-

Hadoop 稳定性与性能提升浅析
日期:在 2012 Hadoop与大数据技术大会 上,阿里系的无影带来了题为阿里Hadoop集群架构及服务体系的演讲,他主要介绍了阿里集群的发展现状、服务模式和挑战、Hadoop版本特性等方面的内容。本文主要尝试解析该PPT( http://hbtc2012.hadooper.cn/subject/track1lian...
-
浅析 Hadoop 中的数据倾斜
日期:最近几次被问到关于数据倾斜的问题,这里找了些资料也结合一些自己的理解. 在并行计算中我们总希望分配的每一个task 都能以差不多的粒度来切分并且完成时间相差不大,但是集群中可能硬件不同,应用的类型不同和切分的数据大小不一致总会导致有部分任务极大的...
-
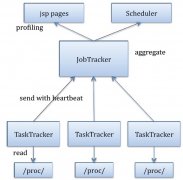
Hadoop资源感知调度器简介
日期:先来几个名词解释: hadoop:apache基金会的开源分布式计算平台。 MapReduce :hadoop的分布式计算模型,由map任务和reduce任务组成。 Jobtracker :hadoop计算系统的总控。 Tasktracker :hadoop计算系统的子节点。 Slot(槽位) :tasktracker的最小计算分配...
-

Hadoop MapReduce 二次排序原理及其应用
日期:关于二次排序主要涉及到这么几个东西: 在0.20.0以前使用的是 setPartitionerClass setOutputkeyComparatorClass setOutputValueGroupingComparator 在0.20.0以后使用是 job.setPartitionerClass(Partitioner p); job.setSortComparatorClass(RawComparator...
-
关于 hadoop reduce 阶段遍历 Iterable 的 2 个“坑”
日期:之前有童鞋问到了这样一个问题:为什么我在 reduce 阶段遍历了一次Iterable 之后,再次遍历的时候,数据都没了呢?可能有童鞋想当然的回答:Iterable 只能单向遍历一次,就这样简单的原因。。。事实果真如此吗? 还是用代码说话: package com.test;import j...
-
从 secondarynamenode 中恢复 namenode
日期:1.修改conf/core-site.xml,增加 Xml代码 property namefs.checkpoint.period/name value3600/value descriptionThenumberofsecondsbetweentwoperiodiccheckpoints./description /property property namefs.checkpoint.size/name value67108864/value descrip...
-
使用hadoop进行大规模数据的全局排序
日期:1. Hellow hadoop~~! Hadoop(某人儿子的一只虚拟大象的名字)是一个复杂到极致,又简单到极致的东西。 说它复杂,是因为一个hadoop集群往往有几十台甚至成百上千台low cost的计算机组成,你运行的每一个任务都要在这些计算机上做任务的分发,执行中间数据排...
-
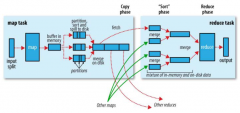
MapReduce: 详解 Shuffle 过程
日期:Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方。要想理解MapReduce, Shuffle是必须要了解的。我看过很多相关的资料,但每次看完都云里雾里的绕着,很难理清大致的逻辑,反而越搅越混。前段时间在做MapReduce job 性能调优的工作,需要深入代码研究...
-

-
hadoop集群增加/删除节点
日期:hadoop要发到每个节点的配置文件,只有core-site.xml mapred-site.xml hdfs-site.xml 添加节点 1.修改host 和普通的datanode一样。添加namenode的ip 2.修改namenode的配置文件conf/slaves 添加新增节点的ip或host 3.在新节点的机器上,启动服务 [root@slave-...