Apache HBaseИпПЩгУадЕФаТНзЖЮ
ЪБМф:2015-02-23 22:10 РДдД:hortonworks.com зїеп:IT
Apache HBaseЪЧвЛИіУцЯђЯпЩЯЗўЮёЕФЪ§ОнПтЃЌЦфдЩњжЇГжHadoopЕФЬиадЃЌЪЙЦфГЩЮЊФЧаЉЛљгкHadoopЕФРЉеЙадКЭСщЛюадНјааЪ§ОнДІРэЕФгІгУЯдЖјвзМћЕФбЁдёЁЃ
дкHortonworksЪ§ОнЦНЬЈЃЈHDP http://zh.hortonworks.com/hdp/ЃЉ 2.2жаЃЌHBaseЕФИпПЩгУадЕУЕНСЫГЄзуЕФЗЂеЙЃЌФмЙЛБЃжЄЦфЩЯдЫаагІгУЕФе§ГЃдЫааЪБМфДяЕН99.99%ЁЃ
БОЮФНЋЛиЙЫЙ§ШЅ12ИідТЕФПЊЗЂРњГЬЃЌеЙЪОПЊЗЂШЫдБШчКЮИФНјHBaseЕФИпПЩгУадЃЌВЂЬжТлЮДРДЕФИФНјМЦЛЎЁЃ
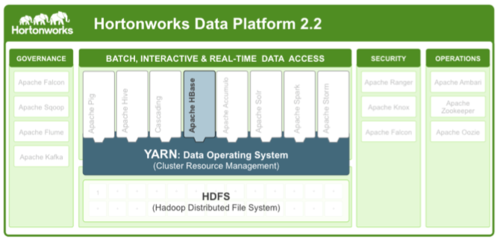
HBaseИпПЩгУадЕФРњЪЗЙлЕу
ИпПЩгУад(HA)ЪЧШЮКЮЪ§ОнПтЕФЙиМќЬиадЃЌвВЪЧШЮКЮКЫаФвЕЮёгІгУЕФЯШОіЬѕМўЁЃ
вдЧАЃЌHBaseЪЙгУСНжжВпТдРДБЃеЯЪ§ОнЕФПЩгУадЃК
ЕквЛЃЌHBaseНЋЪ§ОнздЖЏЗжЧјЃЌВЂНЋИїИіЗжЧјЗЂВМЕНВЛЭЌЕФНкЕуЩЯШЅЁЃФГИіНкЕуЯТЯпЛђхДЛњжЛЛсгАЯьИУНкЕуЩЯЕФЪ§ОнЃЌЦфЫћНкЕуЩЯЕФЪ§ОнВЛЛсЪмЕНгАЯьЁЃ
ЕкЖўЃЌЫљгаДцДЂдкHBaseЩЯЕФЪ§ОнЪЕМЪЩЯЖМБЛДцДЂдкHDFSЩЯЃЌЪ§ОнБЛБИЗнГЩ3ЗнЃЌЗжВМдкВЛЭЌЕФНкЕуЩЯЃЌВЂЧвМЏШКжаШЮКЮНкЕуЖМПЩвдЪЙгУетаЉЪ§ОнЁЃ
етЪЙЕУHBaseПЩвдздЖЏНЋЪЇАмНкЕуЩЯЭаЙмЕФЪ§ОнжиаТЗжХфИје§ГЃЕФНкЕуЃЌДгЖјБЃжЄСЫЪ§ОнЕФИпПЩгУадЁЃ
ШчЙћзлКЯРћгУетаЉЙЬгаЕФHAЬиадЃЌВЂНсКЯHadoopзюМбЪЕМљЃЌЪЙЕУЛљгкHBaseгІгУЕФИпПЩгУадЭъШЋгаПЩФмДяЕН99.9%ЃЌМДУПФъзмхДЛњЪБМфЕЭгк9аЁЪБЁЃ
етЪЪгУгкДѓЖрЪ§гІгУЃЌЖјЖдгкЯЕЭГКЫаФгІгУРДЫЕЃЌашвЊИќИпЕФПЩгУадБЃеЯЁЃ
ИќКУЕФИпПЩгУадашЧѓ
