理想化的 Redis 集群
时间:2015-09-19 22:30 来源:linux.it.net.cn 作者:IT
Redis是其中一个吸引我的系统,一个持久性的,键值对存储内存操作高性能的平台。但是一个无主的redis集群仍然起着重要的作用。我们需要多系统去完成工作。同时,我们能够集合多种组件在一个容错和无主的集群里共同工作么?在这片文章中我将介绍梦幻般的redis。
一个豁达的关键是正确乐观的面对失败的系统。不需要过多的担心,需要一种去说那又怎样的能力。因此架构的设计是如此的重要。许多优秀的系统没有进一步成长的能力,我们应该做的是去使用其他的系统去共同分担工作。
Redis是其中一个吸引我的系统,一个持久性的,键值对存储内存操作高性能的平台。他是一个优秀的键值对数据库。我已经在使用了。即使AWS最近宣布开始支持ElasticCache的下级缓存。但是一个无主的redis集群仍然起着重要的作用。我们需要多系统去完成工作。同时,我们能够集合多种组件在一个容错和无主的集群里共同工作么?在这片文章中我将介绍梦幻般的redis。
一致哈希
构建一个存储数据集群的关键是有一个有效的数据存储和复制机制。我希望通过一个行之有效的方法来说明建造一个数据集群,在这个过程中你可以随意添加或移除一个Redis节点,同时保证你的数据仍然存在,而不会消失。这个方法称为一致哈希。
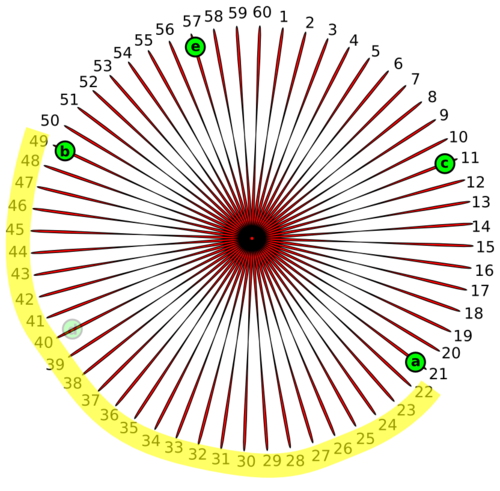
由于它不是一个很明显的概念,我将用一点时间来解释一下。为了理解一致哈希,你可以想像有一个函数f(x),对于给定的x总是返回一个1到60(为什么是60?你会知道的,但现在请等等)之间的结果,同样对于一个唯一的x,f(x)总是返回相同的结果。这些1到60的值按顺时针排成一个环。
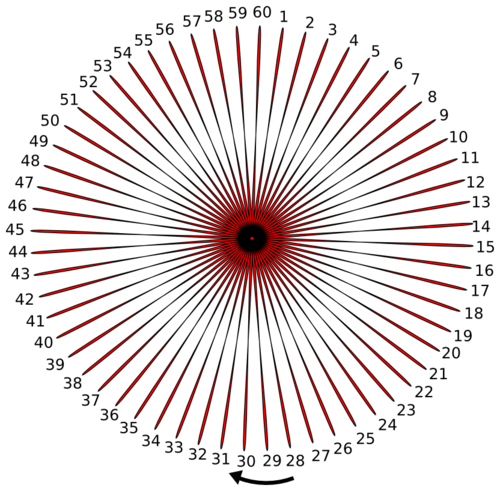
现在集群中的每个节点都需要一个唯一的名字,是吧?所以如果你将这个名字传递给f('<redis_node_name>'),它将返回一个1到60之间的数字(包括1和60),这个数字就是节点在环上的位置。当然它只是节点的逻辑(记录的)位置。这样,你获得一个节点,将它传给哈希函数,获得结果并将它放到环上。是不是很简单?这样每个节点都在环上有了它自己的位置。假设这里有5个Redis节点,名字分别为'a','b','c','d','e'。每个节点都传给哈希函数f(x)并且放到了环上。在这里f('a') = 21, f('b') = 49, f('c') = 11, f('d') = 40, f('e') = 57。一定记得这里位置是逻辑位置。
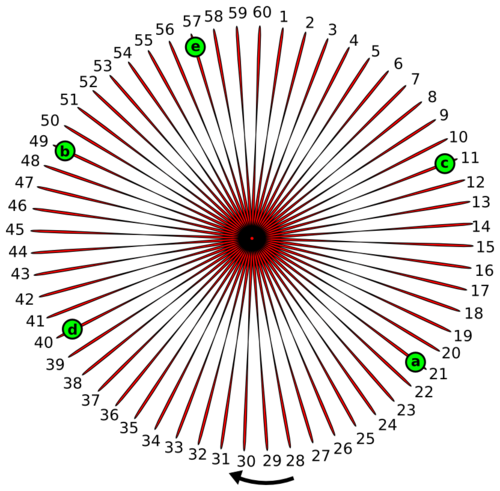
