Pacemaker集群管理 实现DRBD存储及应用高可用
时间:2014-12-29 19:18 来源:linux.it.net.cn 作者:IT
本次实验目的,使用Pacemaker 实现DRBD存储及应用高可用
实验环境:
系统版本:CentOS release 6.5 (Final)_x64
node1: ip :192.168.0.233 #写进/etc/hosts文件中
node2: ip :192.168.0.234
vip: 192.168.0.183
注意:1.两台机器务必写静态ip,切记莫用dhcp获取ip,确保两个机器互相能ping通
2. 先禁用防火墙和SELinux
注意:此次试验接着我们上一个帖子试验,如有问题,请参照上一个帖子
http://blog.chinaunix.net/uid-26719405-id-4704258.html
一.安装/配置DRBD
我这里用的是drbd-8.4.3.tar.gz 源码包,制作的rpm包,
经测试:源码包编译安装drbd后,drbd正常工作,Pacemaker,添加进资源,无法管理
(1).制作rpm包步骤
制作工具 yum install rpm-build -y #这个一定要安装的
[root@node1 ~]# mkdir -p ~/rpmbuild/SOURCES
[root@node1 ~]# cd ~/rpmbuild/SOURCES/
[root@node1 SOURCES]# cp /usr/local/src/drbd-8.4.3.tar.gz . #拷贝源码包
[root@node1 SOURCES]# tar -zxvf drbd-8.4.3.tar.gz
[root@node1 SOURCES]# cd drbd-8.4.3
[root@node1 drbd-8.4.3]# ./configure --enable-spec --with-km
[root@node1 drbd-8.4.3]# rpmbuild -ba drbd.spec
[root@node1 drbd-8.4.3]# rpmbuild -ba drbd-km.spec #编译已经完成
把我们编译成的包,拷贝到另一台机器上安装即可

(2)安装DRBD软件包 (两台机器都需要安装)
[root@node1 x86_64]# yum install drbd-* -y #安装我们编译成的rpm包
(3)配置我们的drbd (两台drbd配置文件,配置必须一样)
①添加内核模块
[root@node1 x86_64]# modprobe drbd
[root@node1 x86_64]# lsmod |grep drbd


②给drbd一个分区,不需要格式化这里使用的/dev/xvdb5 这个设备
[root@node1 drbd.d] vi /etc/drbd.d/dbdata.res #配置文件两台主机保持一样
resource data {
on node1{
device /dev/drbd1;
disk /dev/xvdb5; #我们给drbd的分区名字
address 192.168.0.233:7789; #主机ip和drbd数据通信的端口
meta-disk internal;
}
on node2{
device /dev/drbd1;
disk /dev/xvdb5;
address 192.168.0.234:7789;
meta-disk internal;
}
}
[root@node2 drbd.d] vi /etc/drbd.d/dbdata.res #配置文件两台主机保持一样
resource data {
on node1{
device /dev/drbd1;
disk /dev/xvdb5; #我们给drbd的分区名字
address 192.168.0.233:7789; #主机ip和drbd数据通信的端口
meta-disk internal;
}
on node2{
device /dev/drbd1;
disk /dev/xvdb5;
address 192.168.0.234:7789;
meta-disk internal;
}
}
③ 初始化drbd
[root@node2 drbd.d]# drbdadm create-md data -c /etc/drbd.conf #中途提示输入”yes”
[root@node1 drbd.d]# drbdadm create-md data -c /etc/drbd.conf #中途提示输入”yes”
④启动drbd服务: #两个都启动
[root@node1 drbd.d]# /etc/init.d/drbd start
[root@node2 drbd.d]# /etc/init.d/drbd start
查看drbd状态,会是这样,第一次安装都会这样,不用担心,切换一下就可以了

[root@node1 drbd.d]# drbdadm primary --force data -c /etc/drbd.conf
再次查看,ok已经开始同步了,同步完毕,我们再操作

