RedisΦ·»ΚΦΦ θΦΑCodis ΒΦυ (2)
±Φδ:2015-04-19 15:57 ά¥‘¥:linux.it.net.cn Ής’Ώ:IT
3. Codis ΒΦυ
Codis”…ΆψΕΙΦ‘”Ύ2014Ρξ11‘¬ΩΣ‘¥Θ§Μυ”ΎGoΚΆCΩΣΖΔΘ§ «ΫϋΤΎ”Ωœ÷ΒΡΓΔΙζ»ΥΩΣΖΔΒΡ”≈–ψΩΣ‘¥»μΦΰ÷°“ΜΓΘœ÷“―ΙψΖΚ”Ο”ΎΆψΕΙΦ‘ΒΡΗς÷÷Redis“ΒΈώ≥ΓΨΑΘ®“―ΒΟΒΫΆψΕΙΦ‘@ΝθΤφΆ§―ßΒΡ»Ζ»œΘ§Κ«Κ«Θ©ΓΘ
¥”3Ηω‘¬ΒΡΗς÷÷―ΙΝΠ≤β ‘ά¥Ω¥Θ§Έ»Ε®–‘ΖϊΚœΗΏ–ß‘ΥΈ§ΒΡ“Σ«σΓΘ–‘ΡήΗϋ «ΗΡ…ΤΚήΕύΘ§Ήν≥θ±»Twemproxy¬ΐ20%ΘΜœ÷‘Ύ±»TwemproxyΩλΫϋ100%Θ®ΧθΦΰΘΚΕύ ΒάΐΘ§“ΜΑψValue≥ΛΕ»Θ©ΓΘ
3.1 ΧεœΒΦήΙΙ
Codis“ΐ»κΝΥGroupΒΡΗ≈ΡνΘ§ΟΩΗωGroupΑϋά®1ΗωRedis MasterΦΑ÷Ν…Ό1ΗωRedis SlaveΘ§’β «ΚΆTwemproxyΒΡ«χ±π÷°“ΜΓΘ’β―υΉωΒΡΚΟ¥Π «Θ§»γΙϊΒ±«ΑMaster”–Έ ΧβΘ§‘ρ‘ΥΈ§»Υ‘±Ω…Ά®ΙΐDashboard“Ή‘÷ζ Ϋ”«–ΜΜΒΫSlaveΘ§Εχ≤Μ–η“Σ–Γ–Ρ“μ“μΒΊ–όΗΡ≥Χ–ρ≈δ÷ΟΈΡΦΰΓΘ
ΈΣ÷ß≥÷ ΐΨί»»«®“ΤΘ®Auto RebalanceΘ©Θ§≥ωΤΖΖΫ–όΗΡΝΥRedis Server‘¥¬κΘ§≤Δ≥Τ÷°ΈΣCodis ServerΓΘ
Codis≤…”Ο‘Λœ»Ζ÷Τ§Θ®Pre-ShardingΘ©Μζ÷ΤΘ§ ¬œ»ΙφΕ®ΚΟΝΥΘ§Ζ÷≥…1024ΗωslotsΘ®“≤ΨΆ «ΥΒΘ§ΉνΕύΡή÷ß≥÷ΚσΕΥ1024ΗωCodis ServerΘ©Θ§’β–©¬Ζ”…–≈œΔ±Θ¥φ‘ΎZooKeeper÷–ΓΘ