那么,我们为什么要将节点放在一个环上呢?将节点放到环上的目的是确定拥有哪些哈希空间。图中的节点'd'拥有的哈希空间就是f('a')到f('d')(其值为40)之间的部分,包括f('d'),即(21, 40]。也就是说节点'd'将拥有键x,如果f(x)的属于区间(21, 40]。比如键‘apple’,其值f('apple') = 35,那么键'apple'将被存在'd'节点。类似的,每个存储在集群上的键都会通过哈希函数,在环上按顺时针方向被恰当地存到最近的节点。
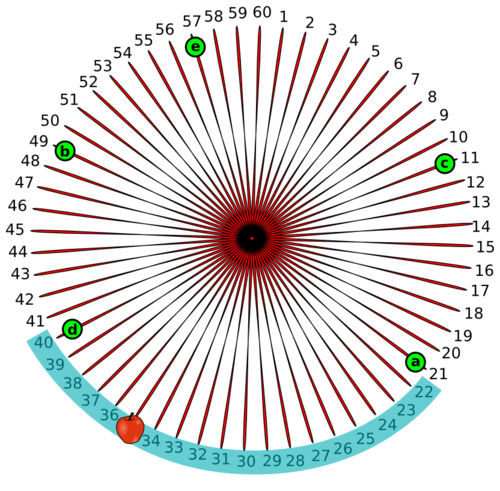
虽然一致哈希讲完了,但应知道,在多数情况下,这种类型的系统是伴随着高可用性而构建。为了满足数据的高可用性,需要根据一些因子进行复制, 这些因子称为复制因子。假设我们集群的复制因子为2,那么属于'd'节点的数据将会被复制到按顺时针方向与之相隔最近的'b'和'e'节点上。这就保证了如果从'd'节点获取数据失败,这些数据能够从'b'或'e'节点获取。
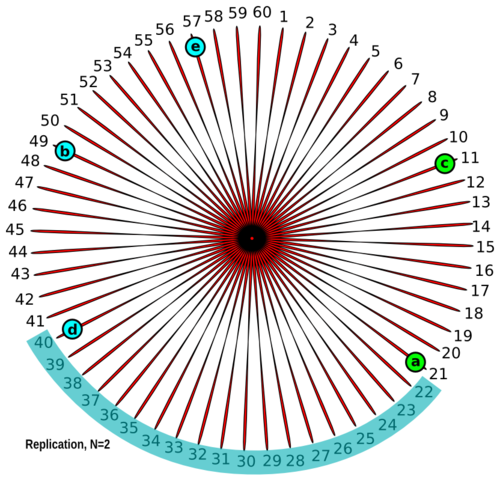
不仅仅是键使用一致哈希来存储,也很容易覆盖失败了的节点,并且复制因子依然完好有效。比如'd'节点失败了,'b'节点将获取'd'节点哈希空间的所有权,同时'd'节点的哈希空间能够很容易地复制到'c'节点。
坏事和好事
坏事就是目前这些讨论过的所有概念,复制(冗余),失效处理以及集群规模等,在Redis之外是不可行的。一致哈希仅仅描述了节点在哈希环上的映射以及那些哈希数据的所有权,尽管这样,它仍然是构建一个弹性可扩展系统的极好的开端。
好事就是,也有一些分立的其他工具在Redis集群上实现一致哈希,它们能提醒节点失效和新节点的加入。虽然这个功能不是一个工具的一部分,我们将看到如何用多个系统来使一个理想化的Redis集群运转起来。
Twemproxy aka Nutcracker
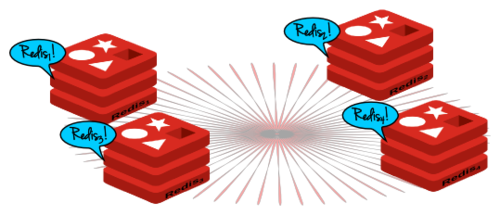
Twemproxy是一个开源工具,它是一个基于memcached和Redis协议的快速、轻量的代理。其本质就是,如果你有一些Redis服务器在运行,同时希望用这些服务器构建集群,你只需要将Twemproxy部署在这些服务器前端,并且让所有Redis流量都通过它。
Twemproxy除了能够代理Redis流量外,在它存储数据在Redis服务器时还能进行一致哈希。这就保证了数据被分布在基于一致哈希的多个不同Redis节点上。

但是Twemproxy并没有为Redis集群建立高可用性支持。最简单的办法是为集群中的每个节点都建立一个从(冗余)服务器,当主服务器失效时将从(冗余)服务器提升为主服务器。为Redis配置一个从服务器是非常简单的。

这种模型的缺点是非常明显的,它需要为Redis集群中的每个节点同时运行两个服务器。但是节点失效也是非常明显,并且更加危险,所以我们怎么知道这些问题并解决。
Gossip on Serf
Gossip是一个标准的机制,通过这个机制集群上的节点可以很清楚的了解成员的最新情况。这样子集群中的每个节点就很清楚集群中节点的变化,如节点的新增和节目的删除。