ЮвУЧе§ДІгкДѓЪ§ОнгІгУзЊЯђHadoopЦНЬЈдйдьЕФдчЦкНзЖЮЁЃHadoopЕФЦеМАТЪКЭгАЯьСІгыШеОудіЃЌвбГЩЮЊЧПЕїЯЕЭГРЉеЙадЛђепЪ§ОнДІРэСщЛюадгІгУЕФВЛЖўжЎбЁЁЃ
ЖдгкФЧаЉЯыДгHadoopЮоДІВЛдкЁЂНјеЙбИЫйЕФДДаТжаЪмвцЕФЯпЩЯгІгУРДЫЕЃЌHBaseзїЮЊHadoopЩњЬЌжаЕФвЛдБЃЌздШЛГЩЮЊЪзбЁЕФЪ§ОнПтЁЃ
ЕБЮвУЧгывЛаЉЯЃЭћНЋЙиМќвЕЮёЧЈвЦЕНHBaseЩЯЕФПЭЛЇНЛСїЪБЃЌЮвУЧОГЃЪеЕНШчЯТЗДРЁЃЌПЭЛЇашвЊHBaseЬсЙЉЪ§ОнвЛжТадЃЌЕЋЪЧШДЮоЗЈШнШЬФФХТЪЧКмЖЬЕФхДЛњЛжИДЪБМфЁЃЮЊСЫЪЙHadoopФмЙЛжЇГХдкЯпгІгУЕФЙиМќвЕЮёЃЌHBaseЕФИпПЩгУадЬиадашвЊНјааДѓЗљЖШЕФИФНјЁЃ
HortonworksгыHBaseЩчЧјЭЈСІКЯзїЃЌЭЈЙ§в§ШыЪБМфжсвЛжТЧјгђИББОММЪѕЃЈвВГЦHBaseЖСИпПЩгУадЃЌЯрЙиФкШнВЮПМHBASEЃ10070ЁОhttps://issues.apache.org/jira/browse/HBASE-10070ЁПЃЉЃЌМЋДѓЕФЬсИпСЫHBaseЕФИпПЩгУадЁЃ
ДгЩЯВуПДЃЌетИіаТЕФHAЬиаддкБщВМHBaseМЏШКЕФжїЧјгђИББОКЭБИЧјгђИББОжаЮЌГжЯрЭЌЪ§ОнЕФЖрИіБИЗнЁЃРћгУHBaseЖСИпПЩгУадЃЌШчЙћвЛИіRegionServerЪЇАмКѓЃЌгУЛЇШдШЛПЩвдДгЦфЫћRegionServerЩЯЖСШЁЪЇАмНкЕуЩЯЕФЪ§ОнЁЃ
вВОЭЪЧЫЕЃЌдкЯЕЭГздЖЏЛжИДЦкМфЃЌгУЛЇжЛЪЧЪЇШЅСЫИУНкЕуЕФаДПЩгУадЃЌЕЋШдШЛПЩвдЖСШЁИУНкЕуЕФЪ§ОнЁЃЖдгкФЧаЉашвЊГжајПЩЖСВЂЧвБЃГжЖСвЛжТадЕФгІгУРДЫЕЃЌHBaseЕФЖСИпПЩгУадЬиадЪЧвЛИіРэЯыЕФбЁдёЁЃ
НсКЯзюМбЪЕМљЃЌШчЪЙгУЫЋИББОКЭЛњМмИажЊЃЌHBaseЖСИпПЩгУадПЩвдЪЙЕУФЧаЉвРРЕHBaseЕФЙиМќвЕЮёгІгУЕФПЩгУадДяЕН99.99%ЁЃ

ЪВУДЪЧЪБМфжсвЛжТадЃП
ДгКУЕФвЛУцПДЃЌетИіЗНЪНЪЙЕУБЃжЄЪ§ОнвЛжТадЕФЪЕЯжЗЧГЃМђЕЅЃЌжЛгавЛИіЫљгаепЕФВпТдвтЮЖзХВЛЛсГіЯжФдСбЃЌВЛЛсГіЯжзюКѓвЛДЮаДгааЇЃЈlast-write-winsЃЉЕФЧщПіЃЌВЂЧвШУМЦЪ§ЦїетРрживЊЙІФмЕФЪЕЯжБфЕУПьЫйКЭМђЕЅЁЃ
