-
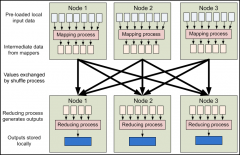
MapReduce数据流
日期:Hadoop的核心组件在一起工作时如下图所示: 图 4.4 高层 MapReduce 工作流水线 MapReduce 的输入一般来自 HDFS 中的文件,这些文件分布存储在集群内的节点上。运行一个 MapReduce 程序会在集群的许多节点甚至所有节点上运行 mapping 任务,每一个 mapping 任...
-
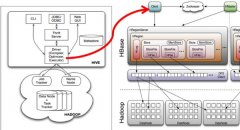
Hadoop Hive与Hbase整合+thrift
日期:1. 简介 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapRe...
-

海量数据处理算法―Bloom Filter
日期:1. Bloom-Filter算法简介 Bloom-Filter,即布隆过滤器,1970年由Bloom中提出。它可以用于检索一个元素是否在一个集合中。 Bloom Filter(BF)是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。它是...
-

Storm集群安装详解
日期:storm有两种操作模式: 本地模式和远程模式。 本地模式:你可以在你的本地机器上开发测试你的topology, 一切都在你的本地机器上模拟出来; 远端模式:你提交的topology会在一个集群的机器上执行。 本文以Twitter Storm 官方Wiki 为基础,详细描述如何快速搭建...
-
你的数据根本不够大,别老扯什么Hadoop了
日期:本文原名 Dont use Hadoop when your data isnt that big ,出自有着多年从业经验的数据科学家 Chris Stucchio ,纽约大学柯朗研究所博士后,搞过高频交易平台,当过创业公司的CTO,更习惯称自己为统计学者。对了,他现在自己创业,提供数据分析、推荐优化咨...
-
Hive深入浅出
日期:1. Hive是什么 1) Hive是什么? 这里引用 Hive wiki 上的介绍: Hive is a data warehouse infrastructure built on top of Hadoop. It provides tools to enable easy data ETL, a mechanism to put structures on the data, and the capability to queryin...
-
数据分析≠Hadoop+NoSQL,不妨先看完善现有技术的10条捷径(分享) .
日期:本文原名Dont use Hadoop when your data isnt that big ,出自有着多年从业经验的数据科学家Chris Stucchio,纽约大学柯朗研究所博士后,搞过高频交易平台,当过创业公司的CTO,更习惯称自己为统计学者。对了,他现在自己创业,提供数据分析、推荐优化咨询服...
-
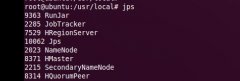
hbase安装配置(整合到hadoop)
日期:如果想详细了解hbase的安装:http://abloz.com/hbase/book.html 和官网http://hbase.apache.org/ 1. 快速单击安装 在单机安装Hbase的方法。会引导你通过shell创建一个表,插入一行,然后删除它,最后停止Hbase。只要10分钟就可以完成以下的操作。 1.1下载解...
-
Hadoop实战实例
日期:Hadoop实战实例 Hadoop是GoogleMapReduce的一个Java实现。MapReduce是一种简化的分布式编程模式,让程序自动分布到一个由普通机器组成的超大集群上并发执行。就如同java程序员可以不考虑内存泄露一样,MapReduce的run-time系统会解决输入数据的分布细节,跨越...
-
Hadoop简介
日期:Hadoop的概要介绍 Hadoop,是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。 简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。该平台...