Serf通过实现Gossip机制提供这样的帮助。Serf是一个基于代理的机制,这个机制实现了Gossip的协议达到节点成员信息交换的目的。Serf是不断运行,除此之外,它还可以生成自定义的事件
现在拿我们的节点集群为例,如果每个节点上也有一个serf代理正在运行,那么节点与节点之间可以进行细节交换.因此,群集中的每个节点都能清楚知道其他节点的存在,也能清楚知道他们的状态。
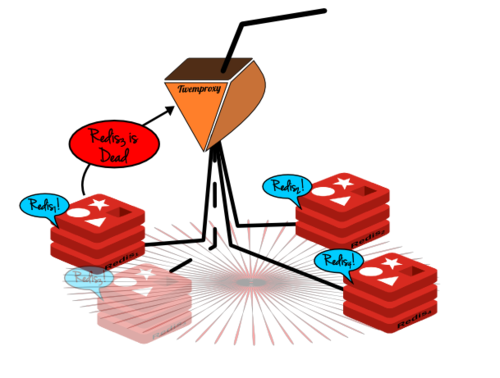
这还并不够,为了高可靠性我们还需要让twemproxy知道何时一个节点已经失效,这样的话它就可以据此修改它的配置。像前面提到的Serf,就可以做到这一点,它是基于一些gossip触发的事件,使用自定义动作实现的。因此只要集群中的一个Redis节点因为一些原因宕掉了,另一个节点就可以发送有成员意外掉线的消息给任何给定的端点,这个端点在我们的案例中也就是twemproxy服务器。
这还不是全部
现在我们有了Redis集群,基于一致性哈希环,相应的是用twemproxy存储数据(一致性哈希),还有Serf,它用gossip协议来检测Redis集群成员失效,并且向twemproxy发送失效消息;但是我们还没有建立起理想化的Redis集群。
消息侦听器
虽然Serf可以给任何端点发送成员离线或者成员上线消息。然而twemproxy却没有侦听此类事件的机制。因此我们需要自定义一个侦听器,就像Redis-Twenproxy代理,它需要做以下这些事情。
-
侦听Serf消息
-
更新nutcraker.yml 以反映新的拓扑
-
重启twemproxy
这个消息侦听器可以是一个小型的http服务器;它在收到一批POST数据的时候,为twemproxy做以上列表中的动作。需要记住的是,这种消息应该是一个原子操作;因为当一个节点失效(或者意外离线)的时候,所有能发消息的活动节点都将发送这个失效事件消息给侦听器;但是侦听器应该只响应一次。
数据复制
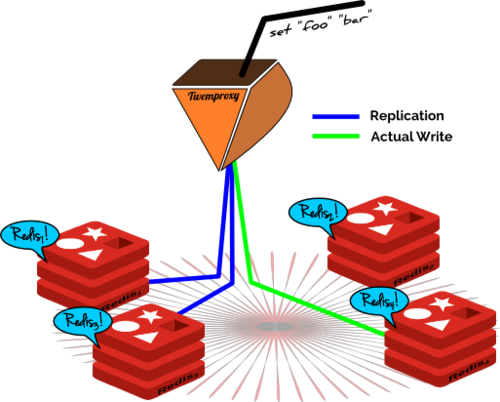
在上面的“一致哈希”中,我提到了Redis集群中的复制因素。同样它也不是Twemproxy的固有特性;Twemproxy只关心使用一致哈希存储一个拷贝。所以在我们追求理想化Redis集群的过程中,我们还需要给twemproxy或者redis自己创建这种复制的能力。
为了给Twenproxy创建复制能力,需要将复制因子作为一个配置项目,并且将数据保存在集群中相邻的redis节点(根据复制因子)。由于twemproxy知道节点的位置,所以这将给twemproxy增加一个很棒的功能。
由于twemproxy只不过是代理服务器,它的简单功能就是它强大的地方,为它创建复制管理功能将使它臃肿膨胀。
Redis 主从环
在思考这其中的工作机制的时候,我忽然想到,为什么不将每个节点设置成另一个节点的副本,或者说从节点,并由此而形成一个主从环呢?