ДгВЛКУЕФвЛУцПДЃЌШчЙћвЛИіRegionServerхДЛњСЫЃЌетИіRegionServerГжгаЕФЫљгаМќжЕЗЖЮЇЖМНЋРыЯпЃЌжБЕНЪ§ОнЛжИДЙ§ГЬЭъГЩЮЊжЙЁЃ
дкHBase 0.96жаЃЌетИіЛжИДЙ§ГЬвбОгХЛЏЕНвЛЗжжгвдФкЃЌВЛЙ§ЃЌЮвУЧЛЙЪЧЮўЩќСЫвЛаЉПЩгУадРДБЃжЄЪ§ОнЕФИпЖШвЛжТадЁЃИљОнCAPРэТлЃЌЮвУЧБиаыелжаПМТЧвЛжТадКЭПЩгУадЃЌВЂЧвЛЙУЛгавЛИіЭъУРЕФЯЕЭГЃЌПЩвдвЛжБМцЙЫвЛжТадКЭПЩгУадЁЃ
КмЖрЯжДњЪ§ОнПтЯЕЭГЪдЭМЭЈЙ§ЪЕЯжДПДтЕФAPФЃаЭРДгХЛЏПЩгУадЃЌМДЗХЦњвЛжТадвдгХЛЏПЩгУадЁЃЗХЦњвЛжТадЪЙЕУетРрЪ§ОнПтЕФгУЛЇВЛЕУВЛжБУцЗжВМЪНЯЕЭГжаЕФвЛаЉИДдгЕФвщЬтЁЃКмЖрЪБКђЃЌзюжевЛжТадЪ§ОнПтЕФгУЛЇИќЯёЪЧЪ§ОнПтПЊЗЂШЫдБЃЌЖјВЛНіНіЪЧЪ§ОнПтЪЙгУепЁЃ
ЪЕМЪЩЯЃЌЭјТчЗжЧјЮЪЬтВЂВЛЪЧвЛжБЖМДцдкЃЌЫљгаЃЌУЛгаБивЊЮЊСЫЗРжЙХМЖћЗЂЩњЕФЙЪеЯЖјдкШЮКЮЪБКђЖМЮўЩќвЛжТадЁЃШчЙћЖдетЗНУцЕФЬжТлКЭЪБМфжсвЛжТадЕФЯрЙиФкШнИааЫШЄЃЌПЩвдЖСвЛЯТDaniel AbadiЕФВЉПЭЁОhttp://dbmsmusings.blogspot.com/2010/04/problems-with-cap-and-yahoos-little.htmlЁПЁЃ
HBaseЕФЖСИпПЩгУадЪЕЯжСЫвЛИіЪБМфжсвЛжТадЕФЯЕЭГЃЌИУЯЕЭГЮЊПЊЗЂШЫдБЬсЙЉдкВщбЏНзЖЮбЁдёЪЙгУбЯИёЕФвЛжТадВпТдЛЙЪЧПэЫЩЕФвЛжТадВпТдЕФЙІФмЁЃ
ЪЙгУHBaseЕФЖСИпПЩгУадЃК
-
Ъ§ОнБЛвЛИіжїRegionКЭвЛИіЛђЖрИіИББОRegionЫљГжгаЁЃ
-
ШЮКЮвЛИіRegion(ЮоТлЪЧжїReigonЛЙЪЧИББОRegion)ЖМПЩвдЯьгІеыЖдЩЯЪіЪ§ОнЕФЖСЧыЧѓЁЃ
-
жЛгажїRegionПЩвдДІРэаДЧыЧѓЁЃ
-