查看状态已经同步完毕

⑤向DRBD中添加数据
[root@node1 drbd.d]# mkfs.ext4 /dev/drbd1 #格式化drbd1
[root@node1 drbd.d]# mount /dev/drbd1 /mnt/ #挂载到/mnt下
cat <<-END >/mnt/index.html #写入数据,方便测试
<html>
<body>welcome to drbd</body>
</html>
END
二.在集群中配置DRBD
查看我们现在正在使用的集群状态
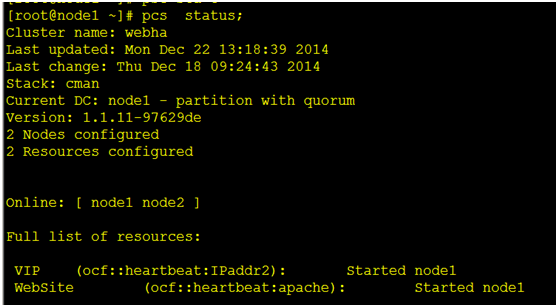
现在有一个vip资源,和一个Apache资源
(1)我们需要用 cib 创建一个文件,通过cib写入xml文件中启动
[root@node1 ~]# pcs cluster cib test_drbd_cfg
[root@node1 ~]# pcs -f test_drbd_cfg resource create Data ocf:linbit:drbd drbd_resource=data op monitor interval=60s
现在使用PCS-f选项,更改保存在test_drbd_cfg文件中的配置。此配置由cib推入集群
ocf:linbit:drbd 就是调用的drbd功能模块,drbd_resource=data 这里的data就是我们drbd里面设置的资源 monitor interval=60s 监控间隔时间 cib保存的是我们的机器配置格式xml 查看命令: pcs cluster cib
[root@node1 ~]# pcs -f test_drbd_cfg resource master DataClone Data master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true
设置我们的从设备
查看我们创建好的资源

提交我们的配置到集群中
[root@node1 ~]# pcs cluster cib-push test_drbd_cfg
注意:官方给的文档,例子 #pcs cluster push cib fs_cfg 这样写是错误的

[root@node1 ~]# pcs status #查看集群工作状态
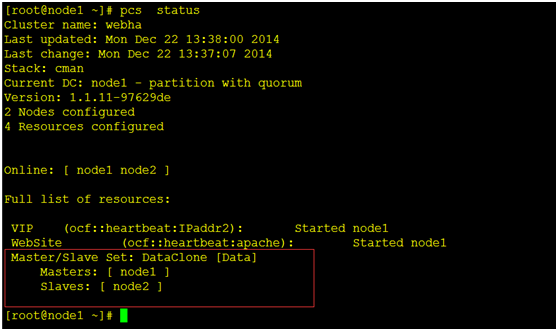
(2)现在DRBD已经工作了,我们可以配置一个Filesystem资源来使用它。 此外,对于这个文件系统的定义,同样的我们告诉集群这个文件系统能在哪运行(主DRBD运行的节点)以及什么时候可以启动(在主DRBD启动以后)。
[root@node1 ~]# pcs cluster cib fs_cfg #创建一个fs_cfg 文件,一会用cib推入集群配置
[root@node1 ~]# pcs -f fs_cfg resource create WebFS Filesystem device="/dev/drbd1" directory="/var/www/html" fstype="ext4"
device写我们的drbd设备,directory写我们Apache的网页存放目录,fstype,文件系统格式
[root@node1 ~]# pcs -f fs_cfg constraint colocation add WebFS DataClone INFINITY with-rsc-role=Master
[root@node1 ~]# pcs -f fs_cfg constraint order promote DataClone then start WebFS

(3)告诉集群Apache也要运行在同样的节点上,而且文件系统要在Apache之前启动。
[root@node1 ~]# pcs -f fs_cfg constraint colocation add WebSite WebFS INFINITY
[root@node1 ~]# pcs -f fs_cfg constraint order WebFS then WebSite