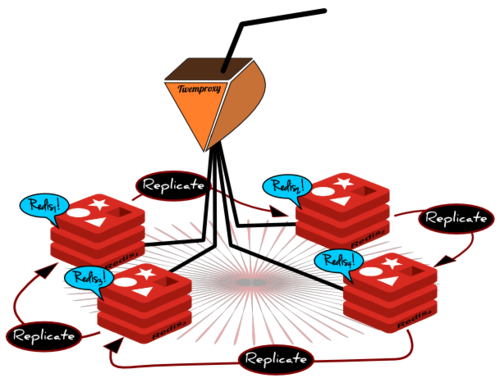
这样的话如果一个节点失效了,失效节点的数据在这个环上相邻的节点上仍然可以获得。而那个具有该数据副本的节点,将作为该节点的从节点,并提供保存数据副本的服务。这是一个既是主节点也是从节点的环。Serf仍像通常一样作为散布节点失效消息的代理。但是这一回,我们twenproxy上的的客户端,即侦听器,将不仅仅只更新twenproxy上的失效信息,还要调整redis服务器群集来适应这个变化。
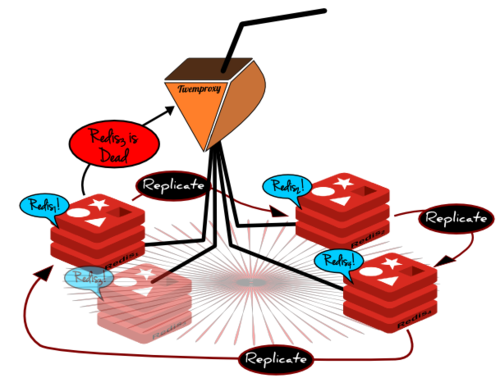
在这个环中有一个明显的,同样也是技术方面的缺陷。这个明显的缺陷是,这个环会坏掉,因为从节点的从节点无法判别哪一个是它的主节点的数据,哪一个是它的主节点的主节点的数据。这样的话就会循环的传送所有的数据。
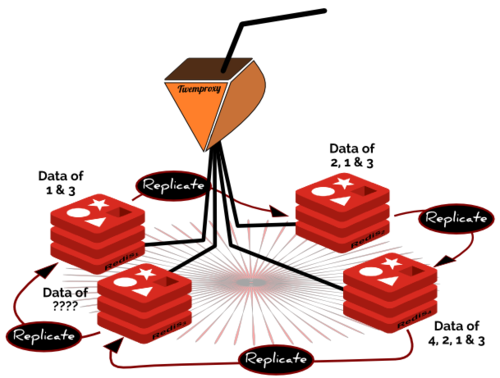
同样技术性的问题是,一旦redis将主节点的数据同步给从节点,它就会将从节点的数据擦除干净;这样就将曾经写到从节点的所有数据删除了。这种主从环显然不能实际应用,除非修改主从环的复制机制以适应我们的需求。这样的话每个从节点就不会将它的主节点的数据同步给它的从节点。要想实现这一点,必须的条件是每个节点都可以区分出自己的密钥空间,以及它的主节点的密钥空间;这样的话它就不会将主节点的数据传送给它的从节点。
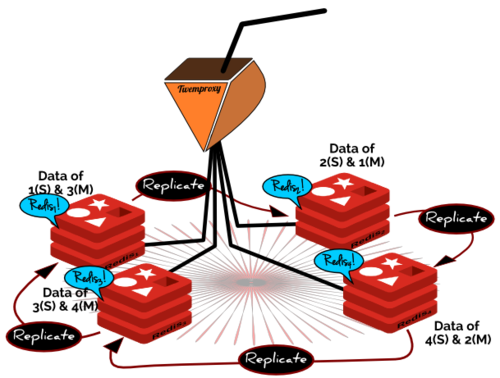
那么这样一来,当一个节点失效时,就需要执行四个动作。一,将失效节点的从节点作为它的密钥空间的所有者。二,将这些密钥散布给失效节点从节点的从节点,以便进行复制。三,将失效节点的从节点作为失效节点的主节点的从节点。最后,在新的拓扑上复位twemproxy。
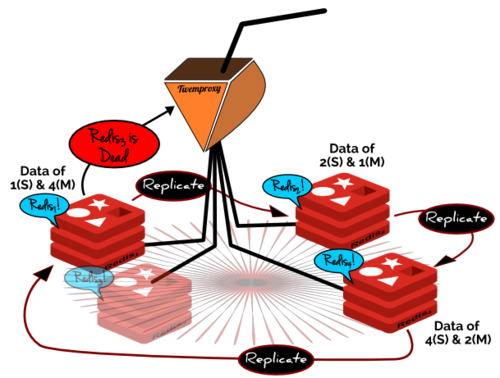
如何理想化?