ИББОжаЕФЪ§ОнПЩФмгыжїRegionЕФЪ§ОнВЛвЛжТЃЌЕЋЪЧЃЌ
-
ЫљгаИББОЖМЛсАДееЭъШЋвЛжТЕФЫГађЪеЕНИќаТЧыЧѓЁЃ
ДгПЭЛЇЖЫРДПДЃК
-
ПЭЛЇЖЫПЩвддкУПДЮЧыЧѓжажИЖЈЪЙгУКЮжжвЛжТадВпТдЃЌбЯИёЕФ(Consistency.STRONG )ЛЙЪЧПэЫЩЕФ(Consistency.TIMELINE)ЁЃ
-
ЗЕЛиЕФНсЙћЛсЯдЪНЕФжИГіЃЌЪ§ОнЪЧзюаТЕФЃЈМДРДзджїRegionЃЉЛЙЪЧЙ§ЦкЕФЃЈМДРДздИББОRegionЃЉЁЃ
ПЭЛЇЖЫПЩвдИљОнетИіБъЪЖРДНјааВйзїЁЃ
етИіФЃаЭОпгаШчЯТМИИігХЕуЃК
-
БЃжЄаДвЛжТадЃК
-
дкЯЕЭГЙЪеЯЦкМфЃЌЪ§ОнШдШЛПЩЖСЁЃЪЙгУЫЋБИЗнКЭКЯЪЪЕФЛњМмЮЛжУХфжУЃЌHBaseПЩвддкећИіЛњМмЙЪеЯЕФЧщПіЯТЃЌБЃжЄЮоЭЃЛњЕФЪ§ОнПЩЖСадЁЃ
-
ЪБбгЃКЖСвЛжТадШдШЛжЛашвЊвЛДЮЭјТчРДЛиЁЃ
-
ЪБбгЃКПЭЛЇЖЫПЩвдДгЫљгаИББОЫцЛњЖСШЁЪ§ОнЃЌВЂВЩгУЕквЛИіЗЕЛиЕФЯьгІЁЃ
ЪБМфжсвЛжТадМцЙЫСЫЧПвЛжТадКЭЙЪеЯЪБгХбХНЕМЖЕФашЧѓЃЌПЩвддкВЛдіМгПЊЗЂШЫдБДІРэзюжевЛжТадЯЕЭГИДдгЖШЕФЧщПіЯТЃЌЕУЕНИќИпЕФПЩгУадЁЃ
HBaseЖСИпПЩгУадЃКНзЖЮ1/НзЖЮ2
HBaseЖСПЩгУадЕФПЊЗЂОРњСЫСНИіНзЖЮЁЃЕквЛНзЖЮжївЊгУгкбщжЄдаЭКЭAPIгявхЃЌЖјЕкЖўНзЖЮЬсЙЉСЫЪЪКЯЩњВњЛЗОГЕФАцБОЁЃШчЙћФуЙизЂСЫHDP2.1ЬсЙЉЕФHBaseЖСИпПЩгУадЃЌВЂгЩгкЦфЮоЗЈжЇГжsplit/mergeетРрВйзїЕФШБЯнЖјШЯЮЊЦфВЛПЩгУЃЌФЧУДЃЌHDP2.2НЋеыЖдЫљгаФуЦкЭћЕФHBaseВйзїЬсЙЉИпПЩгУадЁЃ
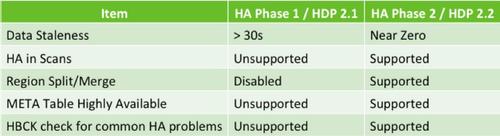
ЖЏЪжЪЕМљ
HBaseЖСПЩгУадЪЧHDP2.2ЦНЬЈЕФвЛИіЬиадЁЃШчЙћФуЖдЬсИпгІгУЕФПЩгУадБШНЯИааЫШЄЃЌФЧУДЮвУЧНЈвщФуФмЙЛГЂЪдвЛЯТЁЃ
HBaesИпПЩгУадеЙЭћ
HBaesЕФИпПЩгУаддкЙ§ШЅвЛФъРяЕУЕНСЫОоДѓЕФИФНјЃЌВЛЙ§ЃЌЛЙгаКмЖрЕиЗНашвЊЭъЩЦЁЃЕНФПЧАЮЊжЙЃЌHBaseЛЙЮДНтОіЕФСНИіживЊЮЪЬтЃК