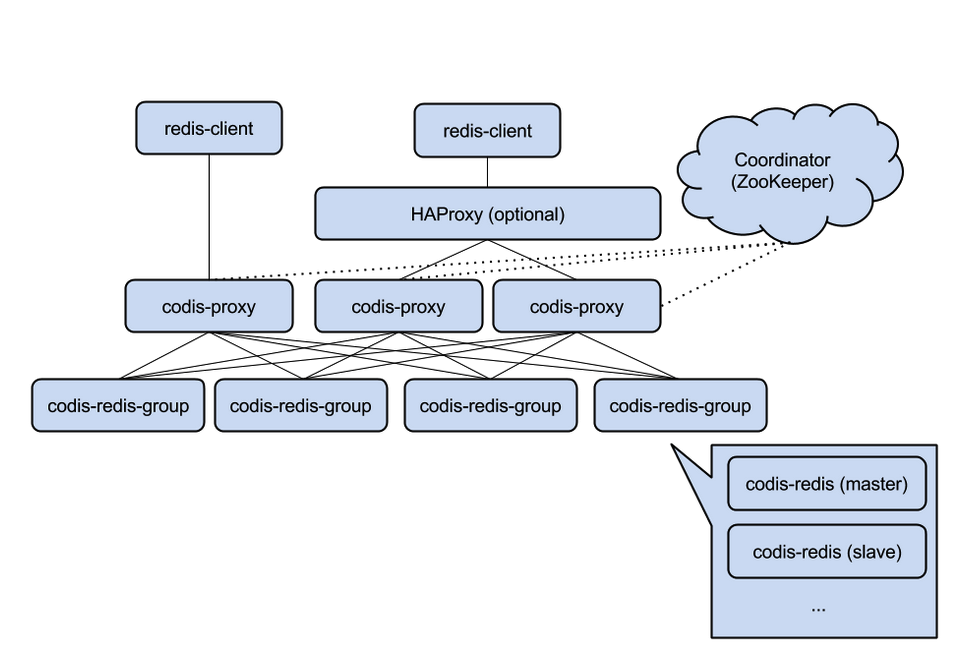
ZooKeeperΜΙΈ§ΜΛCodis Server Group–≈œΔΘ§≤ΔΧαΙ©Ζ÷≤Φ ΫΥχΒ»ΖΰΈώΓΘ
3.2 –‘ΡήΕ‘±»≤β ‘
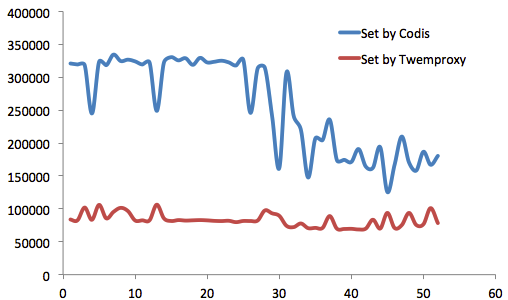
CodisΡΩ«Α»‘±ΜΨΪ“φ«σΨΪΒΊΗΡΫχ÷–ΓΘΤδ–‘ΡήΘ§¥”Ήν≥θΒΡ±»Twemproxy¬ΐ20%Θ®Υδ»Μ’βΕ‘”ΎΡΎ¥φ–Ά”Π”ΟΕχ―‘Θ§≤Δ≤ΜΟςœ‘Θ©Θ§ΒΫœ÷‘Ύ‘Ε‘Ε≥§ΙΐTwemproxy–‘ΡήΘ®“ΜΕ®ΧθΦΰœ¬Θ©ΓΘ
Έ“Ο«Ϋχ––ΝΥ≥Λ¥ο3Ηω‘¬ΒΡ≤β ‘ΓΘ≤β ‘Μυ”Ύredis-benchmarkΘ§Ζ÷±π’κΕ‘CodisΚΆTwemproxyΘ§≤β ‘Value≥ΛΕ»¥”16B~10MB ±ΒΡ–‘ΡήΚΆΈ»Ε®–‘Θ§≤ΔΫχ––Εύ¬÷≤β ‘ΓΘ
“ΜΙ≤”–4Χ®ΈοάμΖΰΈώΤς≤Έ”κ≤β ‘Θ§Τδ÷–“ΜΧ®Ζ÷±π≤Ω πcodisΚΆtwemproxyΘ§ΝμΆβ»ΐΧ®Ζ÷±π≤Ω πcodis serverΚΆredis serverΘ§“‘–Έ≥…ΝΫΗωΦ·»ΚΓΘ
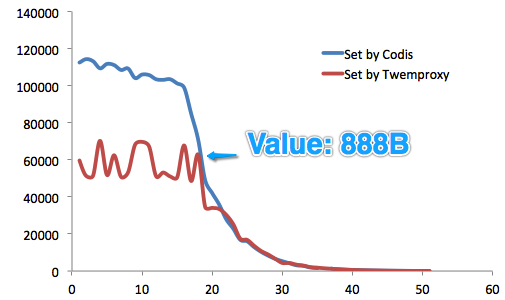
¥”≤β ‘ΫαΙϊά¥Ω¥Θ§ΨΆSet≤ΌΉςΕχ―‘Θ§‘ΎValue≥ΛΕ»<888B ±Θ§Codis–‘Ρή”≈‘Ϋ”≈”ΎTwemproxyΘ®’β‘Ύ“ΜΑψ“ΒΈώΒΡValue≥ΛΕ»ΖΕΈß÷°ΡΎΘ©ΓΘ
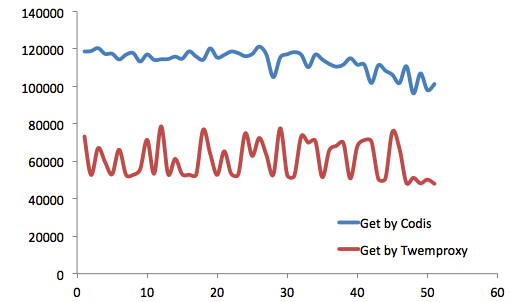
ΨΆGet≤ΌΉςΕχ―‘Θ§Codis–‘Ρή“Μ÷±”≈”ΎTwemproxyΓΘ
3.3 Ι”ΟΦΦ«…ΓΔΉΔ“β ¬œν
CodisΜΙ”–ΚήΕύΚΟΆφΒΡΕΪΕΪΘ§¥” ΒΦ Ι”Οά¥Ω¥Θ§”––©ΒΊΖΫ“≤÷ΒΒΟΉΔ“βΓΘ
1Θ©ΈόΖλ«®“ΤTwemproxy