事实上并没有这样的Redis集群,它可以具有一致性的哈希,高可靠性以及分区容错性。因此最后一幅图片描绘了一种理想化的Redis集群;但这并不是不可能的。接下来将罗列一下需要哪些条件才能使之成为一个实实在在的产品。
透明的Twenproxy
有必要部署一个Twenproxy,这会使得Hash散列中Redis各节点的位置都是透明的。每个Redis节点都可以知道自己以及其相邻节点的位置,这些信息对于节点的主从复制以及失败节点的修复是有必要的。自从Twenproxy开源之后,节点的位置信息可以被修改、以及扩展。
Redis的数据拥有权
这是比较困难的部分的,每个Redis节点都应该记录自身拥有的数据,以及哪些是主节点的数据。当前这样的隔离是不可能的。这也需要修改Redis的基础代码,这样节点才知道何时与从节点同步,什么时候不需要。
综上所述,我们的理想化的Redis集群变成现实需要修改这样的两个组件。一直以来,它们都是非常大的工业级别,使用在生产环境中。这已经值得任何人去实现(这个集群了)。
(责任编辑:IT)
| Redis是其中一个吸引我的系统,一个持久性的,键值对存储内存操作高性能的平台。但是一个无主的redis集群仍然起着重要的作用。我们需要多系统去完成工作。同时,我们能够集合多种组件在一个容错和无主的集群里共同工作么?在这片文章中我将介绍梦幻般的redis。 一个豁达的关键是正确乐观的面对失败的系统。不需要过多的担心,需要一种去说那又怎样的能力。因此架构的设计是如此的重要。许多优秀的系统没有进一步成长的能力,我们应该做的是去使用其他的系统去共同分担工作。 Redis是其中一个吸引我的系统,一个持久性的,键值对存储内存操作高性能的平台。他是一个优秀的键值对数据库。我已经在使用了。即使AWS最近宣布开始支持ElasticCache的下级缓存。但是一个无主的redis集群仍然起着重要的作用。我们需要多系统去完成工作。同时,我们能够集合多种组件在一个容错和无主的集群里共同工作么?在这片文章中我将介绍梦幻般的redis。 一致哈希 构建一个存储数据集群的关键是有一个有效的数据存储和复制机制。我希望通过一个行之有效的方法来说明建造一个数据集群,在这个过程中你可以随意添加或移除一个Redis节点,同时保证你的数据仍然存在,而不会消失。这个方法称为一致哈希。 由于它不是一个很明显的概念,我将用一点时间来解释一下。为了理解一致哈希,你可以想像有一个函数f(x),对于给定的x总是返回一个1到60(为什么是60?你会知道的,但现在请等等)之间的结果,同样对于一个唯一的x,f(x)总是返回相同的结果。这些1到60的值按顺时针排成一个环。
现在集群中的每个节点都需要一个唯一的名字,是吧?所以如果你将这个名字传递给f('<redis_node_name>'),它将返回一个1到60之间的数字(包括1和60),这个数字就是节点在环上的位置。当然它只是节点的逻辑(记录的)位置。这样,你获得一个节点,将它传给哈希函数,获得结果并将它放到环上。是不是很简单?这样每个节点都在环上有了它自己的位置。假设这里有5个Redis节点,名字分别为'a','b','c','d','e'。每个节点都传给哈希函数f(x)并且放到了环上。在这里f('a') = 21, f('b') = 49, f('c') = 11, f('d') = 40, f('e') = 57。一定记得这里位置是逻辑位置。
那么,我们为什么要将节点放在一个环上呢?将节点放到环上的目的是确定拥有哪些哈希空间。图中的节点'd'拥有的哈希空间就是f('a')到f('d')(其值为40)之间的部分,包括f('d'),即(21, 40]。也就是说节点'd'将拥有键x,如果f(x)的属于区间(21, 40]。比如键‘apple’,其值f('apple') = 35,那么键'apple'将被存在'd'节点。类似的,每个存储在集群上的键都会通过哈希函数,在环上按顺时针方向被恰当地存到最近的节点。