-
ЙЪеЯЪБЕФаДПЩгУад
-
ПчЪ§ОнжааФЕФЖСаДвЛжТад
ЮвУЧЗЧГЃИпаЫЕФПДЕНHBaseЩчЧјвбОПЊЪМзХЪжНтОіетаЉЮЪЬтЃЌе§ХЌСІЕФНЋFacebookПЊЗЂЕФHydraBaseКЯВЂЕНHBaseжаШЅЁЃЮДРДЃЌHBaseНЋдкБЃжЄЙиМќвЕЮёЯЕЭГЖдЪ§ОнЧПвЛжТадвЊЧѓЕФЭЌЪБЃЌЬсЙЉИпДя5Иі9ЃЈМД99.999%ЃЉЕФПЩгУадЁЃ
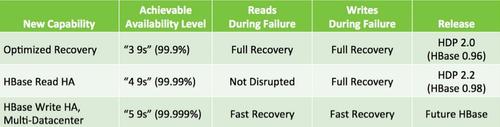
дЮФСДНгЃКhttp://zh.hortonworks.com/blog/apache-hbase-high-availability-next-level/ ЃЈЗвыЃКvboylin1987 ЩѓаЃЃКФуЪЧжЛжэАЁ д№БрЃКСѕбЧЧэЃЉ
(д№ШЮБрМЃКIT)
Apache HBaseЪЧвЛИіУцЯђЯпЩЯЗўЮёЕФЪ§ОнПтЃЌЦфдЩњжЇГжHadoopЕФЬиадЃЌЪЙЦфГЩЮЊФЧаЉЛљгкHadoopЕФРЉеЙадКЭСщЛюадНјааЪ§ОнДІРэЕФгІгУЯдЖјвзМћЕФбЁдёЁЃ дкHortonworksЪ§ОнЦНЬЈЃЈHDP http://zh.hortonworks.com/hdp/ЃЉ 2.2жаЃЌHBaseЕФИпПЩгУадЕУЕНСЫГЄзуЕФЗЂеЙЃЌФмЙЛБЃжЄЦфЩЯдЫаагІгУЕФе§ГЃдЫааЪБМфДяЕН99.99%ЁЃ БОЮФНЋЛиЙЫЙ§ШЅ12ИідТЕФПЊЗЂРњГЬЃЌеЙЪОПЊЗЂШЫдБШчКЮИФНјHBaseЕФИпПЩгУадЃЌВЂЬжТлЮДРДЕФИФНјМЦЛЎЁЃ
HBaseИпПЩгУадЕФРњЪЗЙлЕуИпПЩгУад(HA)ЪЧШЮКЮЪ§ОнПтЕФЙиМќЬиадЃЌвВЪЧШЮКЮКЫаФвЕЮёгІгУЕФЯШОіЬѕМўЁЃ вдЧАЃЌHBaseЪЙгУСНжжВпТдРДБЃеЯЪ§ОнЕФПЩгУадЃК ЕквЛЃЌHBaseНЋЪ§ОнздЖЏЗжЧјЃЌВЂНЋИїИіЗжЧјЗЂВМЕНВЛЭЌЕФНкЕуЩЯШЅЁЃФГИіНкЕуЯТЯпЛђхДЛњжЛЛсгАЯьИУНкЕуЩЯЕФЪ§ОнЃЌЦфЫћНкЕуЩЯЕФЪ§ОнВЛЛсЪмЕНгАЯьЁЃ ЕкЖўЃЌЫљгаДцДЂдкHBaseЩЯЕФЪ§ОнЪЕМЪЩЯЖМБЛДцДЂдкHDFSЩЯЃЌЪ§ОнБЛБИЗнГЩ3ЗнЃЌЗжВМдкВЛЭЌЕФНкЕуЩЯЃЌВЂЧвМЏШКжаШЮКЮНкЕуЖМПЩвдЪЙгУетаЉЪ§ОнЁЃ етЪЙЕУHBaseПЩвдздЖЏНЋЪЇАмНкЕуЩЯЭаЙмЕФЪ§ОнжиаТЗжХфИје§ГЃЕФНкЕуЃЌДгЖјБЃжЄСЫЪ§ОнЕФИпПЩгУадЁЃ ШчЙћзлКЯРћгУетаЉЙЬгаЕФHAЬиадЃЌВЂНсКЯHadoopзюМбЪЕМљЃЌЪЙЕУЛљгкHBaseгІгУЕФИпПЩгУадЭъШЋгаПЩФмДяЕН99.9%ЃЌМДУПФъзмхДЛњЪБМфЕЭгк9аЁЪБЁЃ етЪЪгУгкДѓЖрЪ§гІгУЃЌЖјЖдгкЯЕЭГКЫаФгІгУРДЫЕЃЌашвЊИќИпЕФПЩгУадБЃеЯЁЃ ИќКУЕФИпПЩгУадашЧѓЮвУЧе§ДІгкДѓЪ§ОнгІгУзЊЯђHadoopЦНЬЈдйдьЕФдчЦкНзЖЮЁЃHadoopЕФЦеМАТЪКЭгАЯьСІгыШеОудіЃЌвбГЩЮЊЧПЕїЯЕЭГРЉеЙадЛђепЪ§ОнДІРэСщЛюадгІгУЕФВЛЖўжЎбЁЁЃ ЖдгкФЧаЉЯыДгHadoopЮоДІВЛдкЁЂНјеЙбИЫйЕФДДаТжаЪмвцЕФЯпЩЯгІгУРДЫЕЃЌHBaseзїЮЊHadoopЩњЬЌжаЕФвЛдБЃЌздШЛГЩЮЊЪзбЁЕФЪ§ОнПтЁЃ ЕБЮвУЧгывЛаЉЯЃЭћНЋЙиМќвЕЮёЧЈвЦЕНHBaseЩЯЕФПЭЛЇНЛСїЪБЃЌЮвУЧОГЃЪеЕНШчЯТЗДРЁЃЌПЭЛЇашвЊHBaseЬсЙЉЪ§ОнвЛжТадЃЌЕЋЪЧШДЮоЗЈШнШЬФФХТЪЧКмЖЬЕФхДЛњЛжИДЪБМфЁЃЮЊСЫЪЙHadoopФмЙЛжЇГХдкЯпгІгУЕФЙиМќвЕЮёЃЌHBaseЕФИпПЩгУадЬиадашвЊНјааДѓЗљЖШЕФИФНјЁЃ HortonworksгыHBaseЩчЧјЭЈСІКЯзїЃЌЭЈЙ§в§ШыЪБМфжсвЛжТЧјгђИББОММЪѕЃЈвВГЦHBaseЖСИпПЩгУадЃЌЯрЙиФкШнВЮПМHBASEЃ10070ЁОhttps://issues.apache.org/jira/browse/HBASE-10070ЁПЃЉЃЌМЋДѓЕФЬсИпСЫHBaseЕФИпПЩгУадЁЃ ДгЩЯВуПДЃЌетИіаТЕФHAЬиаддкБщВМHBaseМЏШКЕФжїЧјгђИББОКЭБИЧјгђИББОжаЮЌГжЯрЭЌЪ§ОнЕФЖрИіБИЗнЁЃРћгУHBaseЖСИпПЩгУадЃЌШчЙћвЛИіRegionServerЪЇАмКѓЃЌгУЛЇШдШЛПЩвдДгЦфЫћRegionServerЩЯЖСШЁЪЇАмНкЕуЩЯЕФЪ§ОнЁЃ вВОЭЪЧЫЕЃЌдкЯЕЭГздЖЏЛжИДЦкМфЃЌгУЛЇжЛЪЧЪЇШЅСЫИУНкЕуЕФаДПЩгУадЃЌЕЋШдШЛПЩвдЖСШЁИУНкЕуЕФЪ§ОнЁЃЖдгкФЧаЉашвЊГжајПЩЖСВЂЧвБЃГжЖСвЛжТадЕФгІгУРДЫЕЃЌHBaseЕФЖСИпПЩгУадЬиадЪЧвЛИіРэЯыЕФбЁдёЁЃ НсКЯзюМбЪЕМљЃЌШчЪЙгУЫЋИББОКЭЛњМмИажЊЃЌHBaseЖСИпПЩгУадПЩвдЪЙЕУФЧаЉвРРЕHBaseЕФЙиМќвЕЮёгІгУЕФПЩгУадДяЕН99.99%ЁЃ
ЪВУДЪЧЪБМфжсвЛжТадЃПДгКУЕФвЛУцПДЃЌетИіЗНЪНЪЙЕУБЃжЄЪ§ОнвЛжТадЕФЪЕЯжЗЧГЃМђЕЅЃЌжЛгавЛИіЫљгаепЕФВпТдвтЮЖзХВЛЛсГіЯжФдСбЃЌВЛЛсГіЯжзюКѓвЛДЮаДгааЇЃЈlast-write-winsЃЉЕФЧщПіЃЌВЂЧвШУМЦЪ§ЦїетРрживЊЙІФмЕФЪЕЯжБфЕУПьЫйКЭМђЕЅЁЃ ДгВЛКУЕФвЛУцПДЃЌШчЙћвЛИіRegionServerхДЛњСЫЃЌетИіRegionServerГжгаЕФЫљгаМќжЕЗЖЮЇЖМНЋРыЯпЃЌжБЕНЪ§ОнЛжИДЙ§ГЬЭъГЩЮЊжЙЁЃ дкHBase 0.96жаЃЌетИіЛжИДЙ§ГЬвбОгХЛЏЕНвЛЗжжгвдФкЃЌВЛЙ§ЃЌЮвУЧЛЙЪЧЮўЩќСЫвЛаЉПЩгУадРДБЃжЄЪ§ОнЕФИпЖШвЛжТадЁЃИљОнCAPРэТлЃЌЮвУЧБиаыелжаПМТЧвЛжТадКЭПЩгУадЃЌВЂЧвЛЙУЛгавЛИіЭъУРЕФЯЕЭГЃЌПЩвдвЛжБМцЙЫвЛжТадКЭПЩгУадЁЃ КмЖрЯжДњЪ§ОнПтЯЕЭГЪдЭМЭЈЙ§ЪЕЯжДПДтЕФAPФЃаЭРДгХЛЏПЩгУадЃЌМДЗХЦњвЛжТадвдгХЛЏПЩгУадЁЃЗХЦњвЛжТадЪЙЕУетРрЪ§ОнПтЕФгУЛЇВЛЕУВЛжБУцЗжВМЪНЯЕЭГжаЕФвЛаЉИДдгЕФвщЬтЁЃКмЖрЪБКђЃЌзюжевЛжТадЪ§ОнПтЕФгУЛЇИќЯёЪЧЪ§ОнПтПЊЗЂШЫдБЃЌЖјВЛНіНіЪЧЪ§ОнПтЪЙгУепЁЃ ЪЕМЪЩЯЃЌЭјТчЗжЧјЮЪЬтВЂВЛЪЧвЛжБЖМДцдкЃЌЫљгаЃЌУЛгаБивЊЮЊСЫЗРжЙХМЖћЗЂЩњЕФЙЪеЯЖјдкШЮКЮЪБКђЖМЮўЩќвЛжТадЁЃШчЙћЖдетЗНУцЕФЬжТлКЭЪБМфжсвЛжТадЕФЯрЙиФкШнИааЫШЄЃЌПЩвдЖСвЛЯТDaniel AbadiЕФВЉПЭЁОhttp://dbmsmusings.blogspot.com/2010/04/problems-with-cap-and-yahoos-little.htmlЁПЁЃ HBaseЕФЖСИпПЩгУадЪЕЯжСЫвЛИіЪБМфжсвЛжТадЕФЯЕЭГЃЌИУЯЕЭГЮЊПЊЗЂШЫдБЬсЙЉдкВщбЏНзЖЮбЁдёЪЙгУбЯИёЕФвЛжТадВпТдЛЙЪЧПэЫЩЕФвЛжТадВпТдЕФЙІФмЁЃ ЪЙгУHBaseЕФЖСИпПЩгУадЃК
