-

Maven进行Mahout编程,使其兼容Hadoop2.2.0环境运行 (转)
日期:http://blog.csdn.net/u010967382/article/details/39209329 http://blog.csdn.net/fansy1990/article/details/23261633 先编译mahout源码让其支持hadoop2 再把本地仓储repository里的jar包替换成编译后的jar包 修改后的源码包(http://download.csdn.net/de...
-

hadoop Mahout中相似度计算方法介绍(转)
日期:相似距离(距离越小值越大) 优点 缺点 取值范围 PearsonCorrelation 类似于计算两个矩阵的协方差 不受用户评分偏高 或者偏低习惯影响的影响 1. 如果两个item相似个数小于2时 无法计算相似距离. [可以使用item相似个数门限来解决.] 没有考虑两个用户之间的交集...
-
mahout基于Hadoop的CF代码分析(转)
日期:来自:http://www.codesky.net/article/201206/171862.html mahout的taste框架是协同过滤算法的实现。它支持DataModel,如文件、数据库、NoSQL存储等,也支持Hadoop的MapReduce。这里主要分析的基于MR的实现。 基于MR的CF实现主要流程就在 org.apache.mahout...
-
Five Steps to Avoiding Java Heap Space Errors
日期:来自:https://www.mapr.com/blog/how-to-avoid-java-heap-space-errors-understanding-and-managing-task-attempt-memory#.VMWvNDGUfXY Keeping these five steps in mind can save you a lot of headaches and avoid Java heap space errors. Calculate me...
-
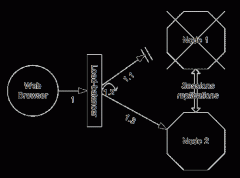
JBOSS 集群配置
日期:1.前言 2006年,Jboss公司被Redhat公司收购了。这直接导致Jboss产品结构调整,并将以前收费的Jboss AS文档改为免费。jijian91本次集群试验的最初依据就是由此得到的Jboss 4.0.5集群配置文档。 但这份官方文档并不可靠,在一些关键配置上含混不清,而且夹杂了很...
-
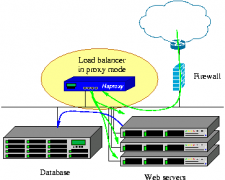
Haproxy 1.5.12 正式发布,Web 负载均衡
日期:Haproxy 1.5.12 正式发布,此版本修复了一些 bugs,其中两个会因为一些特定的配置而发生崩溃。还有一些关于 RFC7230 方面的 bug 修复。此版本禁用了日志记录,响应 400/408 和空白连接错误计数器。其他改进: - BUG/MINOR: ssl: Display correct filename in...
-

HAProxy+Hive构建高可用数据挖掘集群
日期:Hive是facebook开源的一个非常伟大的工具,可以将hadoop中的数据用sql方式进行查询,比自己写map/reduce程序要方便很多。但是在实际使用中发现hive其实不够稳定,极少数情况会出现端口不响应或者进程丢失的问题,所以考虑将hive做成负载均衡的方式。或者更严...
-
python加shell快速部署集群
日期:最近痛感在集群里逐台部署ganglia, cacti这些监控的东西很麻烦,就写了个小程序去批量自动部署。原理是通过python的pexpect用ssh去复制文件和执行系统命令,我用它来部署ganglia等,但是其他的东西也可以通过这个脚本来批量部署,只要自己编写部署脚本就可以...
-
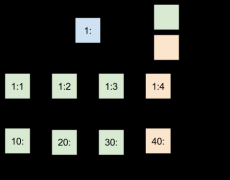
真正零停机 HAProxy 重载
日期:Yelp 础设施团队的主要目标之一就是为了尽可能接近零停机时间。那也就是说当用户访问www.yelp.com 作出动作的时候,网站的响应速度必须尽可能的快。一种方法是使用 HAProxy 负载均衡能够保持 www.yelp.com 网站的响应速度。通常我们在任何地方都使用 HAProxy...
-
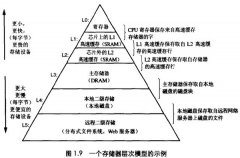
后Hadoop时代的大数据架构
日期:提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年的历史了,很多东西发生了变化,版本也从0.x 进化到目前的2.6版本。我把2012年后定义成后Hadoop平台时代,这不是说不用Hadoop,而是像NoSQL (Not Only SQL)那样,有其他的选型补充。我在知...