≥ωΤΖΖΫΧυ–ΡΒΊΉΦ±ΗΝΥCodis-portΙΛΨΏΓΘΆ®ΙΐΥϋΘ§Ω…“‘ Β ±ΒΊΆ§≤Ϋ Twemproxy ΒΉœ¬ΒΡ Redis ΐΨίΒΫΡψΒΡ Codis Φ·»ΚΓΘΆ§≤ΫΆξ≥…ΚσΘ§÷Μ–η–όΗΡ“Μœ¬≥Χ–ρ≈δ÷ΟΈΡΦΰΘ§ΫΪ Twemproxy ΒΡΒΊ÷ΖΗΡ≥… Codis ΒΡΒΊ÷ΖΦ¥Ω…ΓΘ «ΒΡΘ§÷Μ–η“ΣΉω’βΟ¥ΕύΓΘ
2Θ©÷ß≥÷Java≥Χ–ρΒΡHA
CodisΧαΙ©“ΜΗωJavaΩΆΜßΕΥΘ§≤Δ≥Τ÷°ΈΣJodisΘ®ΟϊΉ÷ΚήΩαΘ§ «Α…ΘΩΘ©ΓΘ’β―υΘ§»γΙϊΒΞΗωCodis Proxyε¥ΒτΘ§JodisΉ‘Ε·ΖΔœ÷Θ§≤ΔΉ‘Ε·Ιφ±ή÷°Θ§ ΙΒϓ¸ώ≤Μ ή”ΑœλΘ®’φΒΡΚήΩαΘΓΘ©ΓΘ
3Θ©÷ß≥÷Pipeline
Pipeline ΙΒΟΩΆΜßΕΥΩ…“‘ΖΔ≥ω“Μ≈ζ«κ«σΘ§≤Δ“Μ¥Έ–‘ΜώΒΟ’β≈ζ«κ«σΒΡΖΒΜΊΫαΙϊΓΘ’βΧα…ΐΝΥCodisΒΡœκœσΩ’ΦδΓΘ
¥” ΒΦ ≤β ‘ά¥Ω¥Θ§‘ΎValue≥ΛΕ»–Γ”Ύ888BΉ÷ΫΎ ±Θ§Set–‘Ρή―ΗΟΆΧα…ΐΘΜ
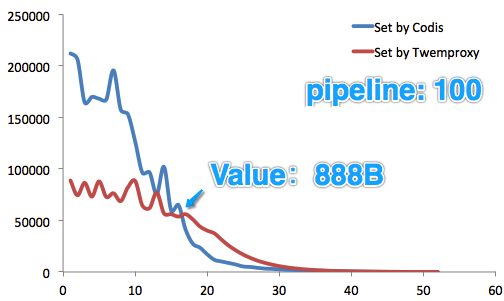
Get–‘Ρή“ύΗ¥»γ «ΓΘ
4Θ©Codis≤ΜΗΚ‘π÷ς¥”Ά§≤Ϋ
“≤ΨΆ «ΥΒΘ§ CodisΫωΗΚ‘πΈ§ΜΛΒ±«ΑRedis ServerΝ–±μΘ§”…‘ΥΈ§»Υ‘±Ή‘ΦΚ»Ξ±Θ÷Λ÷ς¥” ΐΨίΒΡ“Μ÷¬–‘ΓΘ
’β «Έ“Ήν‘ό…ΆΒΡΒΊΖΫ÷°“ΜΓΘ’β―υΒΡΚΟ¥Π «Θ§ΟΜΑ―CodisΗψΒΟΡ«Ο¥÷ΊΓΘ“≤ «Έ“Ο«Η“”ΎΖ≈ ÷‘ΎœΏ…œΜΖΨ≥÷–…œœΏΒΡ‘≠“ρ÷°“ΜΓΘ
5Θ©Ε‘CodisΒΡΚσ–χΤΎ¥ΐΘΩ