虽然一致哈希讲完了,但应知道,在多数情况下,这种类型的系统是伴随着高可用性而构建。为了满足数据的高可用性,需要根据一些因子进行复制, 这些因子称为复制因子。假设我们集群的复制因子为2,那么属于'd'节点的数据将会被复制到按顺时针方向与之相隔最近的'b'和'e'节点上。这就保证了如果从'd'节点获取数据失败,这些数据能够从'b'或'e'节点获取。
不仅仅是键使用一致哈希来存储,也很容易覆盖失败了的节点,并且复制因子依然完好有效。比如'd'节点失败了,'b'节点将获取'd'节点哈希空间的所有权,同时'd'节点的哈希空间能够很容易地复制到'c'节点。
坏事和好事 坏事就是目前这些讨论过的所有概念,复制(冗余),失效处理以及集群规模等,在Redis之外是不可行的。一致哈希仅仅描述了节点在哈希环上的映射以及那些哈希数据的所有权,尽管这样,它仍然是构建一个弹性可扩展系统的极好的开端。 好事就是,也有一些分立的其他工具在Redis集群上实现一致哈希,它们能提醒节点失效和新节点的加入。虽然这个功能不是一个工具的一部分,我们将看到如何用多个系统来使一个理想化的Redis集群运转起来。 Twemproxy aka Nutcracker Twemproxy是一个开源工具,它是一个基于memcached和Redis协议的快速、轻量的代理。其本质就是,如果你有一些Redis服务器在运行,同时希望用这些服务器构建集群,你只需要将Twemproxy部署在这些服务器前端,并且让所有Redis流量都通过它。 Twemproxy除了能够代理Redis流量外,在它存储数据在Redis服务器时还能进行一致哈希。这就保证了数据被分布在基于一致哈希的多个不同Redis节点上。
但是Twemproxy并没有为Redis集群建立高可用性支持。最简单的办法是为集群中的每个节点都建立一个从(冗余)服务器,当主服务器失效时将从(冗余)服务器提升为主服务器。为Redis配置一个从服务器是非常简单的。
这种模型的缺点是非常明显的,它需要为Redis集群中的每个节点同时运行两个服务器。但是节点失效也是非常明显,并且更加危险,所以我们怎么知道这些问题并解决。 Gossip on Serf Gossip是一个标准的机制,通过这个机制集群上的节点可以很清楚的了解成员的最新情况。这样子集群中的每个节点就很清楚集群中节点的变化,如节点的新增和节目的删除。 Serf通过实现Gossip机制提供这样的帮助。Serf是一个基于代理的机制,这个机制实现了Gossip的协议达到节点成员信息交换的目的。Serf是不断运行,除此之外,它还可以生成自定义的事件 现在拿我们的节点集群为例,如果每个节点上也有一个serf代理正在运行,那么节点与节点之间可以进行细节交换.因此,群集中的每个节点都能清楚知道其他节点的存在,也能清楚知道他们的状态。
这还并不够,为了高可靠性我们还需要让twemproxy知道何时一个节点已经失效,这样的话它就可以据此修改它的配置。像前面提到的Serf,就可以做到这一点,它是基于一些gossip触发的事件,使用自定义动作实现的。因此只要集群中的一个Redis节点因为一些原因宕掉了,另一个节点就可以发送有成员意外掉线的消息给任何给定的端点,这个端点在我们的案例中也就是twemproxy服务器。
这还不是全部 现在我们有了Redis集群,基于一致性哈希环,相应的是用twemproxy存储数据(一致性哈希),还有Serf,它用gossip协议来检测Redis集群成员失效,并且向twemproxy发送失效消息;但是我们还没有建立起理想化的Redis集群。 消息侦听器 虽然Serf可以给任何端点发送成员离线或者成员上线消息。然而twemproxy却没有侦听此类事件的机制。因此我们需要自定义一个侦听器,就像Redis-Twenproxy代理,它需要做以下这些事情。