查看我们创建的资源
[root@node1 ~]# pcs -f fs_cfg constraint
[root@node1 ~]# pcs -f fs_cfg resource show
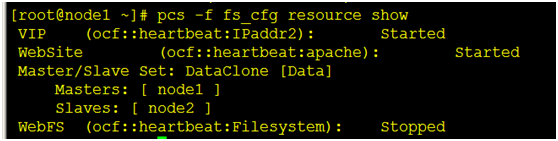
(4)提交我们的配置
[root@node1 ~]# pcs cluster cib-push fs_cfg
注意:官方给的文档,例子:pcs cluster push cib fs_cfg,这样写是错误的
[root@node1 ~]# pcs status
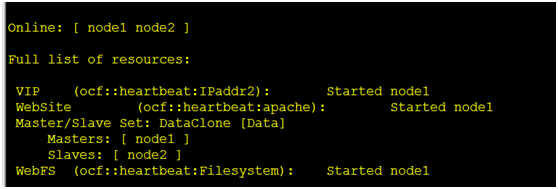
用我们的vip访问测试一下,是否是我们之前创建进存储的index.html文件
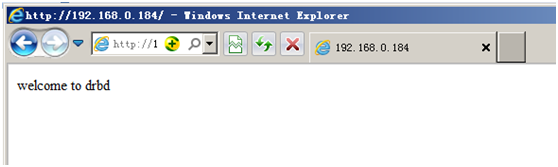
呵呵,多么可人的界面出现了,我们能访问到我们存储中的文件了
注意:selinux切记要关闭,或者你自己微调也行,不然Apache启动会报错,导致服务切换不过去
(5): 故障迁移测试
把一个本地节点设置为standby模式并观察集群把所有资源移动到另外一个节点了。并且注意节点的状态改变为不能运行任何的资源。
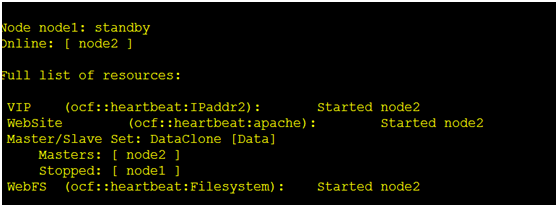
我们把node1 干掉,所有服务会自动切换到node2,node2存储变成stopped了
[root@node1 ~]# pcs cluster standby node1
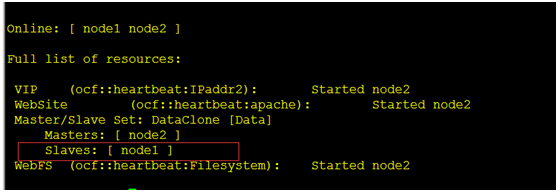
恢复我们的node1
[root@node1 ~]# pcs cluster unstandby node1
存储node1 也正常了
Pacemaker 集群管理,还有许多强大功能,正在挖掘,敬请期待!
(责任编辑:IT)
本次实验目的,使用Pacemaker 实现DRBD存储及应用高可用
实验环境: 系统版本:CentOS release 6.5 (Final)_x64 node1: ip :192.168.0.233 #写进/etc/hosts文件中 node2: ip :192.168.0.234 vip: 192.168.0.183 注意:1.两台机器务必写静态ip,切记莫用dhcp获取ip,确保两个机器互相能ping通 2. 先禁用防火墙和SELinux
注意:此次试验接着我们上一个帖子试验,如有问题,请参照上一个帖子 http://blog.chinaunix.net/uid-26719405-id-4704258.html
一.安装/配置DRBD我这里用的是drbd-8.4.3.tar.gz 源码包,制作的rpm包, 经测试:源码包编译安装drbd后,drbd正常工作,Pacemaker,添加进资源,无法管理 (1).制作rpm包步骤 制作工具 yum install rpm-build -y #这个一定要安装的 [root@node1 ~]# mkdir -p ~/rpmbuild/SOURCES [root@node1 ~]# cd ~/rpmbuild/SOURCES/ [root@node1 SOURCES]# cp /usr/local/src/drbd-8.4.3.tar.gz . #拷贝源码包 [root@node1 SOURCES]# tar -zxvf drbd-8.4.3.tar.gz [root@node1 SOURCES]# cd drbd-8.4.3 [root@node1 drbd-8.4.3]# ./configure --enable-spec --with-km [root@node1 drbd-8.4.3]# rpmbuild -ba drbd.spec [root@node1 drbd-8.4.3]# rpmbuild -ba drbd-km.spec #编译已经完成
把我们编译成的包,拷贝到另一台机器上安装即可
[root@node1 x86_64]# yum install drbd-* -y #安装我们编译成的rpm包
①添加内核模块 [root@node1 x86_64]# modprobe drbd [root@node1 x86_64]# lsmod |grep drbd ②给drbd一个分区,不需要格式化这里使用的/dev/xvdb5 这个设备 [root@node1 drbd.d] vi /etc/drbd.d/dbdata.res #配置文件两台主机保持一样
resource data { on node1{ device /dev/drbd1; disk /dev/xvdb5; #我们给drbd的分区名字 address 192.168.0.233:7789; #主机ip和drbd数据通信的端口 meta-disk internal; } on node2{ device /dev/drbd1; disk /dev/xvdb5; address 192.168.0.234:7789; meta-disk internal; } } [root@node2 drbd.d] vi /etc/drbd.d/dbdata.res #配置文件两台主机保持一样
resource data { on node1{ device /dev/drbd1; disk /dev/xvdb5; #我们给drbd的分区名字 address 192.168.0.233:7789; #主机ip和drbd数据通信的端口 meta-disk internal; } on node2{ device /dev/drbd1; disk /dev/xvdb5; address 192.168.0.234:7789; meta-disk internal; } }