ΚΟΑ…Θ§¥÷«≥ΒΊΥΒΝΫΗωΓΘœΘΆϊCodis≤Μ“Σ±δΒΟΧΪ÷ΊΓΘΝμΆβΘ§Φ”pipeline≤Έ ΐΚσΘ§Value≥ΛΕ»»γΙϊΫœ¥σΘ§–‘ΡήΖ¥Εχ±»Twemproxy“ΣΒΆ“Μ–©Θ§œΘΆϊΡή”–ΗΡ…ΤΘ®Έ“Ο«Εύ¬÷―Ι≤βΫαΙϊΕΦ»γ¥ΥΘ©ΓΘ
“ρΤΣΖυ”–œόΘ§‘¥¬κΖ÷Έω≤Μ‘Ύ¥Υ’ΙΩΣΓΘΝμΆβCodis‘¥¬κΓΔΧεœΒΫαΙΙΦΑFAQΘ§≤ΈΦϊ»γœ¬Ν¥Ϋ”ΘΚ https://github.com/wandoulabs/codis
PSΘΚœΏ…œΈΡΒΒΒΡΩ…ΕΝ–‘Θ§“≤ «œύΒ±÷ΒΒΟ≥Τ‘όΒΡΒΊΖΫΓΘ“ΜΨδΜΑΘΚΚήΉΏ–ΡΘ§‘όΘΓ
ΉνΚσΘ§Redis≥θ―ß’Ώ«κ≤ΈΩΦ’βΗωΝ¥Ϋ”ΘΚhttp://www.gamecbg.com/bc/db/redis/13852.htmlΘ§ΈΡΉ÷«≥œ‘“ΉΕ°Θ§Εχ«“±»Ϋœ»ΪΟφΓΘ
±ΨΈΡΒΟΒΫCodisΩΣΖΔΆ≈Ε”ΝθΤφΚΆΜΤΕΪ–ώΆ§―ßΒΡ¥σΝΠ–≠÷ζΘ§≤ΔΒΟΒΫTim Yangάœ ΠΒ»≈σ”―Ο«‘ΎΡΎ»ίΑ―ΩΊΖΫΟφΒΡ÷ΗΒΦΓΘ±ΨΈΡΙ≤Ά§Ής’ΏΈΣ’‘ΈΡΜΣΆ§―ßΘ§Υϊ÷ς“ΣΗΚ‘πCodisΦΑTwemproxyΒΡΕ‘±»≤β ‘ΓΘ‘Ύ¥Υ“Μ≤Δ–ΜΙΐΓΘ
(‘π»Έ±ύΦ≠ΘΚIT)
3. Codis ΒΦυ
Codis”…ΆψΕΙΦ‘”Ύ2014Ρξ11‘¬ΩΣ‘¥Θ§Μυ”ΎGoΚΆCΩΣΖΔΘ§ «ΫϋΤΎ”Ωœ÷ΒΡΓΔΙζ»ΥΩΣΖΔΒΡ”≈–ψΩΣ‘¥»μΦΰ÷°“ΜΓΘœ÷“―ΙψΖΚ”Ο”ΎΆψΕΙΦ‘ΒΡΗς÷÷Redis“ΒΈώ≥ΓΨΑΘ®“―ΒΟΒΫΆψΕΙΦ‘@ΝθΤφΆ§―ßΒΡ»Ζ»œΘ§Κ«Κ«Θ©ΓΘ ¥”3Ηω‘¬ΒΡΗς÷÷―ΙΝΠ≤β ‘ά¥Ω¥Θ§Έ»Ε®–‘ΖϊΚœΗΏ–ß‘ΥΈ§ΒΡ“Σ«σΓΘ–‘ΡήΗϋ «ΗΡ…ΤΚήΕύΘ§Ήν≥θ±»Twemproxy¬ΐ20%ΘΜœ÷‘Ύ±»TwemproxyΩλΫϋ100%Θ®ΧθΦΰΘΚΕύ ΒάΐΘ§“ΜΑψValue≥ΛΕ»Θ©ΓΘ 3.1 ΧεœΒΦήΙΙCodis“ΐ»κΝΥGroupΒΡΗ≈ΡνΘ§ΟΩΗωGroupΑϋά®1ΗωRedis MasterΦΑ÷Ν…Ό1ΗωRedis SlaveΘ§’β «ΚΆTwemproxyΒΡ«χ±π÷°“ΜΓΘ’β―υΉωΒΡΚΟ¥Π «Θ§»γΙϊΒ±«ΑMaster”–Έ ΧβΘ§‘ρ‘ΥΈ§»Υ‘±Ω…Ά®ΙΐDashboard“Ή‘÷ζ Ϋ”«–ΜΜΒΫSlaveΘ§Εχ≤Μ–η“Σ–Γ–Ρ“μ“μΒΊ–όΗΡ≥Χ–ρ≈δ÷ΟΈΡΦΰΓΘ ΈΣ÷ß≥÷ ΐΨί»»«®“ΤΘ®Auto RebalanceΘ©Θ§≥ωΤΖΖΫ–όΗΡΝΥRedis Server‘¥¬κΘ§≤Δ≥Τ÷°ΈΣCodis ServerΓΘ Codis≤…”Ο‘Λœ»Ζ÷Τ§Θ®Pre-ShardingΘ©Μζ÷ΤΘ§ ¬œ»ΙφΕ®ΚΟΝΥΘ§Ζ÷≥…1024ΗωslotsΘ®“≤ΨΆ «ΥΒΘ§ΉνΕύΡή÷ß≥÷ΚσΕΥ1024ΗωCodis ServerΘ©Θ§’β–©¬Ζ”…–≈œΔ±Θ¥φ‘ΎZooKeeper÷–ΓΘ
ZooKeeperΜΙΈ§ΜΛCodis Server Group–≈œΔΘ§≤ΔΧαΙ©Ζ÷≤Φ ΫΥχΒ»ΖΰΈώΓΘ 3.2 –‘ΡήΕ‘±»≤β ‘CodisΡΩ«Α»‘±ΜΨΪ“φ«σΨΪΒΊΗΡΫχ÷–ΓΘΤδ–‘ΡήΘ§¥”Ήν≥θΒΡ±»Twemproxy¬ΐ20%Θ®Υδ»Μ’βΕ‘”ΎΡΎ¥φ–Ά”Π”ΟΕχ―‘Θ§≤Δ≤ΜΟςœ‘Θ©Θ§ΒΫœ÷‘Ύ‘Ε‘Ε≥§ΙΐTwemproxy–‘ΡήΘ®“ΜΕ®ΧθΦΰœ¬Θ©ΓΘ Έ“Ο«Ϋχ––ΝΥ≥Λ¥ο3Ηω‘¬ΒΡ≤β ‘ΓΘ≤β ‘Μυ”Ύredis-benchmarkΘ§Ζ÷±π’κΕ‘CodisΚΆTwemproxyΘ§≤β ‘Value≥ΛΕ»¥”16B~10MB ±ΒΡ–‘ΡήΚΆΈ»Ε®–‘Θ§≤ΔΫχ––Εύ¬÷≤β ‘ΓΘ “ΜΙ≤”–4Χ®ΈοάμΖΰΈώΤς≤Έ”κ≤β ‘Θ§Τδ÷–“ΜΧ®Ζ÷±π≤Ω πcodisΚΆtwemproxyΘ§ΝμΆβ»ΐΧ®Ζ÷±π≤Ω πcodis serverΚΆredis serverΘ§“‘–Έ≥…ΝΫΗωΦ·»ΚΓΘ ¥”≤β ‘ΫαΙϊά¥Ω¥Θ§ΨΆSet≤ΌΉςΕχ―‘Θ§‘ΎValue≥ΛΕ»<888B ±Θ§Codis–‘Ρή”≈‘Ϋ”≈”ΎTwemproxyΘ®’β‘Ύ“ΜΑψ“ΒΈώΒΡValue≥ΛΕ»ΖΕΈß÷°ΡΎΘ©ΓΘ
ΨΆGet≤ΌΉςΕχ―‘Θ§Codis–‘Ρή“Μ÷±”≈”ΎTwemproxyΓΘ
3.3 Ι”ΟΦΦ«…ΓΔΉΔ“β ¬œνCodisΜΙ”–ΚήΕύΚΟΆφΒΡΕΪΕΪΘ§¥” ΒΦ Ι”Οά¥Ω¥Θ§”––©ΒΊΖΫ“≤÷ΒΒΟΉΔ“βΓΘ 1Θ©ΈόΖλ«®“ΤTwemproxy≥ωΤΖΖΫΧυ–ΡΒΊΉΦ±ΗΝΥCodis-portΙΛΨΏΓΘΆ®ΙΐΥϋΘ§Ω…“‘ Β ±ΒΊΆ§≤Ϋ Twemproxy ΒΉœ¬ΒΡ Redis ΐΨίΒΫΡψΒΡ Codis Φ·»ΚΓΘΆ§≤ΫΆξ≥…ΚσΘ§÷Μ–η–όΗΡ“Μœ¬≥Χ–ρ≈δ÷ΟΈΡΦΰΘ§ΫΪ Twemproxy ΒΡΒΊ÷ΖΗΡ≥… Codis ΒΡΒΊ÷ΖΦ¥Ω…ΓΘ «ΒΡΘ§÷Μ–η“ΣΉω’βΟ¥ΕύΓΘ 2Θ©÷ß≥÷Java≥Χ–ρΒΡHACodisΧαΙ©“ΜΗωJavaΩΆΜßΕΥΘ§≤Δ≥Τ÷°ΈΣJodisΘ®ΟϊΉ÷ΚήΩαΘ§ «Α…ΘΩΘ©ΓΘ’β―υΘ§»γΙϊΒΞΗωCodis Proxyε¥ΒτΘ§JodisΉ‘Ε·ΖΔœ÷Θ§≤ΔΉ‘Ε·Ιφ±ή÷°Θ§ ΙΒϓ¸ώ≤Μ ή”ΑœλΘ®’φΒΡΚήΩαΘΓΘ©ΓΘ 3Θ©÷ß≥÷PipelinePipeline ΙΒΟΩΆΜßΕΥΩ…“‘ΖΔ≥ω“Μ≈ζ«κ«σΘ§≤Δ“Μ¥Έ–‘ΜώΒΟ’β≈ζ«κ«σΒΡΖΒΜΊΫαΙϊΓΘ’βΧα…ΐΝΥCodisΒΡœκœσΩ’ΦδΓΘ ¥” ΒΦ ≤β ‘ά¥Ω¥Θ§‘ΎValue≥ΛΕ»–Γ”Ύ888BΉ÷ΫΎ ±Θ§Set–‘Ρή―ΗΟΆΧα…ΐΘΜ
Get–‘Ρή“ύΗ¥»γ «ΓΘ
4Θ©Codis≤ΜΗΚ‘π÷ς¥”Ά§≤Ϋ“≤ΨΆ «ΥΒΘ§ CodisΫωΗΚ‘πΈ§ΜΛΒ±«ΑRedis ServerΝ–±μΘ§”…‘ΥΈ§»Υ‘±Ή‘ΦΚ»Ξ±Θ÷Λ÷ς¥” ΐΨίΒΡ“Μ÷¬–‘ΓΘ ’β «Έ“Ήν‘ό…ΆΒΡΒΊΖΫ÷°“ΜΓΘ’β―υΒΡΚΟ¥Π «Θ§ΟΜΑ―CodisΗψΒΟΡ«Ο¥÷ΊΓΘ“≤ «Έ“Ο«Η“”ΎΖ≈ ÷‘ΎœΏ…œΜΖΨ≥÷–…œœΏΒΡ‘≠“ρ÷°“ΜΓΘ 5Θ©Ε‘CodisΒΡΚσ–χΤΎ¥ΐΘΩΚΟΑ…Θ§¥÷«≥ΒΊΥΒΝΫΗωΓΘœΘΆϊCodis≤Μ“Σ±δΒΟΧΪ÷ΊΓΘΝμΆβΘ§Φ”pipeline≤Έ ΐΚσΘ§Value≥ΛΕ»»γΙϊΫœ¥σΘ§–‘ΡήΖ¥Εχ±»Twemproxy“ΣΒΆ“Μ–©Θ§œΘΆϊΡή”–ΗΡ…ΤΘ®Έ“Ο«Εύ¬÷―Ι≤βΫαΙϊΕΦ»γ¥ΥΘ©ΓΘ “ρΤΣΖυ”–œόΘ§‘¥¬κΖ÷Έω≤Μ‘Ύ¥Υ’ΙΩΣΓΘΝμΆβCodis‘¥¬κΓΔΧεœΒΫαΙΙΦΑFAQΘ§≤ΈΦϊ»γœ¬Ν¥Ϋ”ΘΚ https://github.com/wandoulabs/codis PSΘΚœΏ…œΈΡΒΒΒΡΩ…ΕΝ–‘Θ§“≤ «œύΒ±÷ΒΒΟ≥Τ‘όΒΡΒΊΖΫΓΘ“ΜΨδΜΑΘΚΚήΉΏ–ΡΘ§‘όΘΓ ΉνΚσΘ§Redis≥θ―ß’Ώ«κ≤ΈΩΦ’βΗωΝ¥Ϋ”ΘΚhttp://www.gamecbg.com/bc/db/redis/13852.htmlΘ§ΈΡΉ÷«≥œ‘“ΉΕ°Θ§Εχ«“±»Ϋœ»ΪΟφΓΘ
±ΨΈΡΒΟΒΫCodisΩΣΖΔΆ≈Ε”ΝθΤφΚΆΜΤΕΪ–ώΆ§―ßΒΡ¥σΝΠ–≠÷ζΘ§≤ΔΒΟΒΫTim Yangάœ ΠΒ»≈σ”―Ο«‘ΎΡΎ»ίΑ―ΩΊΖΫΟφΒΡ÷ΗΒΦΓΘ±ΨΈΡΙ≤Ά§Ής’ΏΈΣ’‘ΈΡΜΣΆ§―ßΘ§Υϊ÷ς“ΣΗΚ‘πCodisΦΑTwemproxyΒΡΕ‘±»≤β ‘ΓΘ‘Ύ¥Υ“Μ≤Δ–ΜΙΐΓΘ |