这个消息侦听器可以是一个小型的http服务器;它在收到一批POST数据的时候,为twemproxy做以上列表中的动作。需要记住的是,这种消息应该是一个原子操作;因为当一个节点失效(或者意外离线)的时候,所有能发消息的活动节点都将发送这个失效事件消息给侦听器;但是侦听器应该只响应一次。 数据复制 在上面的“一致哈希”中,我提到了Redis集群中的复制因素。同样它也不是Twemproxy的固有特性;Twemproxy只关心使用一致哈希存储一个拷贝。所以在我们追求理想化Redis集群的过程中,我们还需要给twemproxy或者redis自己创建这种复制的能力。 为了给Twenproxy创建复制能力,需要将复制因子作为一个配置项目,并且将数据保存在集群中相邻的redis节点(根据复制因子)。由于twemproxy知道节点的位置,所以这将给twemproxy增加一个很棒的功能。
由于twemproxy只不过是代理服务器,它的简单功能就是它强大的地方,为它创建复制管理功能将使它臃肿膨胀。 Redis 主从环 在思考这其中的工作机制的时候,我忽然想到,为什么不将每个节点设置成另一个节点的副本,或者说从节点,并由此而形成一个主从环呢?
这样的话如果一个节点失效了,失效节点的数据在这个环上相邻的节点上仍然可以获得。而那个具有该数据副本的节点,将作为该节点的从节点,并提供保存数据副本的服务。这是一个既是主节点也是从节点的环。Serf仍像通常一样作为散布节点失效消息的代理。但是这一回,我们twenproxy上的的客户端,即侦听器,将不仅仅只更新twenproxy上的失效信息,还要调整redis服务器群集来适应这个变化。
在这个环中有一个明显的,同样也是技术方面的缺陷。这个明显的缺陷是,这个环会坏掉,因为从节点的从节点无法判别哪一个是它的主节点的数据,哪一个是它的主节点的主节点的数据。这样的话就会循环的传送所有的数据。
同样技术性的问题是,一旦redis将主节点的数据同步给从节点,它就会将从节点的数据擦除干净;这样就将曾经写到从节点的所有数据删除了。这种主从环显然不能实际应用,除非修改主从环的复制机制以适应我们的需求。这样的话每个从节点就不会将它的主节点的数据同步给它的从节点。要想实现这一点,必须的条件是每个节点都可以区分出自己的密钥空间,以及它的主节点的密钥空间;这样的话它就不会将主节点的数据传送给它的从节点。
那么这样一来,当一个节点失效时,就需要执行四个动作。一,将失效节点的从节点作为它的密钥空间的所有者。二,将这些密钥散布给失效节点从节点的从节点,以便进行复制。三,将失效节点的从节点作为失效节点的主节点的从节点。最后,在新的拓扑上复位twemproxy。
如何理想化? 事实上并没有这样的Redis集群,它可以具有一致性的哈希,高可靠性以及分区容错性。因此最后一幅图片描绘了一种理想化的Redis集群;但这并不是不可能的。接下来将罗列一下需要哪些条件才能使之成为一个实实在在的产品。 透明的Twenproxy 有必要部署一个Twenproxy,这会使得Hash散列中Redis各节点的位置都是透明的。每个Redis节点都可以知道自己以及其相邻节点的位置,这些信息对于节点的主从复制以及失败节点的修复是有必要的。自从Twenproxy开源之后,节点的位置信息可以被修改、以及扩展。 Redis的数据拥有权 这是比较困难的部分的,每个Redis节点都应该记录自身拥有的数据,以及哪些是主节点的数据。当前这样的隔离是不可能的。这也需要修改Redis的基础代码,这样节点才知道何时与从节点同步,什么时候不需要。 综上所述,我们的理想化的Redis集群变成现实需要修改这样的两个组件。一直以来,它们都是非常大的工业级别,使用在生产环境中。这已经值得任何人去实现(这个集群了)。 (责任编辑:IT) |