③ 初始化drbd [root@node2 drbd.d]# drbdadm create-md data -c /etc/drbd.conf #中途提示输入”yes” [root@node1 drbd.d]# drbdadm create-md data -c /etc/drbd.conf #中途提示输入”yes”
④启动drbd服务: #两个都启动 [root@node1 drbd.d]# /etc/init.d/drbd start [root@node2 drbd.d]# /etc/init.d/drbd start 查看drbd状态,会是这样,第一次安装都会这样,不用担心,切换一下就可以了
[root@node1 drbd.d]# drbdadm primary --force data -c /etc/drbd.conf 再次查看,ok已经开始同步了,同步完毕,我们再操作
查看状态已经同步完毕
⑤向DRBD中添加数据[root@node1 drbd.d]# mkfs.ext4 /dev/drbd1 #格式化drbd1 [root@node1 drbd.d]# mount /dev/drbd1 /mnt/ #挂载到/mnt下
cat <<-END >/mnt/index.html #写入数据,方便测试 <html> <body>welcome to drbd</body> </html> END
二.在集群中配置DRBD查看我们现在正在使用的集群状态
现在有一个vip资源,和一个Apache资源 (1)我们需要用 cib 创建一个文件,通过cib写入xml文件中启动 [root@node1 ~]# pcs cluster cib test_drbd_cfg
[root@node1 ~]# pcs -f test_drbd_cfg resource create Data ocf:linbit:drbd drbd_resource=data op monitor interval=60s
现在使用PCS-f选项,更改保存在test_drbd_cfg文件中的配置。此配置由cib推入集群 ocf:linbit:drbd 就是调用的drbd功能模块,drbd_resource=data 这里的data就是我们drbd里面设置的资源 monitor interval=60s 监控间隔时间 cib保存的是我们的机器配置格式xml 查看命令: pcs cluster cib
[root@node1 ~]# pcs -f test_drbd_cfg resource master DataClone Data master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true
设置我们的从设备
查看我们创建好的资源
提交我们的配置到集群中
[root@node1 ~]# pcs cluster cib-push test_drbd_cfg
[root@node1 ~]# pcs status #查看集群工作状态
(2)现在DRBD已经工作了,我们可以配置一个Filesystem资源来使用它。 此外,对于这个文件系统的定义,同样的我们告诉集群这个文件系统能在哪运行(主DRBD运行的节点)以及什么时候可以启动(在主DRBD启动以后)。
[root@node1 ~]# pcs cluster cib fs_cfg #创建一个fs_cfg 文件,一会用cib推入集群配置 [root@node1 ~]# pcs -f fs_cfg resource create WebFS Filesystem device="/dev/drbd1" directory="/var/www/html" fstype="ext4"
device写我们的drbd设备,directory写我们Apache的网页存放目录,fstype,文件系统格式
[root@node1 ~]# pcs -f fs_cfg constraint colocation add WebFS DataClone INFINITY with-rsc-role=Master
[root@node1 ~]# pcs -f fs_cfg constraint order promote DataClone then start WebFS
(3)告诉集群Apache也要运行在同样的节点上,而且文件系统要在Apache之前启动。 [root@node1 ~]# pcs -f fs_cfg constraint colocation add WebSite WebFS INFINITY [root@node1 ~]# pcs -f fs_cfg constraint order WebFS then WebSite
查看我们创建的资源 [root@node1 ~]# pcs -f fs_cfg constraint [root@node1 ~]# pcs -f fs_cfg resource show
(4)提交我们的配置 [root@node1 ~]# pcs cluster cib-push fs_cfg 注意:官方给的文档,例子:pcs cluster push cib fs_cfg,这样写是错误的 [root@node1 ~]# pcs status
用我们的vip访问测试一下,是否是我们之前创建进存储的index.html文件
呵呵,多么可人的界面出现了,我们能访问到我们存储中的文件了 注意:selinux切记要关闭,或者你自己微调也行,不然Apache启动会报错,导致服务切换不过去
(5): 故障迁移测试 把一个本地节点设置为standby模式并观察集群把所有资源移动到另外一个节点了。并且注意节点的状态改变为不能运行任何的资源。
我们把node1 干掉,所有服务会自动切换到node2,node2存储变成stopped了 [root@node1 ~]# pcs cluster standby node1
恢复我们的node1 [root@node1 ~]# pcs cluster unstandby node1 存储node1 也正常了
|