ДгПЭЛЇЖЫРДПДЃК
ПЭЛЇЖЫПЩвдИљОнетИіБъЪЖРДНјааВйзїЁЃ етИіФЃаЭОпгаШчЯТМИИігХЕуЃК
ЪБМфжсвЛжТадМцЙЫСЫЧПвЛжТадКЭЙЪеЯЪБгХбХНЕМЖЕФашЧѓЃЌПЩвддкВЛдіМгПЊЗЂШЫдБДІРэзюжевЛжТадЯЕЭГИДдгЖШЕФЧщПіЯТЃЌЕУЕНИќИпЕФПЩгУадЁЃ HBaseЖСИпПЩгУадЃКНзЖЮ1/НзЖЮ2HBaseЖСПЩгУадЕФПЊЗЂОРњСЫСНИіНзЖЮЁЃЕквЛНзЖЮжївЊгУгкбщжЄдаЭКЭAPIгявхЃЌЖјЕкЖўНзЖЮЬсЙЉСЫЪЪКЯЩњВњЛЗОГЕФАцБОЁЃШчЙћФуЙизЂСЫHDP2.1ЬсЙЉЕФHBaseЖСИпПЩгУадЃЌВЂгЩгкЦфЮоЗЈжЇГжsplit/mergeетРрВйзїЕФШБЯнЖјШЯЮЊЦфВЛПЩгУЃЌФЧУДЃЌHDP2.2НЋеыЖдЫљгаФуЦкЭћЕФHBaseВйзїЬсЙЉИпПЩгУадЁЃ
ЖЏЪжЪЕМљHBaseЖСПЩгУадЪЧHDP2.2ЦНЬЈЕФвЛИіЬиадЁЃШчЙћФуЖдЬсИпгІгУЕФПЩгУадБШНЯИааЫШЄЃЌФЧУДЮвУЧНЈвщФуФмЙЛГЂЪдвЛЯТЁЃ HBaesИпПЩгУадеЙЭћHBaesЕФИпПЩгУаддкЙ§ШЅвЛФъРяЕУЕНСЫОоДѓЕФИФНјЃЌВЛЙ§ЃЌЛЙгаКмЖрЕиЗНашвЊЭъЩЦЁЃЕНФПЧАЮЊжЙЃЌHBaseЛЙЮДНтОіЕФСНИіживЊЮЪЬтЃК
ЮвУЧЗЧГЃИпаЫЕФПДЕНHBaseЩчЧјвбОПЊЪМзХЪжНтОіетаЉЮЪЬтЃЌе§ХЌСІЕФНЋFacebookПЊЗЂЕФHydraBaseКЯВЂЕНHBaseжаШЅЁЃЮДРДЃЌHBaseНЋдкБЃжЄЙиМќвЕЮёЯЕЭГЖдЪ§ОнЧПвЛжТадвЊЧѓЕФЭЌЪБЃЌЬсЙЉИпДя5Иі9ЃЈМД99.999%ЃЉЕФПЩгУадЁЃ
дЮФСДНгЃКhttp://zh.hortonworks.com/blog/apache-hbase-high-availability-next-level/ ЃЈЗвыЃКvboylin1987 ЩѓаЃЃКФуЪЧжЛжэАЁ д№БрЃКСѕбЧЧэЃЉ (д№ШЮБрМЃКIT) |