-

Hadoop中HDFS写入文件的原理剖析
日期:要为即将到来的大数据时代最准备不是,下面的大白话简单记录了Hadoop中HDFS在存储文件时都做了哪些个事情,位将来集群问题的排查提供一些参考依据。 步入正题 创建一个新文件的过程: 第一步:客户端通过DistributedFilesystem 对象中的creat()方法来创建...
-
LVS-入门试用
日期:LVS是Linux Virtual Server的简写,意即Linux虚拟服务器,是一个虚拟的服务器集群系统。本项目在1998年5月由章文嵩博士成立,是中国国内最早出现的自由软件项目之一。目前有三种IP负载均衡技术(VS/NAT、VS/TUN和VS/DR); 十种调度算法(rrr|wrr|lc|wlc|lbl...
-
Hadoop-HDFS源码学习草记
日期:HDFS protocol: Block 块定义,组成(blockId,numBytes,generationStamp),定义问块文件的文件命名为blk_{blockId},存储的最小单位。 BlockListAsLongs:每个Block块可以由3个long的数字表达,使用long[]存储Block[],主要用于datanode高效的上报给namenode...
-
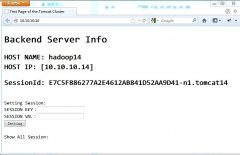
Keepalived + LVS(DR) 高可用负载均衡集群
日期:1、方案说明 目标是搭建企业级的高可用负载均衡集群服务。采用Keepalived + LVS + Tomcat + Memcache Session Manager + Memcached解决方案。其中: LVS:Linux Virtual Server是 Linux 虚拟服务器,可以把多台服务器虚拟为一个虚拟 IP ,同时实现各种负载均...
-
tomcat6_apache2.2_ajp 负载均衡加集群实战分享
日期:环境: -------------------------------------------- 一台apache2.2服务器,三台tomcat服务器: apache2.2服务器 1.ip:192.168.1.20 2.只装apache软件:httpd-2.2.6.tar.bz2 安装路径:/usr/local/apache2 tomcat服务器:均配置相同的应用。 1.集群名:balanc...
-
用apache和tomcat搭建集群(负载均衡)
日期:一、集群和负载均衡的概念 (一)集群的概念 集群(Cluster)是由两台或多台节点机(服务器)构成的一种松散耦合的计算节点集合,为用户提供网络服务或应用程序(包括数据库、Web服务和文件服务等)的单一客户视图,同时提供接近容错机的故障恢复能力。集群系...
-
Red Hat Linux,Apache2.0+Weblogic9.2负载均衡集群安装配置
日期:JDK安装步骤 1. 以root身份登录系统 2. 到java.sun.com去下载JDK1.5 for LINUX的rpm,是个jdk-1_5_0_11-linux-i586-rpm.bin的文件. 3. 通过chmod +x jdk-1_5_x-rc-linux-i586-rpm.bin命令使其获得可执行权限 4. 执行./jdk-1_5_0_11-linux-i586-rpm.bin 5....
-
nginx+keepalived配置高可用HTTP群集
日期:Nginx不仅是一款优秀的WEB 服务器 ,同时可以根据nginx的反代理可以 配置 成强大的负载均衡器.这里就介绍如何把nginx 配置 成负载均衡器,并结合keepalived 配置 高 可用 的集群. 一般集群主要 架构 为: 前端为负载均衡器两个:主/备,两种工作方式,一种是备机待...
-

nagios监控heartbeat配置教程
日期:先来看几个命令,在heartbeat安装后会自动加上,在监控脚本中会用到以下命令: 复制代码 代码示例: [root@usvr-210 libexec]# which cl_status /usr/bin/cl_status [root@usvr-210 libexec]# cl_status listnodes #列出当前heartbeat集群中的节点 192.168.3....
-
使用nagios做heartbeat监控时,在nagios服务器端报警提示:NRPE: Command 'check_heartbeat' not defined
日期:在将heartbeat应用到线上后,启动service heartbeat start没有反应,可以参考下这里的解决方法。 heartbeat启动后无反应 查看日志文件: tail -f /var/log/ha-log: heartbeat[30680]: 2015/01/27_18:04:29 info: Version 2 support: false heartbeat[30680]:...