - select user_name from user_info where indexflag = 0000000001; - end; Service断 @Transactional public ListObject getBsm...
-
mysql 存储过程实现历史报警信息去重(只粘贴代码,不解释了)
日期:BEGIN DECLARE f1, f2, f3, f4, f5 ,f6 INT; DECLARE Done INT DEFAULT 0; DECLARE f11, f12, f13, f14, f15 ,f16 INT; DECLARE result int DEFAULT 0; DECLARE temp, temp1, temp2, temp3, temp4, temp5, temp6 int DEFAULT 0; DECLARE record varchar(1000...